CaveAgent: Transforming LLMs into Stateful Runtime Operators
告别上下文遗忘!CaveAgent引入“双流架构”,数据密集任务Token暴降59%

你是否遇到过这样的尴尬:让AI Agent处理一个复杂任务,几轮对话后它竟然把之前的关键变量“忘了”,或者因为上下文窗口爆炸而不得不截断信息?目前的Agent大多依赖JSON格式进行函数调用,这种“文本进、文本出”的模式不仅效率低下,而且极易在多轮交互中丢失状态。
ArXiv URL:http://arxiv.org/abs/2601.01569v1
如果Agent能像程序员操作Jupyter Notebook一样,拥有一个“持久化”的内存环境,不再需要反复把数据转成文本塞给模型,会发生什么?
本文要介绍的 CaveAgent 正是这样一个颠覆性的框架。它将LLM从单纯的“文本生成器”升级为“有状态的运行时操作员”。通过引入双流上下文架构(Dual-stream Context Architecture),CaveAgent在处理数据密集型任务时,Token消耗惊人地降低了59%,并在多轮任务成功率上提升了10.5%。
痛点:被“文本化”束缚的Agent
目前的LLM Agent主要有两种流派,但都存在明显的瓶颈:
-
JSON-Schema流派(如GPT-4 Function Calling):
Agent必须严格遵循JSON格式输出。这就像是一个只会“填表”的员工,每做一步都要把结果写在纸上(序列化为文本),汇报给老板(LLM),然后再等老板发话。这种反复的序列化与反序列化,导致了严重的上下文冗余和信息丢失。
-
代码生成流派(如CodeAct):
虽然开始写代码了,但本质上还是“文本绑定”的。Agent无法直接操作外部对象(如数据库连接、大型DataFrame),所有中间结果必须打印成字符串(Print)才能被LLM“看到”。面对大数据集,这种方法瞬间就会撑爆上下文窗口。
如图3所示,CaveAgent代表了Agent工具使用的最新进化方向:对象导向的状态操作。
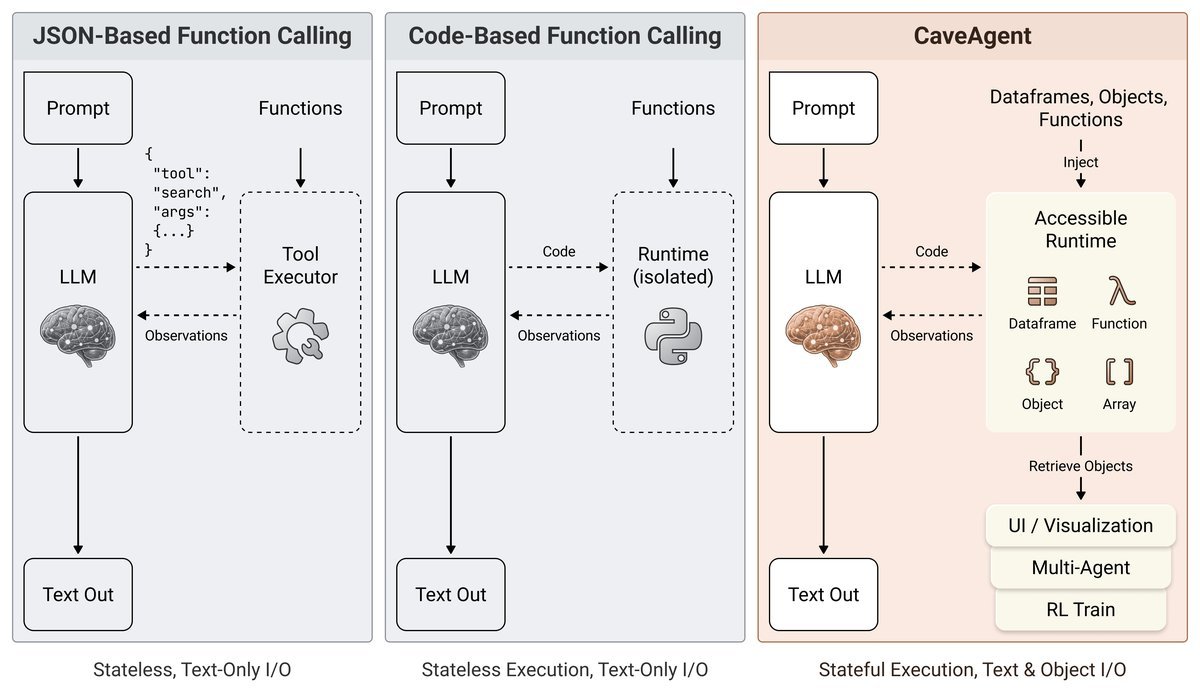
核心解法:双流架构与有状态管理
CaveAgent的核心创新在于它不再把所有东西都塞进一个Prompt里,而是设计了双流上下文架构(Dual-stream Context Architecture),如图4所示:
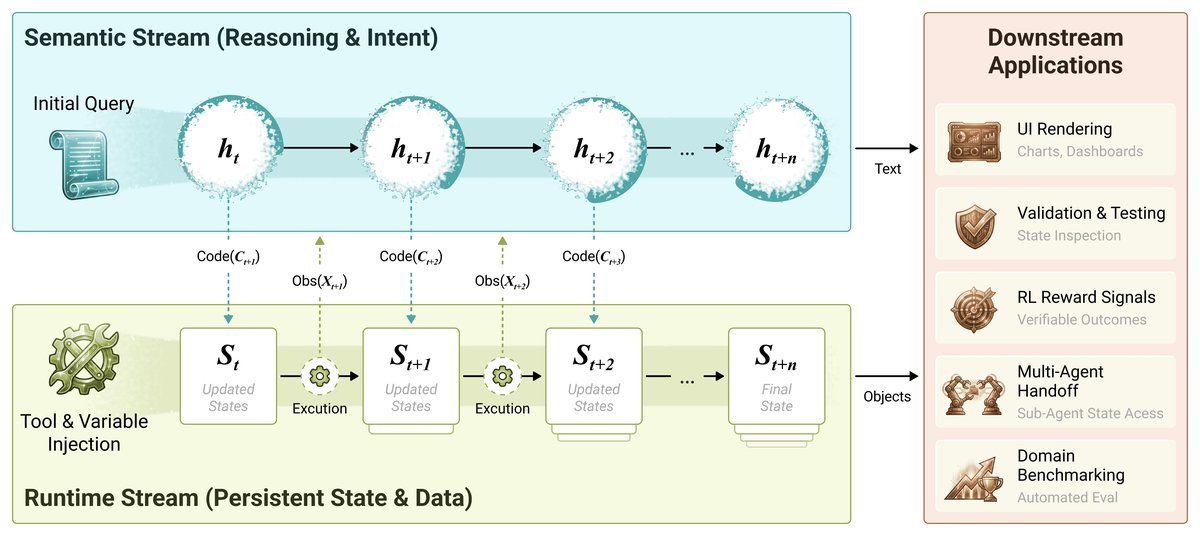
1. 语义流(Semantic Stream):轻量级的大脑
这一流负责“思考”。它只保留轻量级的推理历史和意图,接收的是对变量和函数的抽象描述(比如“有一个名为\(df\)的数据表”),而不是庞大的数据本身。这使得LLM的上下文窗口始终保持清爽。
2. 运行时流(Runtime Stream):持久化的肌肉
这一流负责“执行”和“记忆”。它是一个持久化的Python内核(类似IPython)。在这里,数据不再是文本,而是活生生的Python对象。
-
对象注入与检索:CaveAgent支持将复杂的Python对象(如Pandas DataFrame、机器学习模型、数据库连接)直接注入到运行时环境中。
-
无损流转:Agent生成的代码可以直接引用这些变量(例如 \(processed_data = preprocess(raw_data)\)),中间结果直接存储在内存中,无需转化为文本。
这种设计彻底解决了上下文漂移(Context Drift)问题。运行时环境充当了一个高保真的“外部记忆体”,LLM只需要像操作遥控器一样发送代码指令,而不需要把整个“电视机”搬进脑子里。
技术亮点:像操作对象一样操作世界
CaveAgent实现了一种从“面向过程的函数调用”到“面向对象的状态管理”的范式转变。
-
变量与函数注入:
系统会自动提取函数和变量的元数据(名称、类型、文档),生成API文档注入到语义流中。LLM看到的是:
\[methods: process(data: list) -> list\]而实际上,它操作的是内存中真实存在的对象。
-
动态上下文同步:
为了防止输出结果撑爆上下文,CaveAgent引入了动态同步机制。如果执行结果(stdout)过长,系统会自动拦截并提示Agent使用摘要方法(如\(.head()\)或\(.describe()\))来查看数据,而不是傻傻地把几百万行数据打印出来。
-
安全性检查:
通过AST(抽象语法树)静态分析,CaveAgent能有效拦截高危代码,确保执行安全。
实验结果:更聪明,更省Token
研究团队在Tau2-bench、BFCL等基准测试上对CaveAgent进行了全面评估,涵盖了从30B到1000B参数量的各类SOTA模型(如DeepSeek V3, Gemini等)。
1. 任务成功率显著提升
在零售(Retail)领域的复杂多轮任务中,CaveAgent的成功率比传统JSON方法提升了10.5%。这得益于它能通过代码一次性生成复杂的逻辑(循环、条件判断),避免了多轮JSON调用带来的误差累积。
2. Token消耗大幅降低
这是CaveAgent最亮眼的数据:
-
在普通多轮场景下,Token总消耗减少了28.4%。
-
在数据密集型任务中,由于不需要反复搬运数据文本,Token消耗更是惊人地减少了59%!这意味着同样的成本,你可以处理规模大一倍以上的任务。
3. 突破上下文限制
对于那些会导致传统Agent上下文溢出(Context Overflow)的大规模数据处理任务,CaveAgent凭借其变量引用机制,能够轻松应对,实现了真正的“举重若轻”。
总结
CaveAgent不仅仅是一个新的Agent框架,它展示了一种让LLM与计算机交互的更自然的方式:不要试图把世界压缩成文本塞给AI,而是给AI一双手(代码运行时),让它直接去操作这个世界。
这种有状态运行时管理(Stateful Runtime Management)不仅提高了效率和准确性,还为未来的多Agent协作(通过共享运行时状态)和基于验证的强化学习(RL)奠定了坚实的基础。对于正在构建复杂Agent应用的开发者来说,CaveAgent提供了一个极具参考价值的范式。