BERT“逆袭”GPT?微软新论文揭示Decoder-only在因果推理中的致命短板

在如今的大模型时代,“Decoder-only is all you need”似乎已成为某种不成文的铁律。从GPT系列到Llama,再到Qwen,生成式架构统治了几乎所有榜单。然而,当我们剥离掉华丽的语言外壳,直面最纯粹、最严苛的因果推理(Causal Reasoning)任务时,这些庞然大物是否依然无懈可击?
ArXiv URL:http://arxiv.org/abs/2512.10561v1
来自IIIT Hyderabad、微软、IIT Delhi等机构的一项最新研究给出了令人意外的答案:在因果推理任务上,Decoder-only 模型可能并不是最优解,甚至在某些方面完败给“过气”的 Encoder 架构(如 BERT)。
这篇论文《Causal Reasoning Favors Encoders: On The Limits of Decoder-Only Models》不仅挑战了主流架构的权威,更通过深入的机理分析揭示了:对于需要多跳逻辑组合的任务,全向视野的 Encoder 远比单向递归的 Decoder 更具优势。
什么是因果推理的“阿喀琉斯之踵”?
在深入实验之前,我们需要明确本文讨论的“因果推理”并非简单的文本续写,而是指基于严格规则的演绎(Deductive Reasoning)。它有两个核心要求:
-
多跳组合(Multi-hop composition):能够像链条一样,将 $A \to B$,$B \to C$ 串联起来推导出 $A \to C$。
-
严格的合取控制(Strict conjunctive control):只有当所有前提条件同时满足时,才能得出结论。
现有的LLM虽然通过上下文学习(In-Context Learning, ICL)展现出了一定的推理能力,但研究人员怀疑,它们更多是依赖输入中的“词汇捷径”(Spurious Lexical Relations),而非真正理解了逻辑结构。
为了验证这一点,研究团队设计了一个巧妙的实验:不仅测试自然语言(NL)推理,还测试了非自然语言(Non-Natural Language, NNL)推理。例如,将“蝙蝠侠是善良的”替换为乱码般的“Batman is a#d}”。如果模型真的懂逻辑,它应该依然能推导出结果;如果它只是在玩文字接龙,那它就会崩溃。
架构之争:全知视角 vs. 步步为营
该研究的核心假设在于架构的本质差异:
-
Encoder 架构(如 BERT):拥有“上帝视角”,能一次性将整个输入投射到潜在空间,捕捉全局的逻辑依赖。
-
Decoder-only 架构(如 GPT):是递归的,只能从左到右逐个Token生成。虽然有注意力机制,但其本质是单向的。
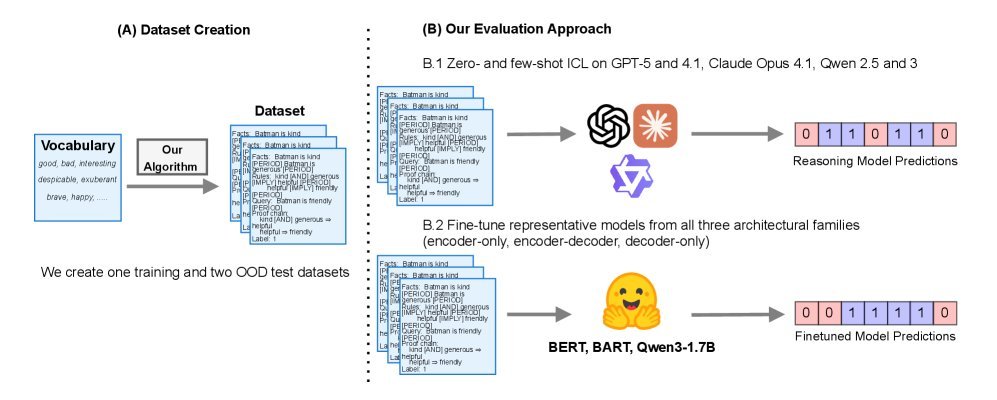
图1:研究概览。左侧展示了从自然语言到乱码(NNL)的数据集构建;右侧展示了对比的各类模型,包括BERT、BART以及Qwen等Decoder-only模型。
实验结果:BERT 的“反击”
研究团队对比了微调后的 Encoder(BERT)、Encoder-Decoder(BART/Flan-T5)以及 Decoder-only(Qwen、GPT系列)模型。结果令人深思:
1. ICL 并不足以应对严谨推理
仅靠上下文学习(Zero-shot 或 Few-shot),Decoder-only 模型在因果推理上表现并不稳定,往往过度关注无关的输入特征。
2. Encoder 在“乱码”世界中更稳健
当测试数据从自然语言(NL)切换到非自然语言(NNL)时,Decoder-only 模型的性能出现了明显的分布偏移(Distributional Shift)脆性。
如下图所示,随着推理深度(Depth)的增加,Decoder-only 模型(如 Qwen3-1.7B)的准确率在 NNL 数据集上断崖式下跌,迅速退化为随机猜测。相比之下,微调后的 BERT-Base 展现出了惊人的鲁棒性,即使在深度为 7 的复杂推理链中依然能保持较高的准确率。
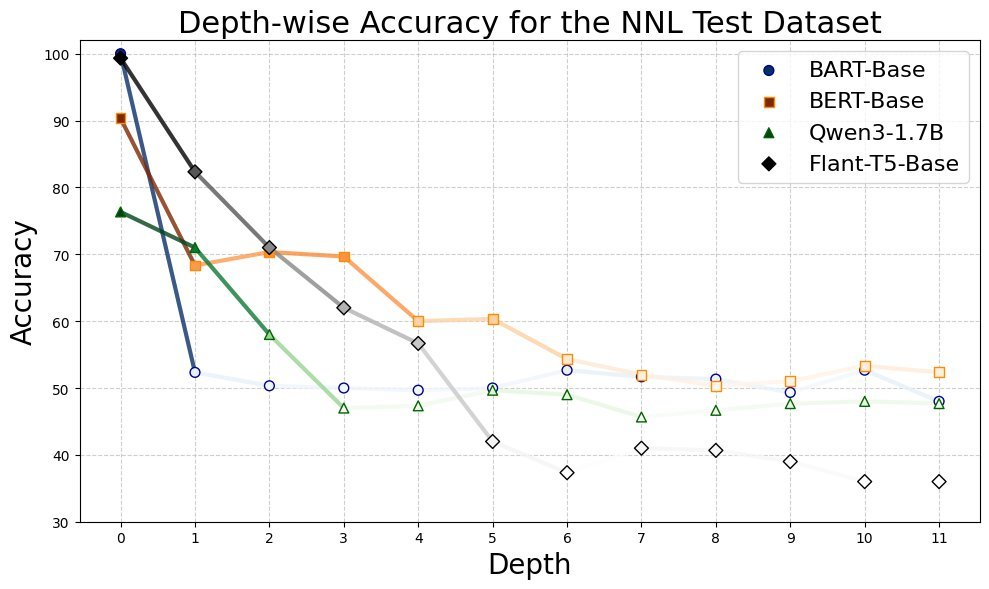
图2:非自然语言(NNL)数据集下的深度-准确率曲线。可以看到,随着推理步数(Depth)增加,Encoder-based 模型(如 BERT-Base,绿线)的衰减速度远慢于 Decoder-only 模型(如 Qwen3-1.7B,红线)。
3. 效率与成本的碾压
除了准确率,论文还进行了一项“性价比”分析。虽然 GPT-5(论文中作为 SOTA 参考)在所有任务中都达到了近乎完美的准确率,但其代价是巨大的延迟和算力成本。
相比之下,BART-Base 的推理效率极高,每获得 1% 的准确率提升,其耗时仅为 GPT-5 的极小一部分。对于短周期的、对成本敏感的因果推理任务,传统架构完胜。
深度解读:为什么 Encoder 更懂逻辑?
为了解释这种现象,作者引入了机械可解释性(Mechanistic Interpretability)分析,具体使用了“曲率”(Curvature)作为探针。
逻辑推理在模型的表示空间中应该表现为平滑的轨迹。研究发现,Encoder 架构在深层推理中能保持较高的“曲率相似性”,这意味着它们在进行一致的逻辑变换。 而 Decoder-only 模型的曲率随着推理深度增加而迅速漂移,说明它们在递归过程中积累了大量的局部噪声,破坏了高阶的逻辑不变量。
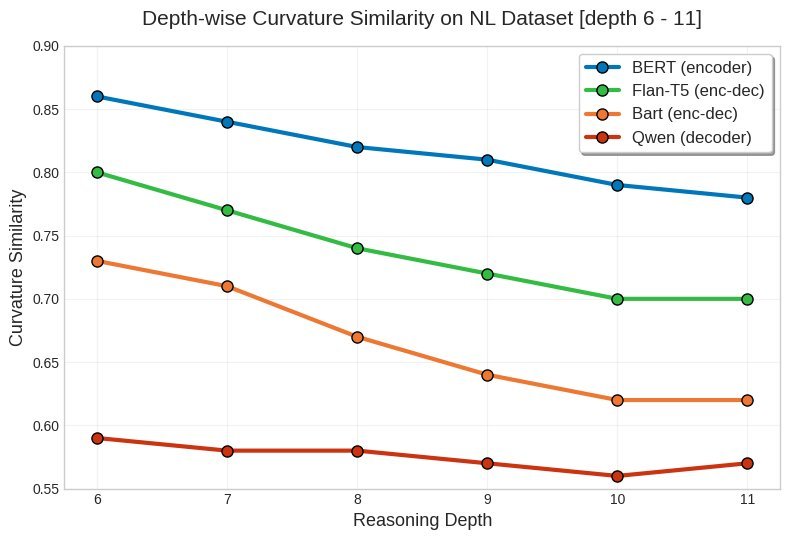
图3:不同架构随推理深度增加的曲率相似性。BERT(蓝色)保持了最高的稳定性,而 Qwen(红色)则迅速下降,表明其内部逻辑流的崩塌。
总结与启示
这篇论文给盲目追求“大一统”模型的业界泼了一盆冷水,但也指明了一条务实的道路。
该研究表明,Decoder-only 架构并非万能钥匙。在需要多跳、严格逻辑组合的因果推理任务中,它们往往依赖浅层的词汇关联,而非深层的逻辑结构。
对于开发者而言,如果你的应用场景涉及大量严谨的短程逻辑推理(例如规则引擎、法律条文审核、数学证明片段),与其花费巨资调用 GPT-4 或微调庞大的 Llama,不如回头看看 BERT 或 BART。经过针对性微调的 Encoder 架构,不仅能提供更稳健的逻辑性能,还能为你节省数量级的算力成本。
有时候,简单的、全向的视野,比昂贵的、单向的预测更接近真理。