Can LLMs Track Their Output Length? A Dynamic Feedback Mechanism for Precise Length Regulation
LLM数不清字数?阿里新法让模型“边写边看”,训练效率升4倍

“请写一篇500字的文章。”
ArXiv URL:http://arxiv.org/abs/2601.01768v1
当你把这个简单的指令发给 ChatGPT 或 LLaMA 时,结果往往令人抓狂:它要么洋洋洒洒写了800字,要么草草收尾只写了300字。尽管大语言模型(LLM)在指令遵循上已经登峰造极,但在“精准控制字数”这件小事上,它们却表现得像个刚学会写字的小学生。
为什么会这样?来自阿里巴巴、理想汽车和厦门大学的研究团队在最新论文中揭示了一个反直觉的真相:LLM根本不知道自己写了多长。为了解决这个问题,该研究提出了一种无需训练即可使用的动态反馈机制(Dynamic Feedback Mechanism),让模型像人类看字数统计一样“边写边看”,在不牺牲生成质量的前提下,实现了精准的长度控制。
核心痛点:LLM 其实是“字数盲”
在深入解决方案之前,该研究首先进行了一项有趣的初步调查:LLM 到底能不能估算自己的输出长度?
研究人员让 Qwen3 和 LLaMA-3.1 生成摘要,然后反过来问模型:“你刚才生成的这段话有多少个 Token?”
结果令人大跌眼镜(如下图所示):
随着文本长度的增加,模型的估算误差(MAE)呈直线上升趋势。这揭示了一个本质缺陷:LLM 在生成长文本时,注意力主要集中在内容规划上,完全丢失了对长度的感知。
这其实很像人类的写作过程。我们在写论文时,也不会在脑子里实时数每一个字,而是依赖外部工具——比如 Word 文档左下角的“字数统计”。
解决方案:给模型装一个“字数计数器”
受人类写作习惯的启发,该研究提出了一种简单而高效的方法:既然模型自己数不清,那就由外部工具告诉它。
这种方法被称为动态长度反馈。与以往试图通过复杂的强化学习(RL)或在 Prompt 中死磕的方法不同,该策略的核心逻辑非常直观:
-
单次生成,间歇打断:模型在生成文本的过程中,不会被强制要求一次性完成。
-
句末插入反馈:每当模型生成完一个句子(检测到句号等标点),外部程序会计算当前的长度(Token数、单词数或句子数)。
-
注入提示:将计算出的长度信息(例如 \((Current length: 150 words)\))作为文本的一部分,拼接在当前生成的末尾,反馈给模型。
-
动态调整:模型看到这个反馈后,会根据剩余的目标长度,自动调整接下来的生成策略。

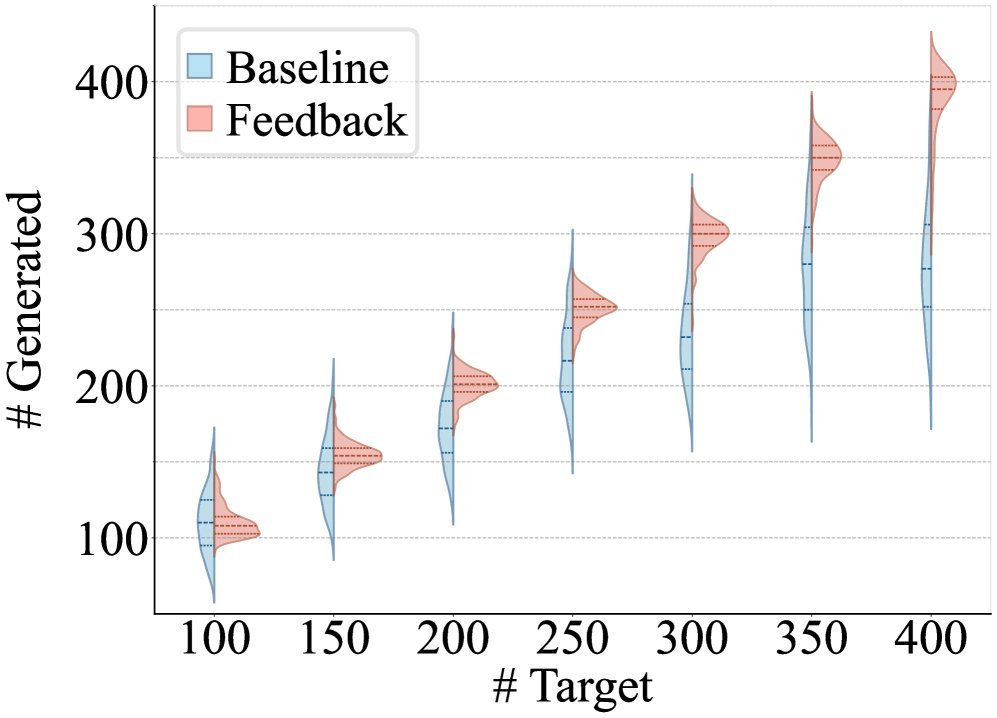
如上图所示,传统的 Prompt 方法(左侧)是一条道走到黑,模型写着写着就忘了长度限制。而反馈引导方法(右侧)则像是在跑步时不断看表,确保配速精准。
实验效果:无需训练,即插即用
这种方法最吸引人的地方在于它的零样本(Zero-shot)能力。研究人员在摘要生成(GovReport)和传记生成(Biographies)任务上进行了测试。
结果显示,在不进行任何额外训练的情况下,仅通过 Prompt 告诉模型“我会给你反馈”,并结合上下文学习(ICL),模型对长度的控制精度就实现了质的飞跃。
主要亮点包括:
-
精度大幅提升:无论是在 Token、单词还是句子级别的长度控制上,反馈机制的误差(MAE)都显著低于基线模型。
-
质量未受损:通过 DeepSeek-V3 作为裁判的打分显示,加入反馈机制后,文本的连贯性、一致性和相关性并没有因为插入了“噪声”而下降。
-
超越复杂基线:与之前最先进的 Markergen 方法相比,该方法不需要多阶段推理,推理效率更高,且避免了多阶段带来的错误累积问题。
进阶玩法:SFT 让效率提升4倍
虽然“免训练”版本已经很好用了,但在处理更复杂的通用领域问题(如 ELI5 长文本问答)时,模型可能会为了凑字数而牺牲回答质量。
为了解决这个问题,研究团队进一步使用了监督微调(Supervised Fine-Tuning, SFT)。他们构建了一个包含长度反馈的数据集,让模型学会主动利用这些反馈信息来平衡长度和质量。
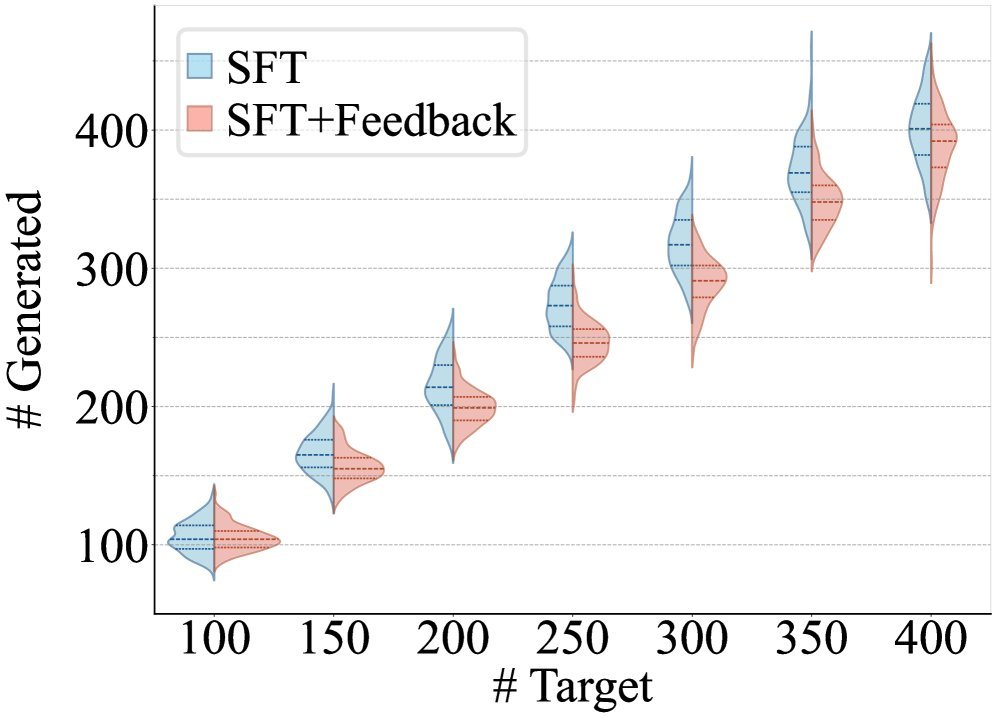
训练动力学分析(上图)表明,引入反馈机制后的 SFT 效率惊人。SFT+Feedback 方法仅需基线方法 1/4 的训练步数,就能达到同等甚至更好的长度控制效果。这说明,当模型不再需要分心去“猜”自己写了多少字时,它能更专注于学习如何根据长度调整内容。
总结
这项研究给 AI 社区带来了一个重要的启示:有时候,解决大模型缺陷的最佳方式不是“硬刚”模型能力,而是引入简单的外部工具。
通过模拟人类“边写边看字数统计”的行为,该研究不仅解决了 LLM 长期以来的长度控制难题,还证明了这种机制具有极高的训练效率和泛化能力。对于需要严格控制输出篇幅的应用场景(如新闻摘要、推文生成、广告文案)来说,这无疑是一个极具实用价值的技术突破。