Citation-Grounded Code Comprehension: Preventing LLM Hallucination Through Hybrid Retrieval and Graph-Augmented Context
告别代码幻觉:混合检索+图增强,实现92%引用准确率与零错误

当你在深夜调试代码,询问 AI 助手某个函数的定义位置时,它自信满满地给出了一个文件路径和行号。你兴奋地打开编辑器,却发现那个文件根本不存在,或者那几行代码完全是风马牛不相及。这种“一本正经胡说八道”的幻觉(Hallucination),是目前大模型在代码理解任务中最大的痛点。
ArXiv URL:http://arxiv.org/abs/2512.12117v1
为了解决这个问题,来自奥本大学的研究团队提出了一种全新的基于引用的代码理解(Citation-Grounded Code Comprehension)框架。该研究并未止步于传统的 RAG(检索增强生成),而是引入了混合检索(Hybrid Retrieval)和图增强上下文(Graph-Augmented Context),在 30 个 Python 仓库的实测中,实现了惊人的 92% 引用准确率,并且通过机械验证机制实现了零幻觉。
为什么代码理解这么难?
现有的代码助手(如 Copilot 或基于 RAG 的问答系统)通常将代码视为普通的文本文档。然而,代码有着独特的结构。研究人员在分析了 180 个真实的开发者查询后发现,代码引用的准确性面临三大挑战:
-
稀疏的词汇匹配:很多时候,变量名或函数名是唯一的,语义向量难以捕捉精确的标识符。
-
密集的语义相似性:代码的功能描述往往是抽象的自然语言,需要向量检索来理解意图。
-
跨文件的架构依赖:这是最被忽视的一点。62% 的复杂查询需要跨文件的证据。例如,要理解一个异常处理流程,你不仅需要看到抛出异常的地方,还需要看到异常类定义的地方,而它们往往不在同一个文件里。
传统的文本相似度检索(Textual Similarity)往往会忽略这些跨文件的架构联系,导致 AI 只能看到“冰山一角”,从而产生幻觉。
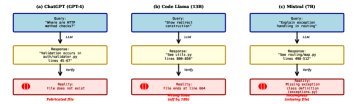
图 1:三种典型的 LLM 代码幻觉失败案例:(a) 捏造不存在的文件;(b) 引用了超出文件长度的行号;(c) 遗漏了关键的跨文件依赖(如异常定义)。
核心解法:混合检索 + 图扩展 + 机械验证
为了攻克这些难题,该研究设计了一套精密的系统,主要包含三个核心组件:
1. 混合检索(Hybrid Retrieval):精准与语义并重
系统并没有单纯依赖传统的关键词搜索(BM25)或现代的向量检索(Dense Embedding),而是将两者结合。
-
BM25:负责捕捉精确的代码标识符(如函数名 \(init_app\))。
-
BGE Embedding:负责理解自然语言查询的语义(如“如何处理路由重定向”)。
系统通过加权融合这两种分数:
\[\text{score}_{\text{hybrid}}=\alpha\cdot\text{score}_{\text{BM25}}^{\text{norm}}+\beta\cdot\text{score}_{\text{dense}}^{\text{norm}}\]实验表明,当 $\alpha=0.45$ 且 $\beta=0.55$ 时,效果最佳。这种组合确保了既能找到具体的 API,又能理解抽象的功能描述。
2. 图增强上下文(Graph-Augmented Context):顺藤摸瓜
这是该论文最大的亮点。代码不是孤立的文本,而是通过 \(import\) 语句紧密相连的图。
当检索系统找到一个相关文件(Seed File)时,系统会利用 Neo4j 图数据库,沿着 \(IMPORTS\) 关系进行“图扩展”。如果文件 A 很重要,那么文件 A 导入的文件 B 也极可能包含关键的上下文(例如基类定义或工具函数)。
系统会对这些通过图结构发现的邻居节点进行加分:
\[\text{score}_{\text{new}} = \text{score}_{\text{original}} + \gamma\]这种方法成功地在 62% 的架构查询中发现了纯文本检索遗漏的跨文件证据。
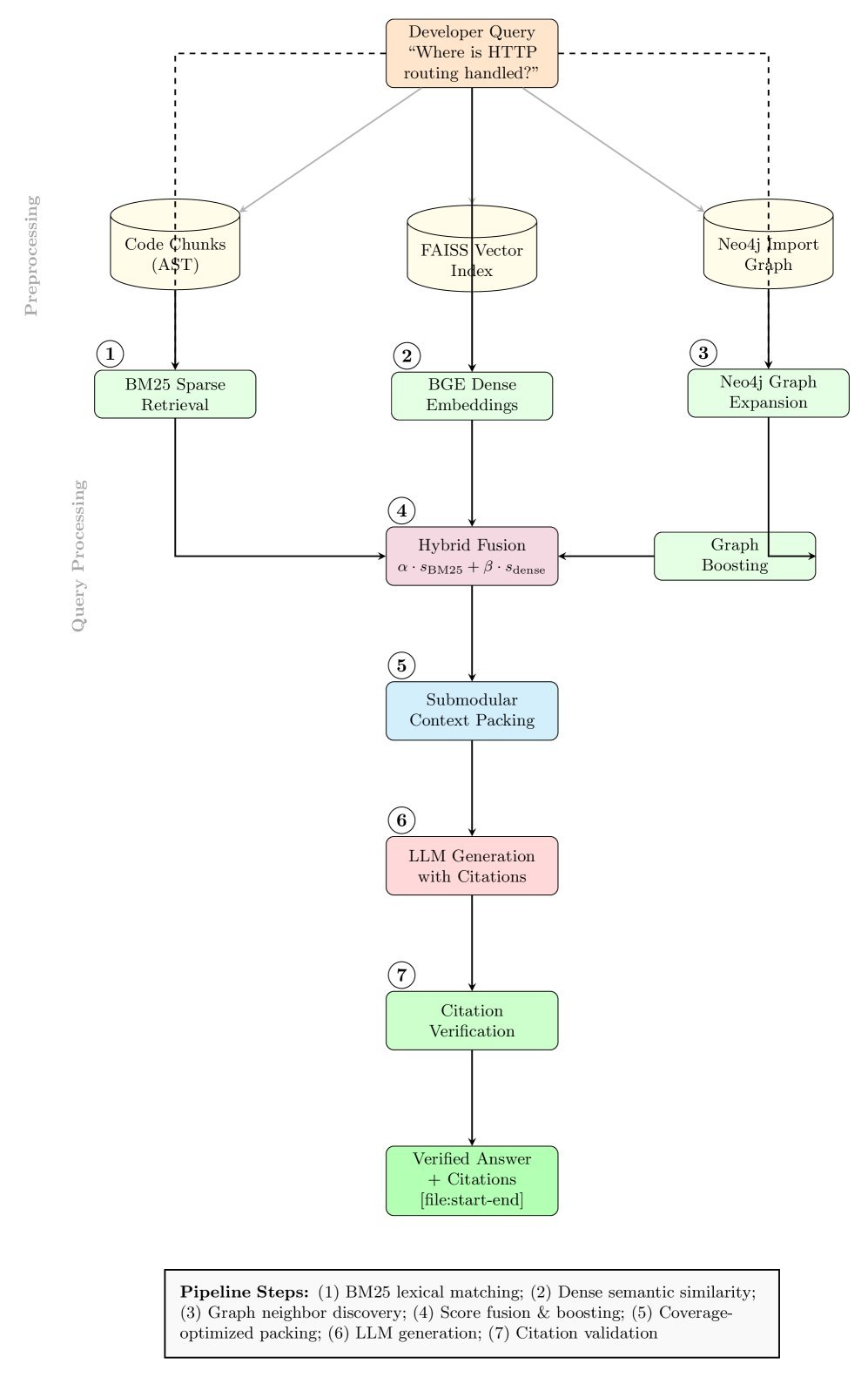
图 2:代码仓库的多维结构。理解代码不仅需要文本检索,还需要利用引用图(Import Graph)来发现跨文件的依赖关系。
3. 机械引用验证(Mechanical Citation Verification):零幻觉的守门员
为了彻底杜绝幻觉,系统引入了一个强制性的验证步骤。
系统要求 LLM 必须以 \([file:start-end]\) 的格式输出引用。然后,系统不依赖 AI 的自我检查,而是使用区间算法(Interval Arithmetic)进行机械验证:
-
检查引用的文件是否在检索到的上下文中?
-
检查引用的行号范围是否与检索到的代码块有重叠?
如果验证失败,该回答会被标记为潜在幻觉并被拦截。这种确定性的验证机制确保了最终输出的引用是 100% 真实存在的。
实验结果:全面碾压基线
研究团队在 Flask, Django, PyTorch 等 30 个流行 Python 库上进行了测试,涵盖了 6 种主流 LLM(包括 DeepSeek-Coder, CodeLlama, Mistral 等)。
-
准确率飙升:混合检索 + 图扩展的方法,比单一检索模式的准确率提升了 14% 到 18%。
-
跨文件能力:在需要多文件证据的复杂查询中,图扩展将引用的完整性提升了 24 个百分点。
-
模型表现:DeepSeek-Coder-6.7B 和 Qwen-Coder-7B 表现出了极高的指令遵循能力,能够很好地配合这套系统输出精确的引用格式。
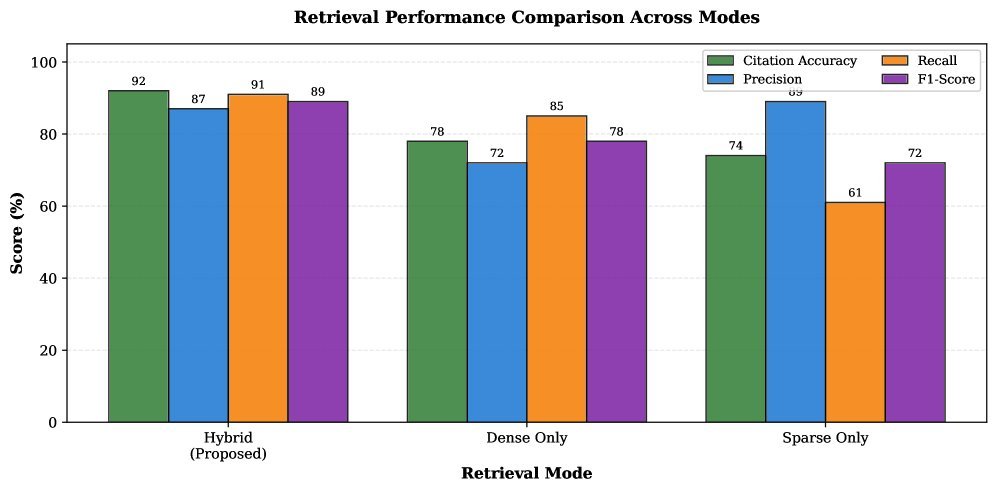
图 4:不同检索策略在 DeepSeek-Coder 模型上的表现对比。混合检索(Hybrid)明显优于单一模式,而图扩展(+Graph)进一步显著提升了准确率。
总结
这篇论文告诉我们,想要让 AI 真正理解代码,不能只把它当作聊天机器人,而必须尊重代码本身的结构特性。
通过将混合检索的广度、图结构的深度以及机械验证的严谨性相结合,我们完全可以将 LLM 从一个“偶尔胡言乱语的助手”转变为一个“严谨可靠的代码专家”。对于正在构建 AI 编程工具的开发者来说,“基于引用的生成”(Citation-Grounded Generation)或许将成为未来的架构标准。