RAG新革命:VisionRAG告别OCR,每页17个向量实现SOTA文档检索

还在为RAG系统处理PDF、财报时丢失表格和布局信息而头疼吗?传统的光学字符识别(Optical Character Recognition, OCR)方法会把复杂的文档“拍平”成纯文本,丢失关键的视觉结构。而新兴的视觉检索模型(如ColPali)虽然强大,但每页动辄上千个向量的存储和计算开销,让大规模部署成为奢望。
ArXiv URL:http://arxiv.org/abs/2511.21121v1
现在,来自Inception AI的研究者们提出了一个两全其美的方案:VisionRAG。它完全抛弃了OCR,直接将文档页面当做图像处理,每页仅需存储17-27个向量,便在金融文档检索任务上取得了顶尖性能。这究竟是如何做到的?
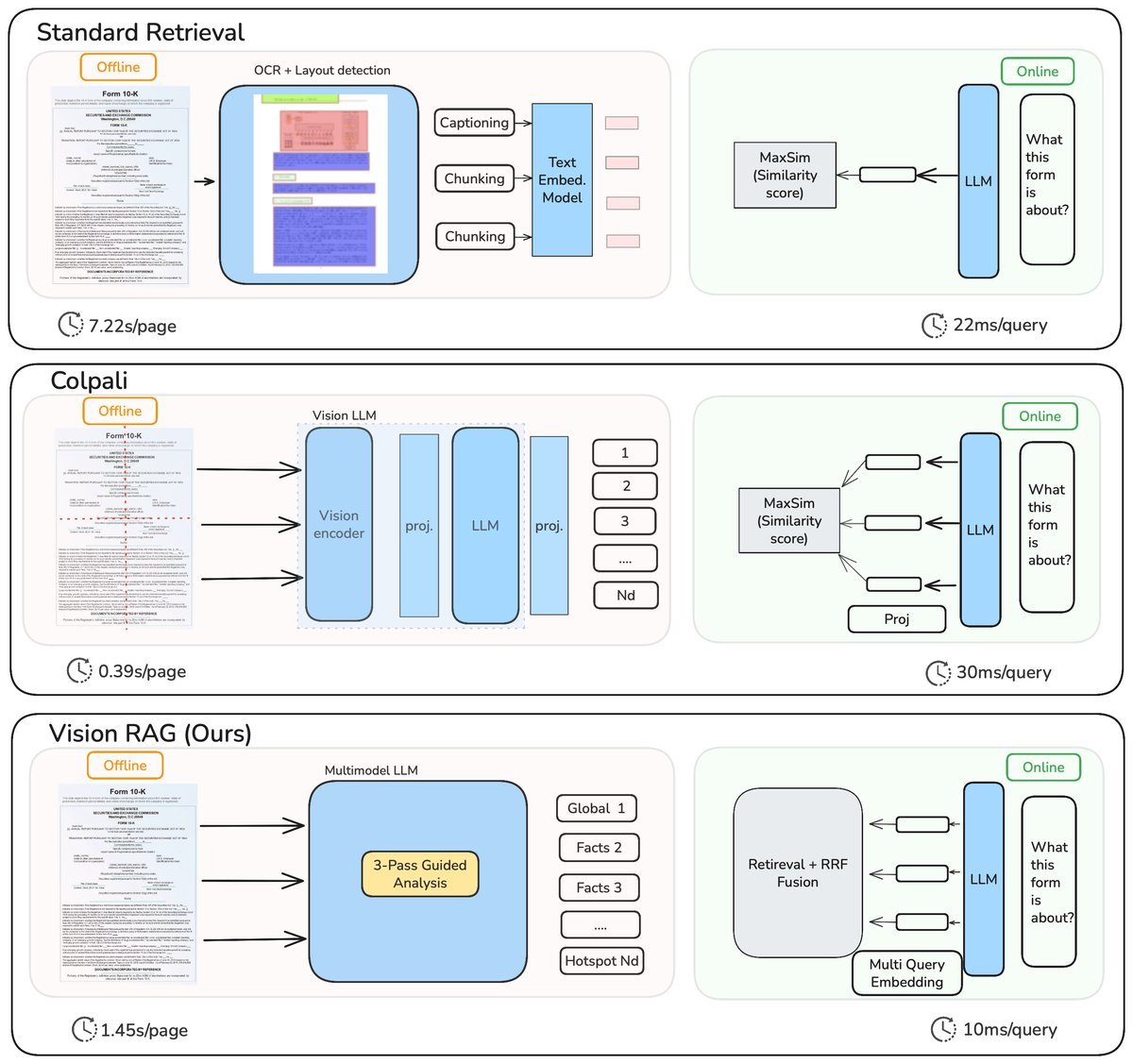
告别OCR,拥抱“三遍扫描金字塔索引”
VisionRAG的核心思想非常巧妙:它不直接对图像进行暴力切块(Patching),而是采用一种名为三遍扫描金字塔索引(3-Pass Pyramid Indexing)的框架,用一个多模态大模型(如GPT-4o)对页面图像进行“智能阅读”,提取出不同粒度的语义信息。
这个过程可以分为两步:
-
页面语义提取:对于每个页面图像,VisionRAG会借助VLM生成四种互补的文本信息:
-
全局摘要 (Global Summary):概括整个页面的核心内容。
-
章节标题 (Section Headers):识别并抽取出页面的结构化标题。
-
关键事实 (Facts):提取页面中的原子化信息,如具体的数字和声明。
-
视觉热点 (Visual Hotspots):描述表格、图表或被特意强调的视觉区域内容。
-
-
构建金字塔索引:VisionRAG为上述四种信息分别创建独立的轻量级向量索引。这就像为一份地图同时准备了国家、省份、城市、街道四个不同层级的索引,可以满足不同粒度的查询需求。
这种“先理解、再索引”的策略,避免了生成海量的Patch向量,从而实现了极高的效率。
架构对比:轻量级选手 vs. 重量级冠军
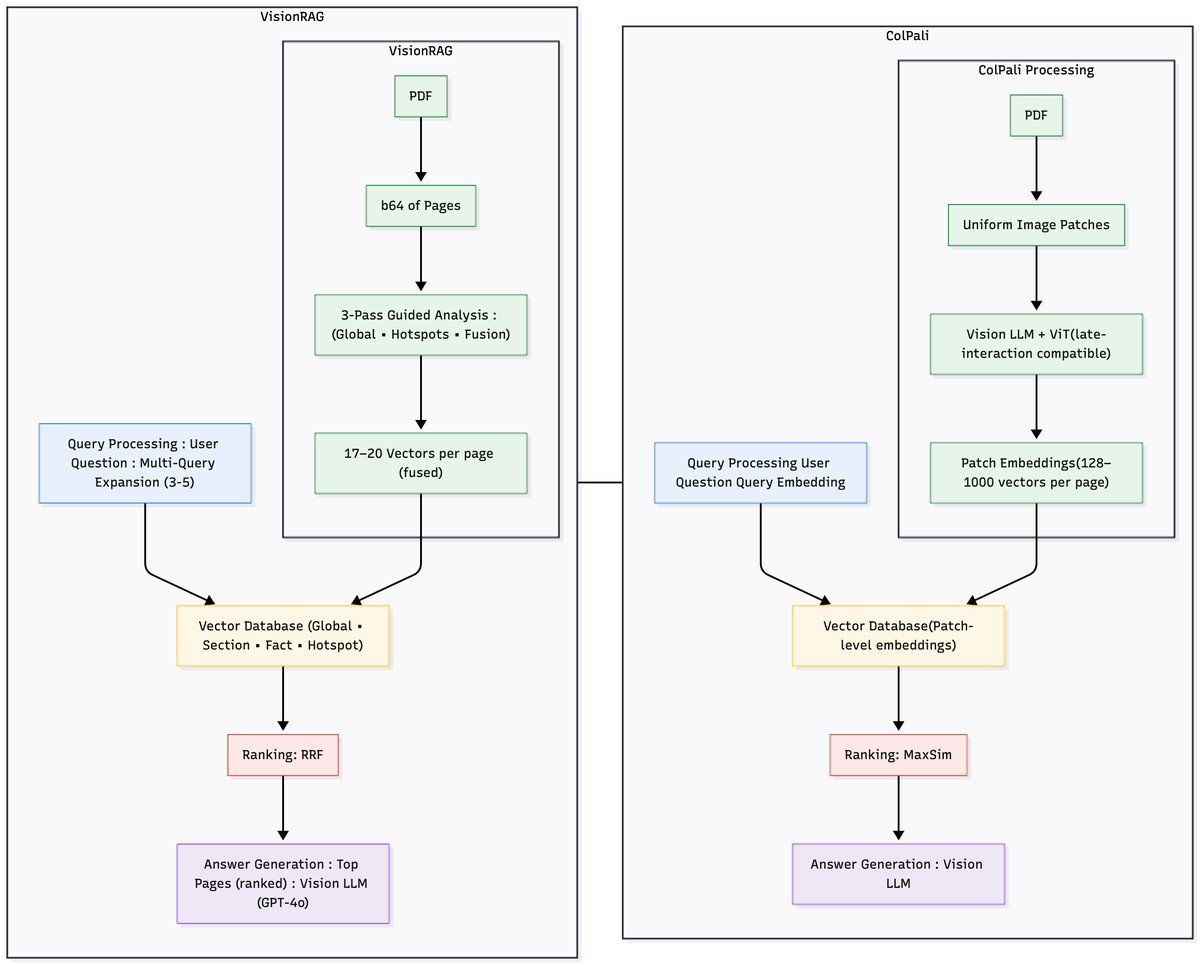
为了更直观地理解VisionRAG的优势,我们可以将它与基于Patch的重量级选手ColPali进行对比。
-
ColPali:采用后期交互(Late Interaction)模型,将页面分割成一个密集的网格(如32x32),为每个网格生成一个Patch向量,总计每页1024个向量。检索时,查询向量需要与所有Patch向量进行复杂的相似度计算。这保证了高精度,但也带来了巨大的存储和计算成本。
-
VisionRAG:采用显式语义融合(Explicit Semantic Fusion)策略。它生成的四类语义信息,总共只需要17到27个向量。在查询时,系统会同时在四个索引中进行检索,并使用倒数排序融合(Reciprocal Rank Fusion, RRF)算法将各路结果智能地合并,得到最终的排序。
简单来说,ColPali是“暴力出奇迹”,而VisionRAG则是“四两拨千斤”。
惊人的效率:存储开销降低超6倍
数字最能说明问题。VisionRAG的效率优势是压倒性的。
研究显示,处理一个包含100万页文档的语料库:
-
ColPali(完整版)需要约 250 GB 的存储空间。
-
VisionRAG(使用1536维向量)仅需 41 GB。
存储开销直接降低了超过6倍!这意味着VisionRAG可以更轻松地部署在标准硬件上,大大降低了企业应用RAG的门槛。
在查询延迟方面,VisionRAG同样表现出色。实验表明,在CPU基础设施上,其端到端响应时间比ColPali快一个数量级,真正实现了低延迟检索。
性能不妥协:金融问答任务表现优异
效率提升是否以牺牲性能为代价?答案是否定的。
该研究在两大权威金融文档问答基准测试 FinanceBench 和 TAT-DQA 上验证了VisionRAG的性能。
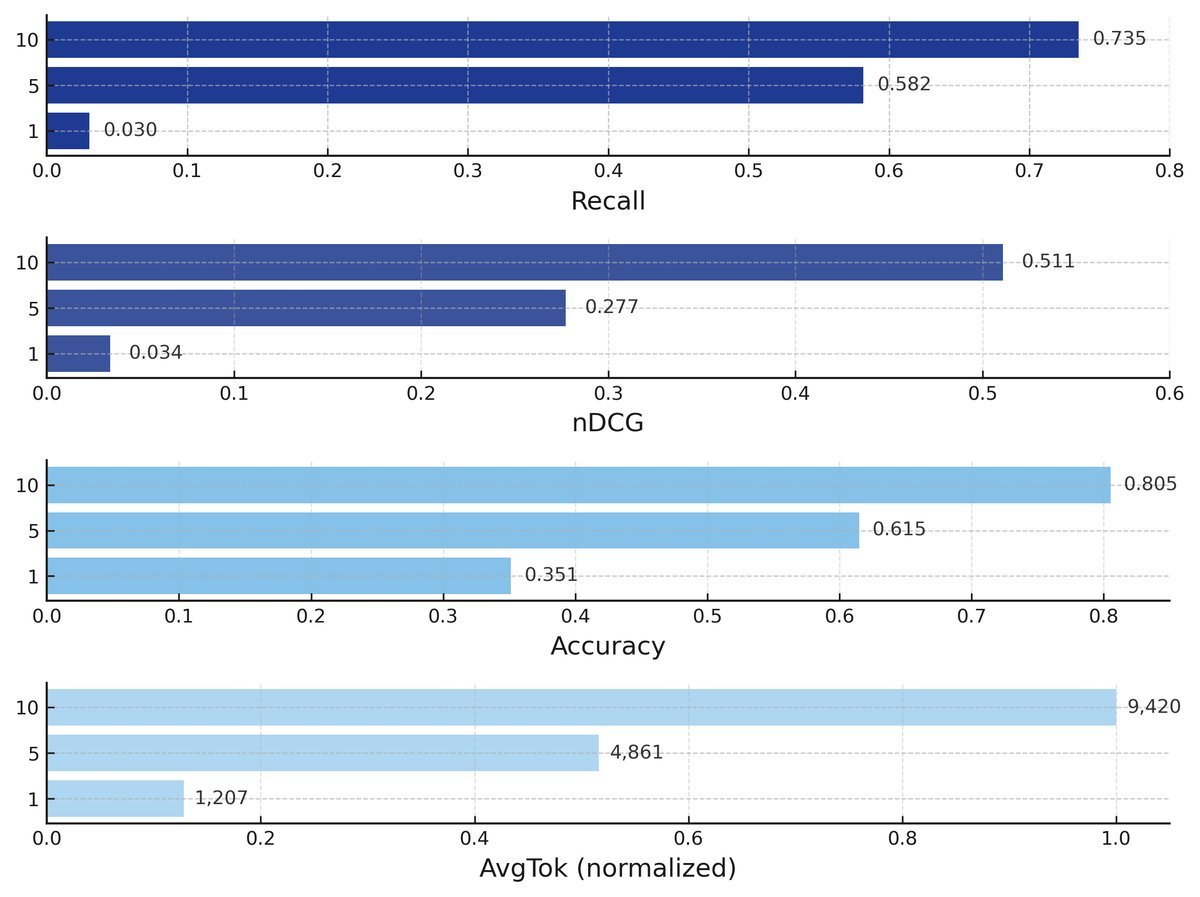
在FinanceBench上,当检索10个最相关页面($K=10$)时,VisionRAG的端到端问答准确率达到了 80.51%,这是一个非常强的结果。
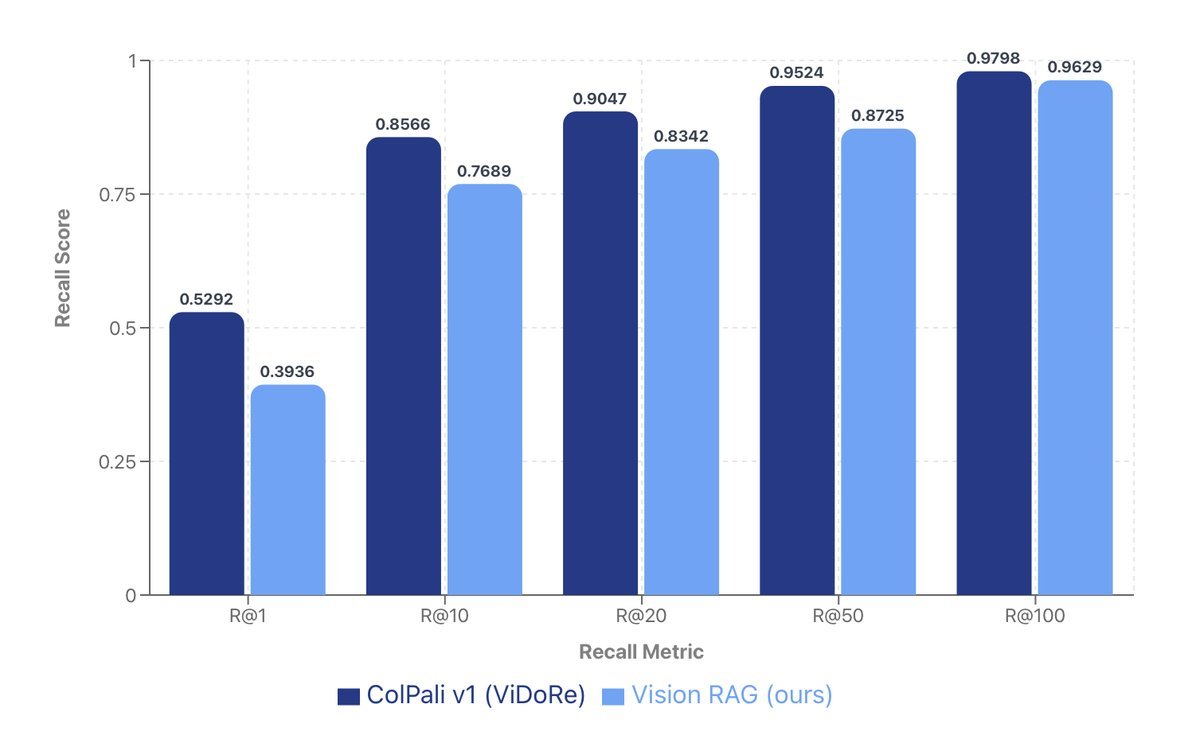
在TAT-DQA上,VisionRAG的召回率@100(Recall@100)达到了 96.29%,与ColPali等顶尖视觉检索模型的性能(97.98%)非常接近,证明了它在复杂文档中定位答案相关信息的能力。
更重要的是,VisionRAG的设计是模型无关(Model-Agnostic)的。研究者们用GPT-4o、GPT-5甚至开源的InstructBLIP模型进行了测试,发现系统性能差异很小($\leq 8\%$)。这证明了其金字塔索引和融合策略的鲁棒性,不依赖于某个特定的超强VLM。
总结
VisionRAG的出现,为处理富视觉文档的RAG系统提供了一条全新的、兼具高效率与高性能的实践路径。
通过创新的三遍扫描金字塔索引框架,它巧妙地绕开了OCR的种种弊端和Patch-based方法的计算瓶颈,实现了:
-
无需OCR:直接处理图像,保留完整视觉信息。
-
极致高效:每页仅需17-27个向量,存储和查询成本极低。
-
性能强大:在多个金融问答基准上取得SOTA或接近SOTA的性能。
-
模型无关:架构鲁棒,可灵活适配不同的VLM。
对于希望在企业内部署能够处理复杂财报、合同、报告的RAG应用的开发者来说,VisionRAG无疑提供了一个极具吸引力的、可落地的解决方案。它证明了,在通往更强大多模态AI的道路上,聪明的架构设计有时比单纯堆砌算力更重要。