CogFlow: Bridging Perception and Reasoning through Knowledge Internalization for Visual Mathematical Problem Solving
拒绝“看对算错”!CogFlow首创知识内化机制,7B模型视觉数学推理SOTA

多模态大模型(MLLM)在处理视觉数学问题时,经常会出现一种令人啼笑皆非的现象:模型明明准确识别出了图中的几何元素(比如识别出是一个直角三角形),但在随后的推理计算中,却完全无视这些视觉证据,开始“一本正经地胡说八道”。
ArXiv URL:http://arxiv.org/abs/2601.01874v1
这种现象被称为推理漂移(Reasoning Drift)。现有的模型要么胡子眉毛一把抓(一步式推理),要么将感知与推理完全割裂(解耦式推理),导致“眼睛”和“大脑”各干各的。
为了解决这一痛点,来自四川大学、清华大学和浙江大学的研究团队提出了一种受人类认知启发的全新框架——CogFlow。该框架首次显式地模拟了人类“感知 $\Rightarrow$ 内化 $\Rightarrow$ 推理”的层级思维流,通过引入独特的“知识内化”阶段,成功弥合了视觉感知与逻辑推理之间的鸿沟。在MathVerse、MathVista等权威基准测试中,仅7B参数量的CogFlow便展现出了超越GPT-4V等闭源巨头的潜力。
为什么模型总是“看对算错”?
在深入技术细节之前,我们需要先理解当前方案的局限性。
如图1所示,现有的视觉数学推理主要有两种流派:
-
一步式推理(One-step):直接让模型输出答案,导致感知和推理混杂,容易出错。
-
解耦式推理(Decoupled):先用一个模块提取视觉信息,再扔给语言模型推理。
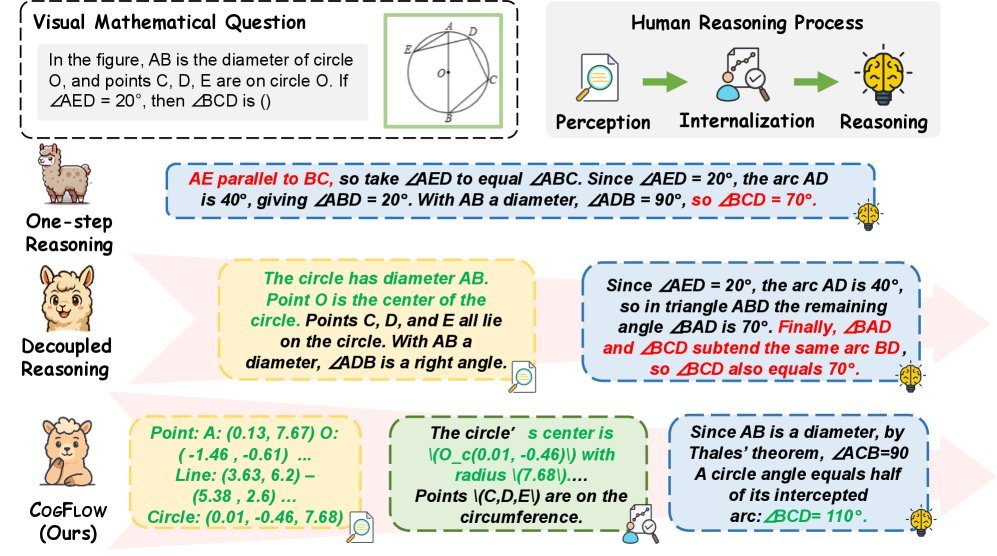
然而,研究团队发现,解耦式方案虽然提升了感知的准确率,但推理模块往往会忽略提取出的视觉线索,产生推理漂移。这就像一个学生明明抄下了题目中的条件,解题时却完全没用到,全靠瞎蒙。
CogFlow 的核心洞察在于:人类在解决数学问题时,不会直接从“看到图”跳到“写公式”,中间有一个关键的知识内化(Knowledge Internalization)过程——将低级的视觉信号转化为结构化的、可用于推理的语义知识(例如,将“看到线段AB穿过圆心”内化为“AB是直径”这一知识点)。
CogFlow:三阶段认知架构详解
CogFlow 严格遵循“感知 $\Rightarrow$ 内化 $\Rightarrow$ 推理”的认知流程,并针对每个阶段设计了专门的增强机制。
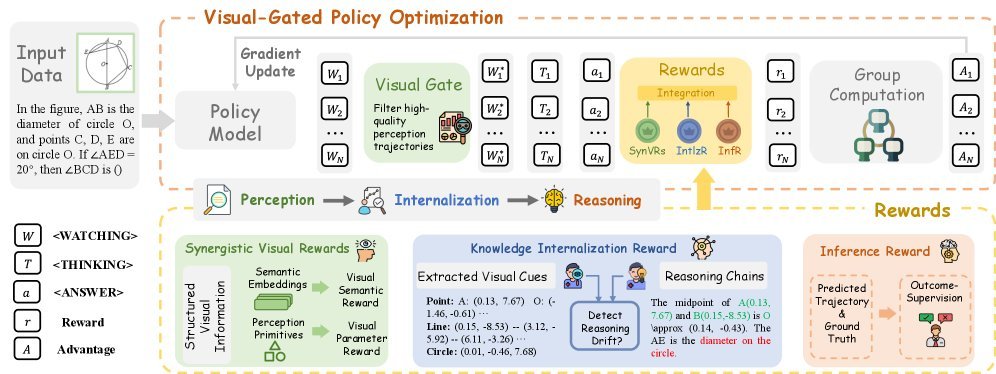
1. 感知阶段:协同视觉奖励(SynVRs)
为了让模型“看”得更准,CogFlow 并没有止步于简单的文本描述,而是设计了协同视觉奖励(Synergistic Visual Rewards, SynVRs),从两个维度进行优化:
-
视觉参数化奖励(Visual Parameterized Reward, VPR):在参数空间计算欧几里得距离,确保几何图元(点、线、圆)的精确性。
-
视觉语义奖励(Visual Semantic Reward, VSR):将提取的文本描述重新渲染成图像,计算其与原图在语义空间(CLIP embedding)的余弦距离,确保整体布局和风格的一致性。
这种“双管齐下”的策略,确保了模型提取的视觉线索既具备几何精度,又符合全局语义。
2. 内化阶段:知识内化奖励(IntlzR)
这是 CogFlow 最具创新性的部分。为了防止推理漂移,研究者引入了知识内化奖励(Knowledge Internalization Reward, IntlzR)。
该模块通过对比正负样本轨迹,训练模型识别什么是“高质量的内化知识”。研究团队总结了五种常见的内化失败模式(如遗漏图元、捏造事实、错误引用定理等),并利用 Softmax-DPO 损失函数进行优化。这一步相当于给模型装了一个“校验器”,确保后续的推理是严格基于感知到的事实进行的。
3. 推理阶段:视觉门控策略优化(VGPO)
有了准确的感知和内化的知识,如何保证多步推理的稳定性?CogFlow 提出了一种视觉门控策略优化(Visual-Gated Policy Optimization, VGPO)算法。
VGPO 的核心思想非常直观:如果第一步看都看错了,后面推得再好也是白搭。
因此,VGPO 引入了一个“视觉门控”(Visual Gate)。在生成推理链之前,模型会先生成多个感知轨迹,并利用前述的 SynVRs 对这些轨迹进行质量评估。只有高质量的感知结果才能通过“门控”,进入后续的推理生成阶段。如果所有感知结果都很差,模型会尝试重新生成,直到满意为止。
实验结果:7B模型的逆袭
为了训练 CogFlow,研究团队还构建了一个包含 120K 高质量样本的新数据集 MathCog,其中包含了精细的感知-推理对齐标注。
在 FlowVerse、MathVerse、MathVista 等多个主流基准测试上的实验结果表明,CogFlow 取得了显著的性能提升。
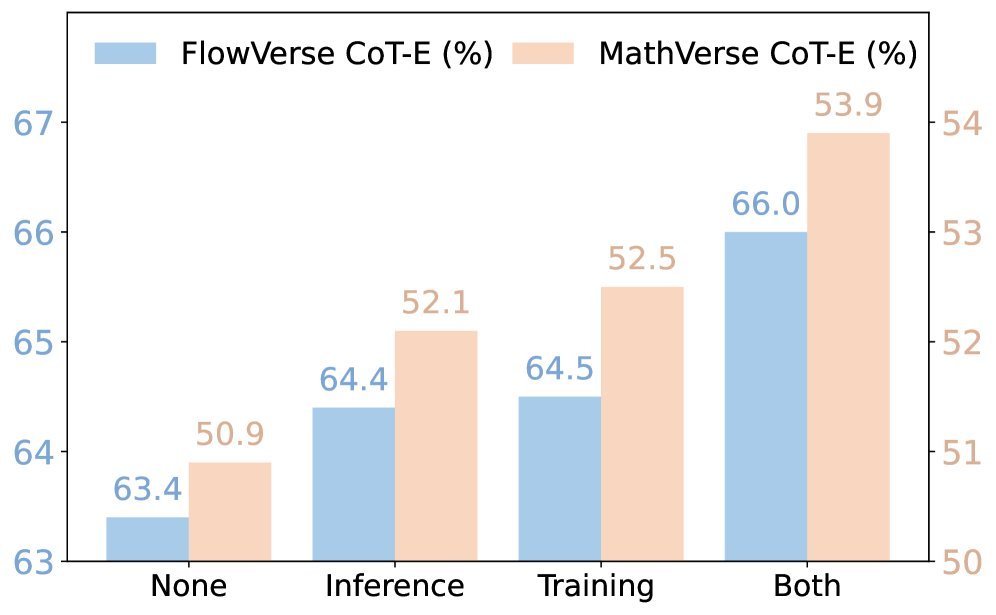
从上表可以看出:
-
CogFlow-7B 在多个榜单上全面超越了同等规模的开源模型(如 Qwen-VL-Chat, InternLM-XC2)。
-
令人惊讶的是,在 FlowVerse 和 MathVerse 等高难度基准上,7B 参数的 CogFlow 甚至击败了 GPT-4V 和 Gemini-Pro 等闭源大模型。
-
特别是在 Vision Intensive(视觉密集型)的子任务中,CogFlow 的优势尤为明显,这直接证明了其感知增强和知识内化机制的有效性。
总结
CogFlow 的成功证明了在多模态推理任务中,简单的“大力出奇迹”(堆参数、堆数据)并非唯一路径。通过借鉴人类认知科学的成果,显式地建模“感知-内化-推理”的层级结构,并利用强化学习(RL)对每个环节进行精细化对齐,小模型也能在复杂的视觉数学推理任务中展现出惊人的爆发力。
这项工作不仅解决了“推理漂移”这一顽疾,也为未来 MLLM 向更严谨、更可解释的逻辑推理方向发展提供了新的思路。