Beyond the Black Box: Theory and Mechanism of Large Language Models
告别“黑盒”炼丹:人大&厦大联合发布,LLM全生命周期理论图谱

当 DeepSeek、ChatGPT 和 Claude 这样的模型在我们的屏幕上流畅地生成代码、撰写诗歌甚至进行复杂推理时,我们往往会惊叹于人工智能的“魔力”。但作为一个技术从业者,你是否曾在某个深夜看着训练 Loss 曲线发呆,心中涌起一种深深的无力感:我们真的理解这些庞然大物内部发生了什么吗?
ArXiv URL:http://arxiv.org/abs/2601.02907v1
目前的 AI 领域存在一个巨大的悖论:工程上的成功是史诗级的,但理论上的理解却处于婴儿期。 我们知道 怎么 调整参数能让模型变强,却很难从数学上解释 为什么。这种“知其然不知其所以然”的状态,让 LLM 的开发常常被戏称为“炼丹”。
为了打破这一僵局,来自中国人民大学和厦门大学的研究团队发布了一篇重磅综述《Beyond the Black Box: Theory and Mechanism of Large Language Models》。这不仅仅是一篇文献汇总,更是一张试图将 LLM 从“工程启发”推向“严谨科学”的路线图。
本文将带你深入这篇论文的核心,揭秘 LLM 全生命周期背后的理论机制。
拒绝盲目:全生命周期的理论视角
面对万亿参数的复杂系统,盲人摸象是行不通的。该论文最核心的贡献在于提出了一套基于生命周期的统一分类法。
研究者并没有将理论碎片化地罗列,而是将其映射到了 LLM 开发的六个标准阶段:
-
数据准备(Data Preparation)
-
模型准备(Model Preparation)
-
训练(Training)
-
对齐(Alignment)
-
推理(Inference)
-
评估(Evaluation)
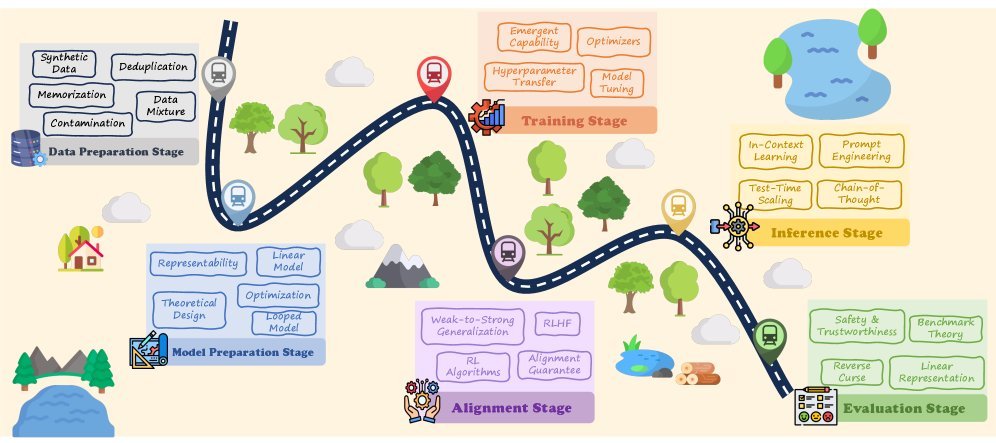
这六个阶段构成了 LLM 的“一生”。让我们重点剖析其中最关键的两个阶段——数据与模型,看看理论界是如何解释那些我们习以为常的工程现象的。
数据准备:不仅仅是“喂得更多”
数据是 LLM 的灵魂。如果你认为数据准备只是简单的“爬取”和“清洗”,那就大错特错了。理论研究表明,这里面隐藏着深刻的数学原理。
1. 数据混合的艺术(Data Mixture)
为什么混合了代码、书籍和网页数据的模型,比单一来源的模型更聪明?
这不仅仅是经验之谈。理论上,这涉及到双层优化(Bilevel Optimization)问题。
-
外部循环:优化数据源的采样权重,以最小化验证集损失。
-
内部循环:在给定权重下找到最优模型参数。
论文提到了像 DoReMi 这样的方法,它利用极小极大(min-max)优化,旨在最小化所有数据域中最差情况的性能,从而强迫模型学习到更鲁棒的特征。这解释了为什么“不偏科”的数据配比能带来泛化能力的飞跃。
2. 去重的深层逻辑
去重(Deduplication)是标准操作,但你是否想过,为什么去重能提升性能?
早期的理解是去重能减少计算量。但 RefinedWeb 和 D4 等研究揭示了更深层的机制:信息密度。
通过语义匹配(不仅仅是哈希匹配)去除冗余,实际上是在提升训练数据的“信噪比”。更有趣的是 SoftDedup 的发现:硬性删除可能会导致信息丢失,而“软性重加权”可能是更优的理论解。
3. 合成数据的陷阱:模型崩溃
随着高质量人类数据的耗尽,合成数据(Synthetic Data)成为了救命稻草。但这引发了一个可怕的理论推测:模型崩溃(Model Collapse)。
如果模型不断使用自己生成的数据进行训练,会发生什么?理论研究表明,这会导致分布的退化。
-
“替换”工作流(丢弃旧数据,只用新合成数据):必然导致崩溃。
-
“累积”工作流(将合成数据与真实数据混合):这是避免崩溃的关键。
数学上的估算显示,为了维持稳定性,合成数据的比例必须严格控制在小于真实数据的范围内。
模型准备:架构的边界在哪里?
选好了数据,接下来是设计“容器”。Transformer 是一统天下的架构,但它真的无所不能吗?
1. 表达能力的边界
我们常听说神经网络可以逼近任何函数(通用近似定理),但在有限的深度和精度下,Transformer 也是有极限的。
-
电路复杂性:研究表明,深度为 $O(1)$ 且精度为对数级的 Transformer,只能解决 $TC^{0}$ 类问题。这意味着某些看似简单的逻辑任务,如果模型层数不够,它是从原理上就“学不会”的。
-
幻觉的数学根源:通过通信复杂性理论分析,研究者发现 Transformer 层在处理大定义域的函数组合时存在瓶颈,这被认为是模型产生幻觉(Hallucination)的理论根源之一——当模型无法精确组合信息时,它就开始“编造”。
2. 优化动力学:河谷损失景观
你是否好奇过,为什么现在的 LLM 训练都流行用 Warmup-Stable-Decay (WSD) 的学习率调度策略?
论文中提到的“河谷损失景观”(River Valley Loss Landscape)假设给出了极其形象的解释:
-
Stable 阶段:高学习率让参数在“山坡”之间剧烈震荡,但这恰恰能让模型在谷底的“河流”方向上快速前进。
-
Decay 阶段:当学习率下降,参数不再震荡,而是迅速沉降到谷底的最优解。
这种理论视角,让我们对调参(Tuning)不再是盲目试错,而是有了物理图像的指引。
结语:从炼丹术到化学
正如爱因斯坦所言:“科学的宏伟目标是:从最少数量的假设或公理出发,通过逻辑演绎覆盖最大数量的经验事实。”
目前的 LLM 领域,正如 1905 年之前的物理学,充满了各种神奇的实验现象(涌现、Scaling Laws、上下文学习),但缺乏统一的理论大厦。这篇综述不仅是对现有知识的梳理,更是一个信号:AI 正在从依赖工程直觉的“炼丹术”,向着拥有严谨数理基础的“化学”转变。
对于每一位 AI 从业者来说,关注这些理论进展,或许就是你在下一次模型训练中,突破瓶颈的关键钥匙。