CogMem: A Cognitive Memory Architecture for Sustained Multi-Turn Reasoning in Large Language Models
给大模型装上“类脑记忆”:CogMem三层架构破解长对话遗忘难题,多轮推理更像人

大语言模型(LLM)往往是“短跑冠军”却也是“马拉松低手”。在单轮对话中,它们能展现出惊人的推理能力,但一旦进入漫长的多轮交互,随着上下文的拉长,模型往往会陷入“失忆”、幻觉频发、逻辑前后矛盾的泥潭。现有的解决方案通常是简单粗暴地将所有历史对话塞进上下文窗口,这不仅导致计算成本飙升,还会因为噪音过多干扰模型的判断。
ArXiv URL:http://arxiv.org/abs/2512.14118v1
为了解决这一痛点,来自麦考瑞大学(Macquarie University)的研究人员提出了一种名为 CogMem 的认知记忆架构。该架构不再依赖单纯的上下文堆砌,而是模仿人类的认知机制,通过构建分层的、持久化的记忆系统,让大模型在长对话中也能保持清醒的头脑和连贯的逻辑。
模仿人类认知的“记忆三重奏”
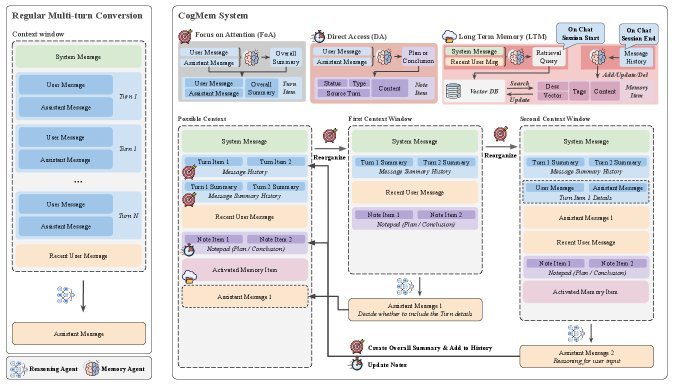
CogMem 的核心创新在于其分层记忆设计,这一灵感直接来源于人类的认知科学模型(特别是 Oberauer 的工作记忆模型)。它并没有把所有信息混为一谈,而是将记忆划分为三个层级,分别处理不同时间跨度和重要性的信息:
-
注意力焦点(Focus of Attention, FoA):
这是最顶层的短期记忆,类似于人类“当前正在思考的事情”。FoA 机制会根据当前的任务,动态地重构出一个极简的、最相关的上下文。它只保留当下推理最需要的线索,从而避免了无关历史信息的干扰,也极大地节省了 Token 消耗。
-
直接访问记忆(Direct Access, DA):
这层记忆类似于我们在会议中做的“笔记”。它维护着当前会话级别的关键信息和计划。DA 负责存储那些虽然当前不在注意力焦点中,但对整个会话至关重要的中间推理结果。它起到了承上启下的作用,确保模型在同一个会话内不会“断片”。
-
长期记忆(Long-Term Memory, LTM):
这是最底层的知识库,用于存储跨会话的推理策略和经验。当模型经历了一次复杂的推理过程后,LTM 会将其中提炼出的核心策略和知识固化下来。这意味着,模型不仅能记住“刚才说了什么”,还能记住“上次是怎么解决类似问题的”,从而实现跨会话的能力迁移。
双智能体协作:推理与记忆分离
为了高效管理这套复杂的记忆系统,CogMem 引入了双智能体协作模式:
-
推理智能体(Reasoning Agent):专注于解决问题,执行具体的推理任务。
-
记忆智能体(Memory Agent):专注于“做笔记”和“翻旧账”。它负责对推理过程进行总结、更新 DA 笔记,并从 LTM 中检索相关信息。
这种职责分离的设计非常巧妙。它让推理模型可以轻装上阵,专注于逻辑推导,而繁琐的记忆维护工作则交给更轻量级的模型去处理。系统还配备了会话管理器(Session Manager)和记忆管理器(Memory Manager),负责判断是否可以复用旧的会话、何时清理无效记忆以及如何将短期经验固化为长期知识。
实验验证:层层递进的效果
研究团队在 TurnBench-MS 基准测试上对 CogMem 进行了评估。这是一个专门设计用来测试模型在多轮交互中推断隐藏规则能力的测试集,难度颇高。实验使用了 Gemini 2.5 Flash 作为基础模型。
下表展示了不同配置下的性能对比(基于 TurnBench 经典模式):
| Model Configuration | Easy (Acc) | Medium (Acc) | Hard (Acc) | Overall (Acc) |
|---|---|---|---|---|
| Baseline (Gemini 2.5 Flash) | 0.93 | 0.73 | 0.60 | 0.76 |
| + FoA (仅加入注意力焦点) | 0.93 | 0.80 | 0.67 | 0.80 |
| + FoA + DA (加入直接访问记忆) | 1.00 | 0.87 | 0.73 | 0.87 |
| + FoA + DA + LTM (CogMem) | 1.00 | 0.93 | 0.80 | 0.91 |
数据清晰地揭示了每一层记忆的独特价值:
-
仅引入 FoA,模型在困难任务上的准确率就有提升,说明精简上下文能有效减少干扰。
-
加入 DA 后,整体准确率进一步提升至 0.87,证明了会话级笔记对维持连贯性的重要性。
-
最终完整的 CogMem 架构(加入 LTM)将整体准确率推高至 0.91,特别是在中等和困难任务上表现优异。
总结
CogMem 的出现为大模型的长文本推理提供了一个极具潜力的方向。它证明了,与其无限制地扩大上下文窗口(Context Window),不如教模型学会“如何记忆”。
通过 LTM、DA 和 FoA 的协同工作,CogMem 不仅解决了上下文无限增长带来的成本问题,更重要的是,它让模型具备了类似人类的“反思”和“经验积累”能力。这种从被动接收上下文到主动管理记忆的转变,或许正是通向更可靠、更像人类的 AI 推理系统的必经之路。