CAMformer横空出世:Attention能效飙升10倍,用联想记忆取代矩阵乘法

Transformer模型几乎主宰了整个AI领域,但其核心的自注意力(Self-Attention)机制始终存在一个“阿喀琉斯之踵”:计算和内存开销会随序列长度呈二次方增长。这意味着处理长文本、高分辨率图像或长视频时,成本会急剧飙升。
ArXiv URL:http://arxiv.org/abs/2511.19740v1
有没有可能彻底绕开这个瓶颈?来自亚利桑那州立大学、杜克大学和斯坦福大学的研究者们给出了一个颠覆性的答案:CAMformer。它不再将Attention视为复杂的矩阵乘法,而是回归其本质——一种基于内容的搜索。通过这种新范式,CAMformer实现了惊人的性能:能效提升超过10倍,吞吐量最高提升4倍,芯片面积却缩小了6-8倍,同时几乎没有精度损失。
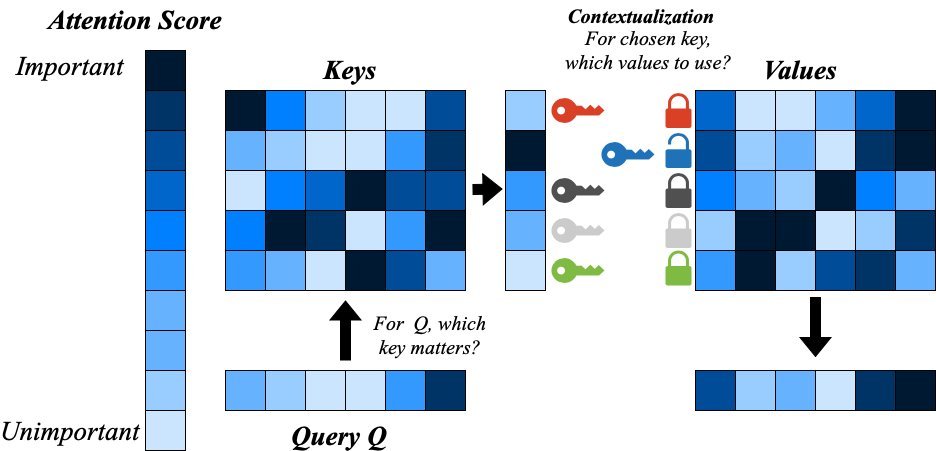
Attention即搜索:联想记忆是关键
传统Attention的核心是计算查询(Query, $Q$)和键(Key, $K$)之间的相似度,这通常通过大规模的矩阵乘法 $QK^T$ 实现,计算量巨大。
CAMformer提出,这个过程本质上是在一个“记忆库”(由$K$构成)中,为每个$Q$寻找最相似的条目。这不就是联想记忆(Content Addressable Memory, CAM)的拿手好戏吗?CAM允许你输入内容($Q$),并立即(通常是常数时间内)返回存储器中与之匹配的数据地址。
基于这个思想,研究者设计了一种新颖的电路:二值化注意力CAM(Binary Attention CAM, BA-CAM)。
BA-CAM:用物理定律“感知”相似度
为了将Attention适配到CAM架构,CAMformer首先对$Q$和$K$向量进行二值化处理。这不仅将存储需求压缩到原来的6.25%,更关键的是,它为模拟计算铺平了道路。
BA-CAM的核心是一种创新的10T1C(10个晶体管,1个电容)单元。它用模拟电路的物理特性取代了繁琐的数字计算:
-
并行匹配:查询向量$Q$被广播到所有存储着键向量$K$的CAM行。
-
电荷共享:每个CAM单元通过XNOR逻辑比较对应的比特位。如果匹配,单元内的电容保持充电状态;如果不匹配,则放电。
-
模拟累加:同一行所有单元的电荷会“共享”到一条“匹配线”(Matchline)上。最终,这条线上的电压值就正比于$Q$和$K$之间的汉明相似度(Hamming Similarity)。
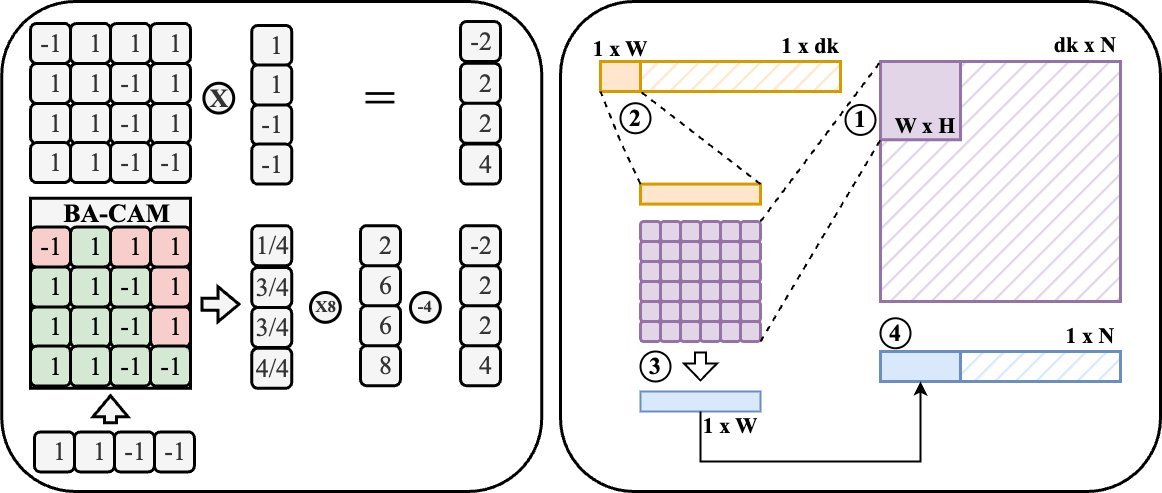
这个过程完全在模拟域完成,通过一次电荷共享就得到了相似度分数,实现了常数时间的相似度搜索,彻底告别了数字逻辑中的乘法和加法器。
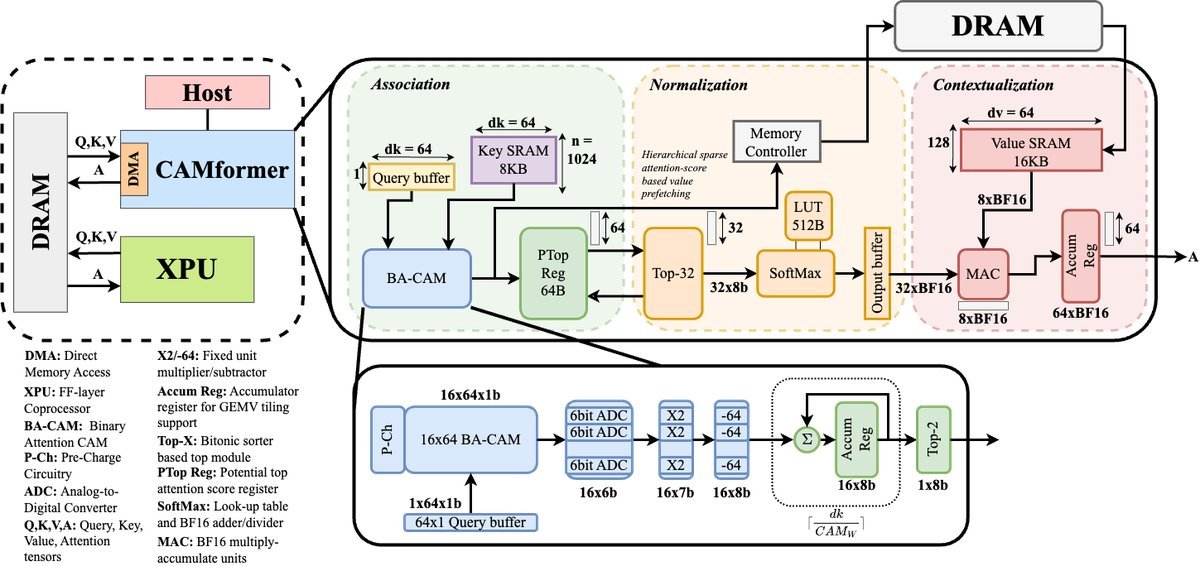
CAMformer:高效的三级流水线架构
围绕BA-CAM,研究者构建了名为CAMformer的完整加速器架构。它采用三级流水线设计,每个阶段都经过精心优化,以最大化效率。
-
关联阶段 (Association):这是核心阶段。BA-CAM快速计算出二值化的$QK^T$分数。紧接着,一个分层稀疏排名机制启动,只保留每个计算区块中分数最高的Top-k个候选项(例如Top-2)。
-
归一化阶段 (Normalization):从上一阶段的所有候选项中,选出最终的全局Top-k(例如Top-32)。然后,一个小型化的Softmax引擎对这些稀疏的分数进行归一化。由于分数范围有界,Softmax可以通过一个小型查找表(LUT)高效实现。
-
情境化阶段 (Contextualization):最后,用归一化后的高精度注意力分数(BF16格式)与对应的值(Value, $V$)向量进行稀疏矩阵乘法,得到最终的输出。
性能飞跃的关键优化
CAMformer的惊人性能并非单一技术所致,而是一系列软硬件协同优化的结果。
-
分层稀疏注意力:通过“先粗筛,再精选”的两阶段Top-k策略,大幅减少了需要处理的数据量。更巧妙的是,第一阶段筛选出的索引可以被用来预取$V$向量,从而完美隐藏了DRAM内存访问的延迟。
-
精细化流水线:在每个阶段内部(如Softmax计算)和阶段之间都设计了流水线,确保硬件单元始终处于忙碌状态,最大化了利用率和吞吐量。
-
软硬件协同设计:CAMformer的架构参数(如Top-k中的$k$值)与算法(如汉明注意力蒸馏,Hamming Attention Distillation, HAD)紧密配合。研究表明,这种分层稀疏方法在DeiT和BERT等模型上带来的精度下降微乎其微(在GLUE基准上平均<0.4%),实现了效率与精度的双赢。
实验结果:碾压级的能效优势
CAMformer的性能评估结果令人印象深刻。在处理BERT-Large模型的单查询任务时,与当前最先进的加速器相比:
-
能效与吞吐量:CAMformer的能效(GOP/J)比现有SOTA方案高出10倍以上,吞吐量(Queries/s)提升了4倍。
-
面积优势:芯片面积仅为其他方案的1/6到1/8。
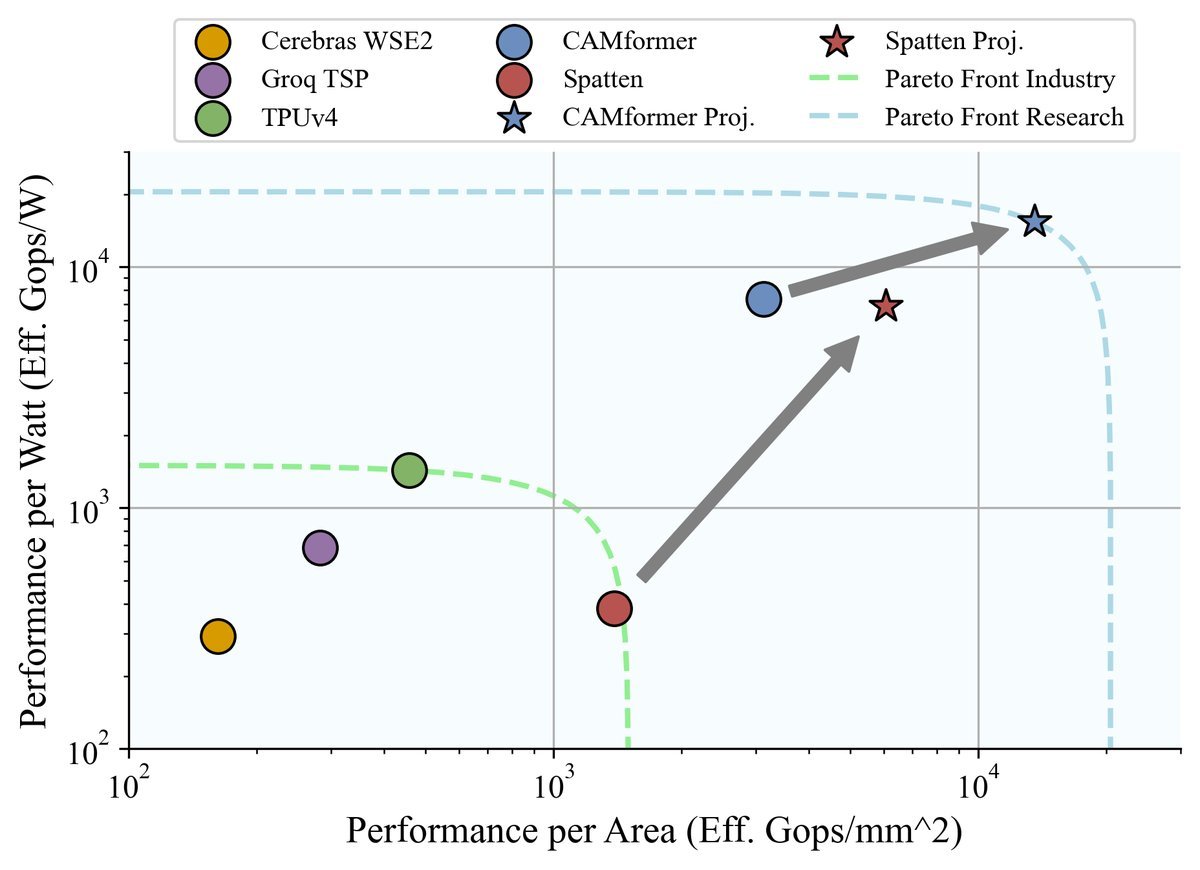
从上图的帕累托前沿比较中可以清晰地看到,CAMformer在性能功耗比和性能面积比上都定义了新的技术前沿,甚至超越了Google TPUv4和Cerebras WSE2等工业界巨头的产品。
总结
CAMformer为解决Transformer的扩展性难题提供了一条全新的、极具潜力的路径。它通过将注意力计算从“矩阵乘法”重新诠释为“联想记忆搜索”,并利用模拟计算的物理特性实现了常数时间的相似度匹配,从根本上改变了计算范式。
这项研究证明,通过软硬件的深度协同设计,我们不仅可以大幅提升AI计算的效率,还能以更小的代价实现更强的性能。未来,这种基于内存计算(In-Memory Computing)的思想或许将为构建更大、更高效的AI模型开辟新的天地。