Batch Prompting Suppresses Overthinking Reasoning Under Constraint: How Batch Prompting Suppresses Overthinking in Reasoning Models
-
ArXiv URL: http://arxiv.org/abs/2511.04108v1
-
作者: Saurabh Srivastava; Wenmo Qiu
-
发布机构: George Mason University; University of Toronto
TL;DR
本文发现,批处理提示 (Batch Prompting) 不仅能摊销推理成本,还能作为一种有效的推理时正则化器,抑制大型推理模型(LRM)的“过度思考”行为,从而在保持精度的同时大幅减少推理Token消耗。
关键定义
本文的核心见解是基于对现有概念的应用和新解释,主要涉及以下术语:
- 批处理提示 (Batch Prompting):一种推理技术,将多个独立的用户查询(问题)组合成一个单一的、更长的提示(Prompt),然后一次性发送给语言模型进行处理,模型会生成一个包含所有查询答案的聚合响应。
- 过度思考现象 (Overthinking Phenomenon):指大型推理模型(Large Reasoning Models, LRMs)在处理问题时,即使是简单问题,也倾向于生成过长、冗长甚至不必要的冗余推理步骤(如思维链,Chain-of-Thought)的倾向,这会浪费大量的计算资源和时间。
- 大型推理模型 (Large Reasoning Models, LRMs):指那些为执行多步推理任务(如数学、编程、逻辑规划)而优化的语言模型。它们通常通过生成明确的中间推理步骤来换取更高的准确性,但这也导致了“过度思考”的问题。
- 软正则化 (Soft Regularization):本文提出的核心概念,指批处理提示通过非显式的方式对模型的行为施加约束。当模型在有限的上下文窗口和注意力带宽内同时处理多个问题时,它被迫更有效地分配其“认知资源”,从而自然地抑制了对单个问题的过度分析,效果类似于一种正则化。
相关工作
当前,顶尖的大型推理模型(LRMs)通过生成明确的思维链 (Chain-of-Thought, CoT) 在数学、编码和逻辑规划等多步推理任务上取得了SOTA性能。然而,这种详尽的推理方式也带来了一个显著的瓶颈:过度思考。模型即使在面对简单问题时也会消耗过多的Token和时间,生成冗长、不必要的推理步骤,这使得它们在对延迟和成本敏感的应用场景中不切实际。
先前的工作主要通过两种方式解决此问题:
- 训练时干预:例如自训练方法,教模型判断何时停止推理。
- 模型内部干预:例如激活工程(activation-steering),通过修改模型内部的隐藏状态来抑制过多的Token生成。
这些方法的共同局限性在于,它们需要访问模型的权重或内部激活状态,这对于通过API访问的闭源模型(如OpenAI的模型)是不可行的。因此,本文旨在解决一个关键问题:能否在不接触模型内部结构、完全在推理时通过黑箱操作来减少模型的“过度思考”?
本文方法
本文提出,最初为摊销成本而设计的批处理提示(Batch Prompting)技术,本身就能作为一种隐式的正则化器,有效抑制LRM的过度思考。
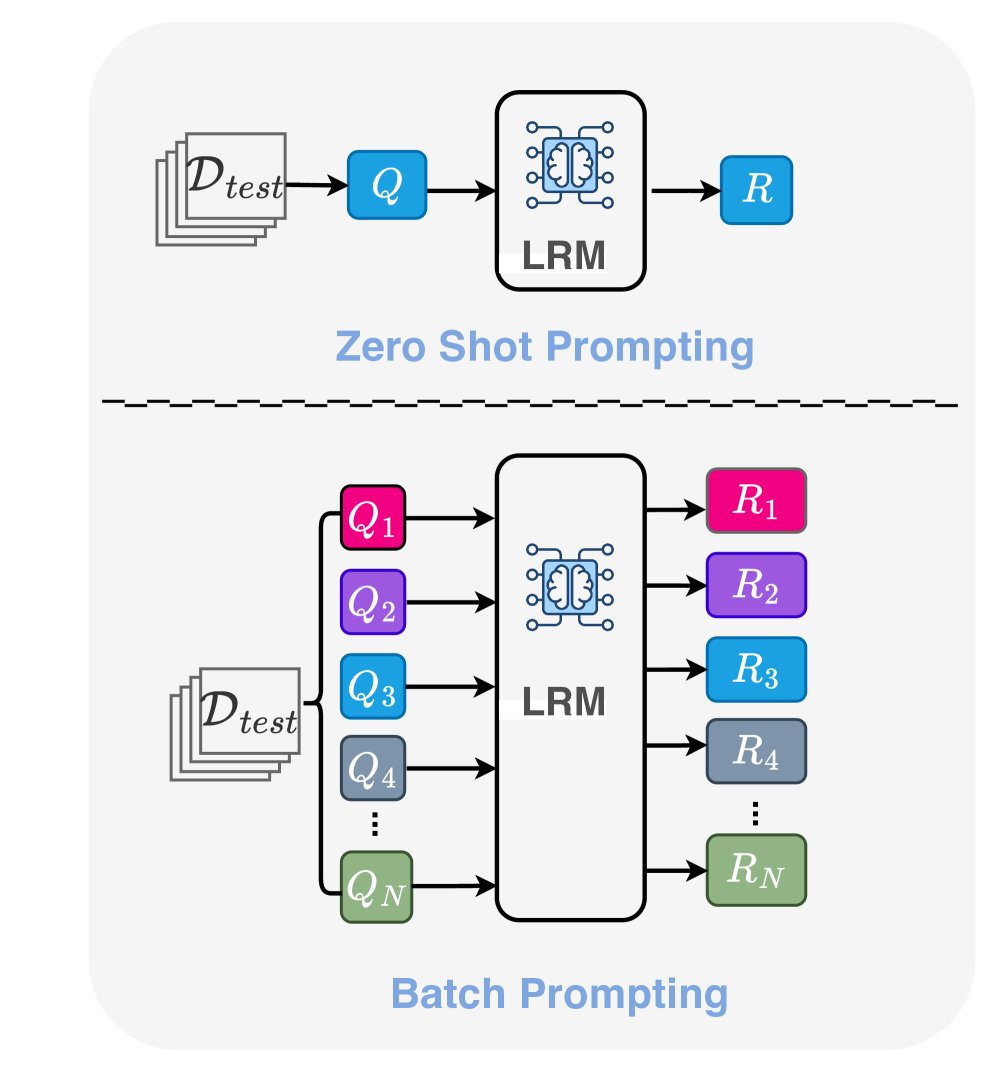
上图展示了该方法的核心机制。将一批测试查询 $Q=[Q_{1},Q_{2},\ldots,Q_{N}]$ 组合成一个单一的提示,发送给模型 $\mathcal{M}$ 进行联合响应生成。最终得到的输出 $R=[R_{1},R_{2},\ldots,R_{N}]$ 共享一个共同的推理上下文,从而有效地在批次内的所有项目间分配注意力和计算资源。
创新点:作为效率工具
批处理提示通过摊销固定的提示开销来降低平均成本。对于单个查询 $q$,总Token成本为:
\[C(q)=T_{\text{fix}}+T_{q}+T_{a}\]其中 $T_{\text{fix}}$ 是固定的指令开销,$T_{q}$ 是查询Token数,$T_{a}$ 是回答Token数。
当将 $b$ 个查询批处理时,总成本变为:
\[C_{\text{batch}}=T_{\text{fix}}+\sum_{i=1}^{b}(T_{q_{i}}+T_{a_{i}})\]因此,每个查询的有效成本降低为:
\[\frac{C_{\text{batch}}}{b}=\frac{T_{\text{fix}}}{b}+\frac{1}{b}\sum_{i=1}^{b}(T_{q_{i}}+T_{a_{i}})\]随着批次大小 $b$ 的增加,固定的提示开销 $T_{\text{fix}}$ 被摊销,从而显著降低了平均每个查询的成本。
创新点:作为正则化器
本文最核心的贡献在于揭示了批处理提示的正则化效应。当多个问题被打包到同一个上下文中时,模型有限的注意力带宽和计算资源必须在所有问题之间进行分配。这种机制就像一个软性的计算约束,促使模型避免在任何单个问题上投入过多的“思考”时间,尤其是对于简单问题。
这种行为可以用以下方式形式化地表达。令 $R(q)$ 表示模型对查询 $q$ 的推理轨迹(例如思维链的长度)。在单查询模式下,模型可能会过度生成:
\[\mid R(q) \mid _{\text{single}}\gg \mid R(s) \mid \_{\text{optimal}}\]而在批处理提示下,每个查询的平均推理长度被有效缩短:
\[\mathbb{E}[ \mid R(q) \mid _{\text{batch}}] < \mathbb{E}[ \mid R(q) \mid _{\text{single}}]\]这种隐式的约束鼓励模型生成更简洁、更果断的答案,从而抑制“过度思考”。
值得注意的是,这种约束是“软性”的,模型仍能自适应地为批次内更难的问题分配更多的推理步骤,而在简单问题上保持简洁,从而在效率和性能之间取得平衡。
实验结论
本文在13个涵盖算术推理、问答、结构化提取等多种类型的基准上,对DeepSeek-R1和OpenAI-o1两款模型进行了实验。
关键实验结果
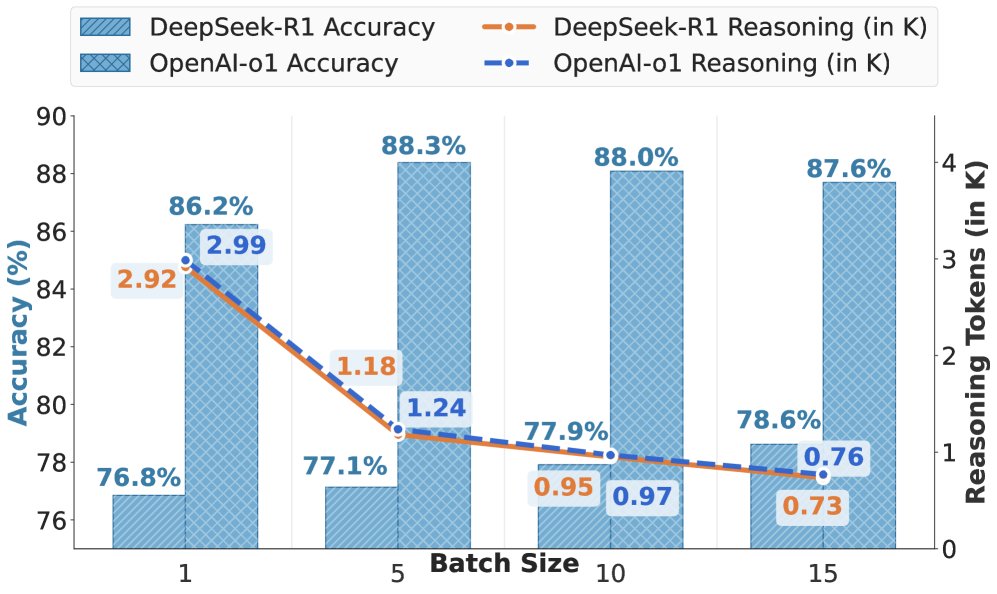
实验结果有力地证实了本文的假设。如下图所示,随着批次大小的增加:
- 准确率保持稳定甚至略有提升:在13个数据集上,平均准确率在批次大小从1增加到15时,从86.2%微升至87.7%。这表明批处理不仅没有损害性能,有时甚至通过上下文中的相似样本提供了归纳信号,从而增强了模型的推理模式。
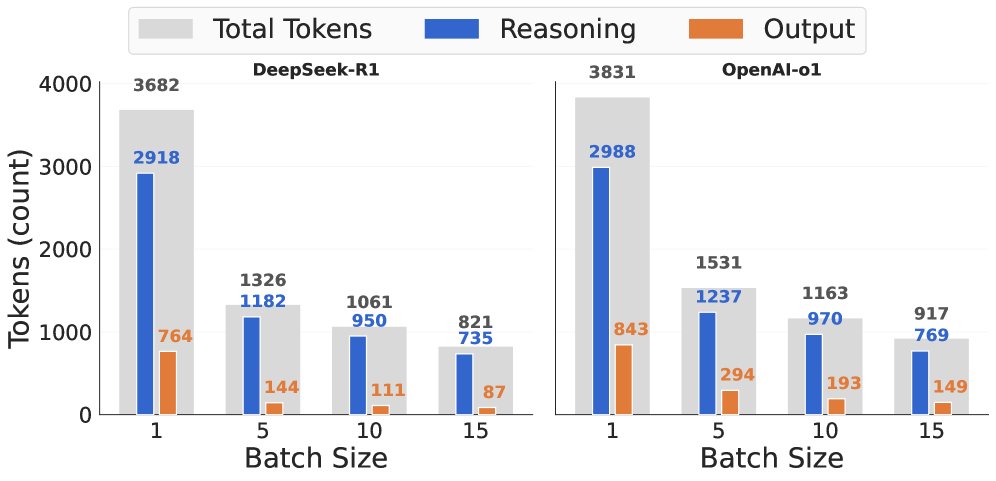
- 推理Token大幅减少:平均推理Token数量从2987.8个急剧下降到768.7个,减少了约74%(近4倍),而输出Token数量基本保持不变。这直接证明了批处理提示有效抑制了模型的内部推理过程。
下表展示了在不同任务类型上,准确率(Acc)、推理Token(RTok)和输出Token(OTok)随批次大小(BS)变化的详细数据。
| 模型 | 任务类型 | 指标 | BS=1 | BS=5 | BS=15 |
|---|---|---|---|---|---|
| DeepSeek-R1 | 算术 | Acc | 39.0 | 44.5 | 44.8 |
| RTok | 2397.6 | 1342.3 | 913.3 | ||
| OTok | 422.3 | 200.7 | 100.9 | ||
| QA | Acc | 87.0 | 88.0 | 88.3 | |
| RTok | 3388.9 | 1500.5 | 1184.2 | ||
| OTok | 1076.6 | 280.9 | 163.6 | ||
| 结构化 | Acc | 58.7 | 62.3 | 64.4 | |
| RTok | 2779.6 | 1290.4 | 1147.2 | ||
| OTok | 787.0 | 258.9 | 185.0 | ||
| OpenAI-o1 | 算术 | Acc | 59.8 | 61.5 | 62.3 |
| RTok | 2011.6 | 682.3 | 473.0 | ||
| OTok | 308.2 | 110.1 | 59.4 | ||
| QA | Acc | 88.5 | 90.0 | 89.8 | |
| RTok | 3290.8 | 1269.4 | 823.1 | ||
| OTok | 1101.4 | 309.8 | 158.4 | ||
| 结构化 | Acc | 78.4 | 80.3 | 79.9 | |
| RTok | 2588.6 | 890.7 | 619.6 | ||
| OTok | 1189.6 | 312.3 | 196.9 |
行为分析与结论
- 抑制过度思考:在简单的字母连接任务上,单个查询可能导致模型无限循环;而将同样的问题放入批处理中,模型则能快速、正确地解决所有问题。
- 减少犹豫性语言:在Game of 24任务中,批处理将模型自言自语式的修正(如使用“wait” token)的频率从21次减少到仅1次,表明模型变得更加果断。
- 促进归纳泛化:模型能从批次内的其他样本中学习并泛化正确的输出格式,这种“集体效应”使得后续问题的解决变得更加容易和一致。
- 优于显式指令:与直接命令模型“少思考”或“使用更少Token”(这些指令往往被模型忽略或曲解)相比,批处理作为一种隐式约束更加鲁棒和有效。
总结
本文证明了批处理提示是一种简单、通用且无需修改模型的推理时优化技术。它不仅是一种提升系统吞吐量的工程技巧,更是一种能改善模型行为的“认知约束”,通过抑制过度思考,在不牺牲(甚至提升)准确率的前提下,显著提高了大型推理模型的效率和可靠性。
尽管结果喜人,本文也承认其局限性,例如在处理高度异构的查询时,极端大的批次可能影响性能;同时,该方法缺乏对Token预算的显式控制。