An Information-Theoretic Framework for Robust Large Language Model Editing
阿里IBKE:用“信息瓶颈”给大模型做脑部微创,知识编辑SOTA

大模型(LLM)虽然博学,但它们也有一个致命弱点:知识会过时,且容易产生幻觉。当我们需要修正模型中的错误(例如“现任英国首相是谁”)时,重新训练整个模型无异于为了换个灯泡而重建整栋大楼——成本高昂且效率低下。
ArXiv URL:http://arxiv.org/abs/2512.16227v1
因此,模型编辑(Model Editing)技术应运而生,它旨在像手术刀一样精准地修改模型内部的特定知识,而不影响其他无关能力。然而,现有的编辑技术往往陷入两难:要么“改得太死”,无法泛化(只改了“A是B”,却回答不出“B是什么”);要么“改得太宽”,破坏了模型的其他知识(灾难性遗忘)。
为了解决这一难题,来自阿里巴巴、华东师范大学和合肥工业大学的研究团队提出了一种基于信息瓶颈(Information Bottleneck, IB)理论的全新框架,并推出了信息瓶颈知识编辑器(Information Bottleneck Knowledge Editor, IBKE)。该方法在多个基准测试中实现了SOTA(State-of-the-Art)性能,为大模型的“脑部微创手术”提供了一套理论完备且效果显著的方案。
核心痛点:泛化与局部性的博弈
模型编辑的核心挑战在于平衡两个相互冲突的目标:
-
泛化性(Generality):编辑不仅要修正特定的提示词(Prompt),还要能处理语义相关的变体。例如,将“埃菲尔铁塔在柏林”修正为“巴黎”后,模型面对“埃菲尔铁塔的位置在哪里?”也应回答“巴黎”。
-
局部性(Locality):编辑不能波及无关知识。修改埃菲尔铁塔的位置,不应影响模型对“自由女神像”位置的认知。
现有的方法往往难以兼顾二者,导致编辑后的模型要么“举一反三”能力差,要么出现“连带损伤”。
破局之道:引入信息瓶颈理论
该研究的创新之处在于,它将模型编辑重新构建为一个信息约束优化问题。研究团队引入了经典的信息瓶颈(Information Bottleneck, IB)原理。
IB原理的核心思想是在压缩输入信息的同时,最大化保留与目标输出相关的信息。用数学公式表示,即寻找一个潜在表示 $Z$,使得目标函数最大化:
\[\max I(Z;Y) - \beta I(Z;X)\]其中,$I(\cdot;\cdot)$ 表示互信息,$\beta$ 是一个平衡系数。
-
$I(Z;Y)$ 鼓励 $Z$ 包含足够的信息来预测目标 $Y$(保证编辑的有效性和泛化性)。
-
$-\beta I(Z;X)$ 鼓励 $Z$ 尽可能压缩输入 $X$,丢弃与编辑目标无关的冗余信息(保证编辑的局部性,减少对无关知识的干扰)。
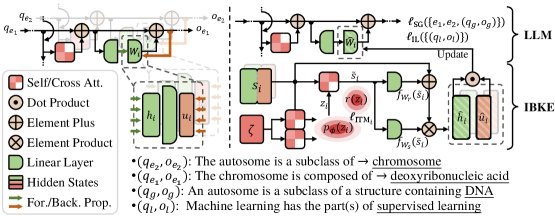
IBKE:基于梯度的超网络架构
基于上述理论,研究团队设计了 IBKE。如上图所示,这是一个基于超网络(Hypernetwork)的架构。它的工作流程非常精妙:
-
提取编辑信号:对于一个编辑请求(例如“将A修正为B”),IBKE首先计算模型权重的梯度分解,这代表了“权重应该怎么变”。
-
注入潜在表示:IBKE引入了一个可学习的序列作为潜在表示 $Z$。这个 $Z$ 通过交叉注意力机制(Cross-Attention)与梯度信号融合。
-
信息压缩与筛选:通过IB机制,模型被迫从梯度信号中提取出“最本质”的编辑意图,过滤掉那些可能导致过拟合或干扰无关知识的噪声。
-
生成权重更新:最后,经过处理的信号被送入超网络,预测出最终的模型权重更新量 $\Delta W$。
这种设计使得IBKE能够精准地“识别”出哪些神经元需要调整,以及调整的幅度,从而实现“手术级”的精准编辑。
实验结果:全面SOTA
研究团队在 GPT2-XL (1.5B)、GPT-J (6B) 以及 Qwen3 (1.5B/8B) 等多个大模型架构上进行了广泛验证。测试数据集涵盖了 ZSRE、CounterFact、MQuAKE 和 UniEdit 四大主流基准。
1. 泛化性与局部性的完美平衡
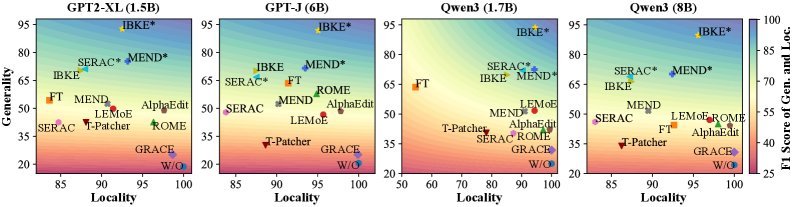
上图展示了不同编辑方法在泛化性(纵轴)和局部性(横轴)上的权衡。可以看出,IBKE(红色星号) 几乎在所有模型上都位于右上角,这意味着它在保持极高局部性(不坏事)的同时,显著提升了泛化性(做对事)。
2. 语义表示的可视化
为了探究IBKE到底学到了什么,研究人员对潜在表示进行了可视化分析。
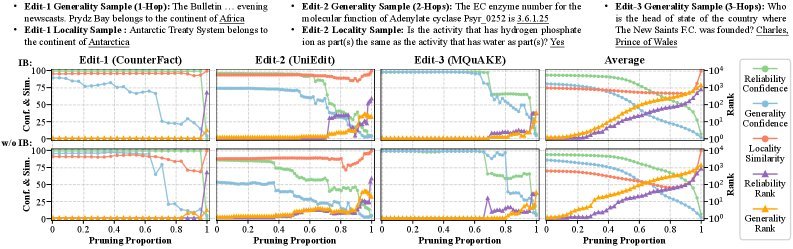
t-SNE可视化结果显示,引入IB机制后(右图),不同类型的编辑任务(不同颜色)在潜在空间中形成了边界更清晰、分离度更好的簇。这说明IB机制成功地帮助模型剔除了噪声,学到了更本质的编辑语义。
3. 关键参数的影响
研究还发现,IB公式中的平衡系数 $\beta$ 起到了关键作用。
-
较大的 $\beta$ 值会增强泛化性(压缩更多,只留核心),但如果过大可能会降低对特定样本的拟合度。
-
实验表明,选择 $\beta=0.1$ 或 $\beta=1$ 可以在大多数任务中取得最佳平衡。
总结
这篇论文为大模型知识编辑领域带来了一个理论严谨的新范式。通过引入信息瓶颈理论,IBKE 成功解决了传统编辑方法中“泛化”与“局部”难以兼得的痛点。
这项技术不仅让大模型能够更低成本地更新知识,也为构建更可靠、更安全、且能持续进化的AI系统奠定了基础。未来,随着这种“微创手术”技术的成熟,我们或许再也不用因为一点小错误就重训整个大模型了。