Broken Words, Broken Performance: Effect of Tokenization on Performance of LLMs
单词破碎,性能崩塌?揭秘Tokenization如何悄悄“降智”大模型

在训练大语言模型(LLM)的万里长征中,第一步往往最容易被忽视,却可能埋下致命的隐患。
ArXiv URL:http://arxiv.org/abs/2512.21933v1
你是否遇到过这种情况:明明是一个很简单的单词,模型却给出了莫名其妙的回答?或者只是把输入文本中的某个词换了个同义词,模型的智商瞬间就“上线”了?
这篇来自塔塔咨询服务公司(TCS Research)的最新研究《Broken Words, Broken Performance》告诉我们:问题可能出在“切词”(Tokenization)上。 当一个完整的自然单词被粗暴地切分成多个碎片 Token 时,模型的性能可能会遭遇断崖式下跌。
本文将带你深入探究这一现象背后的机制,并介绍一种全新的“惩罚函数”来量化这种负面影响。
破碎的单词,破碎的理解
在大模型眼里,世界不是由“单词”组成的,而是由 Token 组成的。由于词表大小有限(例如 Llama-3 的词表约为 128k),许多长难词或生僻词无法作为一个整体被收录,必须被切分成多个子词(Subwords)。
举个例子,\(unhappiness\)(不快乐)。
-
人类视角:\(un-\)(前缀)+ \(happy\)(词根)+ \(-ness\)(后缀)。这种切分保留了词法结构,语义清晰。
-
LLM 视角(如 Phi-3.5):可能会被切分为 \(unh\) + \(app\) + \(iness\)。
请注意,\(unh\) 和 \(app\) 这些碎片 Token 已经完全破坏了原词的语义结构。研究人员假设:这种非自然的“暴力切分”,会严重干扰模型对文本的理解和处理能力。
为了验证这一点,研究团队在 7 个 NLP 任务和 4 种主流模型(Phi, Mistral, Qwen, Llama)上进行了广泛测试。结果令人震惊:只要输入文本中存在被“破碎”的单词,模型的表现通常就会变差;而一旦通过同义词替换等方式修复了这些破碎词,模型的预测往往能瞬间被修正。
如何量化这种“切分之痛”?
既然切分不好会降智,那我们能不能给文本打个分,看看它的切分质量有多差?
研究团队提出了Tokenization Penalty(切分惩罚) 的概念,并设计了四种计算维度的惩罚函数,用来衡量特定 LLM 对给定文本的切分有多“糟糕”:
-
异常分数惩罚(Anomaly Score, AS):
利用孤立森林(Isolation Forest) 算法检测 Token 向量的异常值。如果一个单词被切分成了几个在向量空间中非常“怪异”的 Token,那么它的惩罚分就高。这基于一个直觉:那些因为切分而产生的碎片 Token,往往是训练不足的(Under-trained)。
-
未使用 Token 距离(Unused Token Distance, UT):
计算切分出的 Token 与“未使用 Token”(Unused Tokens)嵌入向量的距离。如果切出来的 Token 和那些从未在训练中出现的 Token 很像,说明这个切分质量很低。
-
成对距离(Pairwise Distance, PD):
计算被切分出的相邻 Token 之间的余弦距离。如果一个单词内部的 Token 之间距离很远(语义不相关),说明这个单词被切得“支离破碎”,语义连贯性极差。
-
上下文惩罚(Contextual Penalty, CP):
利用模型自身的预测概率。如果模型在给定前文的情况下,对当前 Token 的预测概率很低(即感到“意外”),说明这个切分让模型感到困惑。
实验验证:数据不说谎
为了证明这些惩罚函数真的有效,研究人员进行了一系列的统计显著性测试(t-test 和 Mann-Whitney U test)。
他们将测试样本分为两组:模型回答正确的组(Correct) 和 模型回答错误的组(Incorrect)。
实验结果表明(如下图表所示):
-
在大多数任务中,错误组的平均切分惩罚显著高于正确组。
-
这意味着,如果一段文本的“切分惩罚”很高,那么模型处理这段文本时出错的概率就会大大增加。
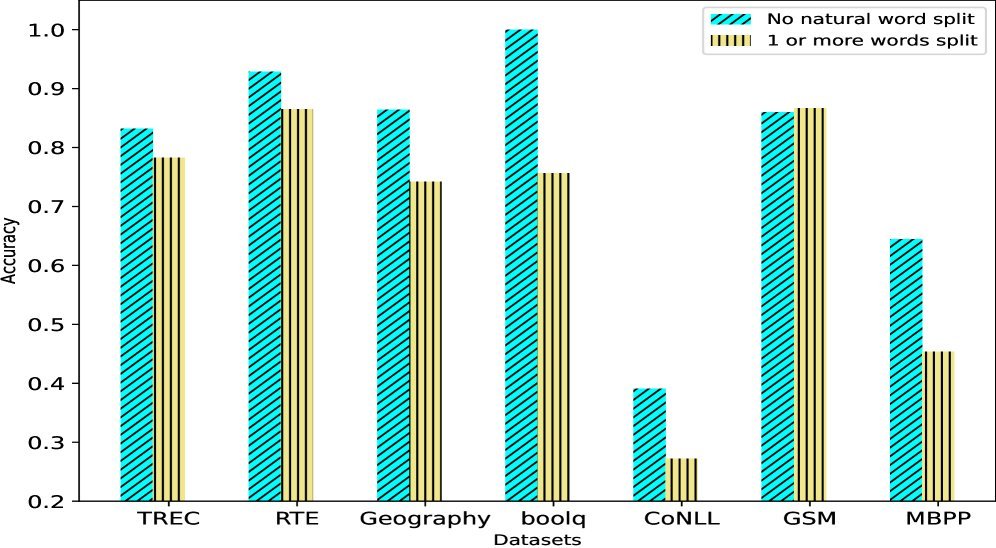
图注:实验显示,当单词被切分为多个 Token 时(橙色柱),模型性能普遍低于单词未被切分时(蓝色柱)。
总结与启示
这项研究揭示了当前 LLM 架构中一个隐蔽的短板:BPE 等分词算法虽然解决了 OOV(未登录词)问题,但也引入了大量语义噪声。
对于开发者和研究人员来说,这带来了两个重要的启示:
-
Prompt 优化新思路:在提示工程中,可以尝试替换那些会被切分得支离破碎的词汇,使用更常见的同义词,可能会“玄学”般地提升效果。
-
分词器设计:未来的分词器设计不应只追求压缩率,更应考虑语言学的形态结构,尽量避免破坏单词的内部语义。
下次当你的模型表现不佳时,不妨检查一下:是不是某些关键词被切得“粉身碎骨”了?