Beyond Gemini-3-Pro: Revisiting LLM Routing and Aggregation at Scale
超越Gemini-3-Pro:开源模型“组团”打怪,成本仅47%!

开篇:单体模型真的越大越好吗?
ArXiv URL:http://arxiv.org/abs/2601.01330v1
在通往AGI(通用人工智能)的道路上,我们似乎陷入了一种“军备竞赛”:模型参数越来越大,训练数据越来越多。Google 最新的 Gemini-3-Pro 刚刚树立了性能新标杆,仿佛在告诉大家:“大,就是正义。”
但是,这真的是唯一的出路吗?
如果我们将十个“臭皮匠”级别的开源模型组合起来,能不能战胜一个“诸葛亮”级别的闭源巨无霸?今天我们要解读的这篇论文《Beyond Gemini-3-Pro: Revisiting LLM Routing and Aggregation at Scale》,给出了一个令人兴奋的答案:不仅能,而且成本还不到一半!
研究团队提出了一种名为 JiSi(集思) 的全新框架,通过巧妙地调度和聚合开源模型,在九大基准测试中全面超越了 Gemini-3-Pro,同时将推理成本降低了 53.23%。这不仅是一次技术上的胜利,更像是一场开源社区对闭源巨头的“集体逆袭”。
核心痛点:为什么现有的“拼凑”方案不好用?
将多个大模型组合起来使用(即多模型协作),并不是什么新鲜事。通常有两种流派:
-
路由(Routing):像交通指挥官一样,把问题分发给最擅长这个领域的模型。
-
聚合(Aggregation):像议会投票一样,让多个模型一起回答,然后综合大家的意见。
然而,作者发现现有的方案存在三个致命瓶颈:
-
路由太“肤浅”:目前的路由器大多只看文本相似度。比如你问“苹果怎么卖”,它可能分不清你是在问水果还是问股票,因为它只看字面意思,不懂问题的难度和深层语义。
-
聚合太“死板”:不管什么任务,都用同一套聚合器。这就像用同一个厨师去应对川菜、粤菜和法餐,显然不够专业。
-
两者“各自为战”:路由和聚合往往是割裂的。要么全部分发,要么全部聚合,缺乏灵活的切换机制。
JiSi 的破局之道:极简主义的胜利
为了解决上述问题,JiSi 提出了一个极简但高效的“路由-聚合”拓扑结构。它的核心思想可以用三个创新点来概括:
1. 混合路由:不仅看问题,还要看答案
传统的路由只看用户的 Query(问题)。JiSi 引入了 Query-Response Mixed Routing(查询-响应混合路由)。
它不仅分析你的问题,还会参考模型生成的“响应嵌入”(Response Embeddings)。这就像面试官不仅看你的简历(Query),还要看你现场试答的表现(Response),从而更精准地判断哪个模型真正懂这个问题,同时也捕捉到了问题的难度信息。
2. 动态选人:谁行谁上
针对聚合器“死板”的问题,JiSi 设计了 Support-Set-based Aggregator Selection(基于支持集的聚合器选择)。
系统会根据当前的查询,从预先构建的“嵌入库”(Embedding Bank)中检索类似的历史问题,看看在这些问题上哪个聚合器表现最好。这相当于在做菜前,先查一下点评网站,看哪位厨师最擅长做这道菜,从而实现动态的“看菜下碟”。
3. 智能开关:该独奏时独奏,该合唱时合唱
这是 JiSi 最聪明的地方——Adaptive Routing-Aggregation Switch(自适应路由-聚合开关)。
并不是所有问题都需要大家一起回答。如果一个模型非常有把握(得分很高),那就让它直接回答(路由模式),省钱又快;如果大家都没把握,或者意见不统一,那就启动聚合模式,综合大家的智慧。这种机制有效过滤了噪声,防止了“三个和尚没水喝”的情况。
实验结果:开源军团的逆袭
为了验证效果,研究团队找来了 10个开源大模型(包括 DeepSeek-V3, Qwen3, Llama 等),在 AIME、MMLU-Pro、LiveCodeBench 等 9个高难度基准 上进行了测试。
结果令人咋舌(见下图):
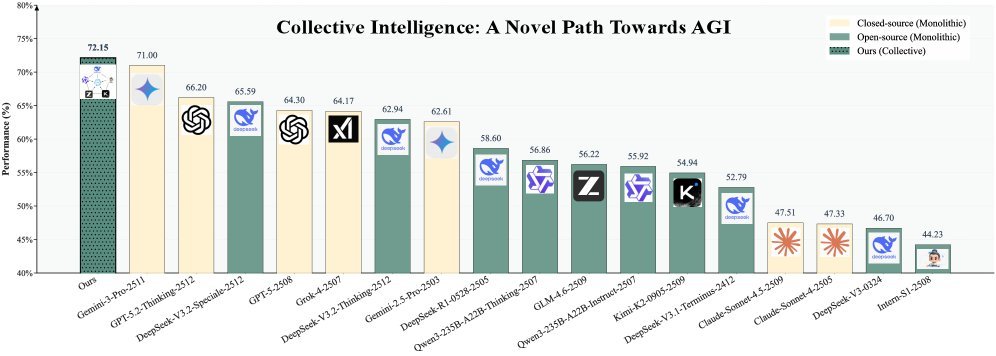
-
全面超越:JiSi 在综合榜单上击败了所有单体模型,包括最强的闭源模型 Gemini-3-Pro。
-
成本暴降:相比 Gemini-3-Pro,JiSi 的平均性能提升了 +1.15,但成本却只有对方的 47%。
-
拒绝“偏科”:无论是在推理、编程还是通用对话领域,JiSi 都展现出了极强的适应性。
总结与展望
JiSi 的成功向我们展示了 群体智能(Collective Intelligence) 的巨大潜力。它证明了我们不需要一味地追求单个模型的无限变大,通过合理的协作机制,开源小模型的组合完全可以战胜闭源大模型。
正如论文标题暗示的那样,这或许是通往 AGI 的一条新路径:不再是造一个全知全能的神,而是建立一个各司其职、配合默契的精英团队。
对于开发者而言,JiSi 提供了一个无需训练(Training-free)、即插即用的框架。这意味着你手里的开源模型,可能比你想象的更强大。