CoMeT: Collaborative Memory Transformer for Efficient Long Context Modeling
阿里CoMeT:32k训练解锁100万长文,显存恒定,告别KV Cache爆炸

在大模型(LLM)的竞赛中,“长文本能力”一直是兵家必争之地。然而,现有的Transformer架构面临着一个物理定律般的诅咒:随着上下文长度增加,计算复杂度呈二次方爆炸,KV Cache更是像无底洞一样吞噬显存。
ArXiv URL:http://arxiv.org/abs/2602.01766v1
虽然市面上有各种“上下文压缩”技术,但它们往往以牺牲精度为代价。有没有一种方法,既能保持线性时间复杂度,又能让显存占用恒定不变,还能精准找回100万字之前的细节?
来自阿里巴巴、东北大学和清华大学的研究团队给出了答案。他们提出了 CoMeT(Collaborative Memory Transformer),这是一种全新的架构,只需在32k长度的文本上进行微调,就能完美泛化到1M(100万)Token的超长上下文,且显存占用几乎不随长度增加!
核心痛点:Transformer的“记忆危机”
标准的Transformer依赖于KV Cache来存储历史信息。这导致了两个致命问题:
-
显存爆炸:处理1M长度的文本,KV Cache的大小会变得天文数字,单张GPU根本装不下。
-
计算龟速:注意力机制的计算量随着长度呈二次方增长($O(N^2)$),推理速度极慢。
现有的解决方案要么是“有损压缩”(丢失细节),要么是基于RNN的线性注意力(容易遗忘关键信息)。CoMeT则走出了一条新路:它引入了一套协同记忆机制,像人类大脑一样,既有“短期记忆”负责即时细节,又有“长期记忆”负责关键线索。
CoMeT的秘密武器:双重协同记忆
CoMeT的设计理念非常精妙,它作为一个轻量级的“插件”模块,可以无缝集成到预训练模型中。其核心在于将输入文本切分成一个个块(Chunk),并利用两套记忆系统来管理上下文:
1. 临时记忆(Temporary Memory):FIFO队列
这相当于我们的“工作记忆”。CoMeT使用一个先进先出(FIFO)的队列来存储最近几个块的精细信息。
-
作用:确保模型对最近发生的事件有高保真的感知,不会因为压缩而丢失细节。
-
机制:随着新信息的进入,最旧的信息被移出,但这并不意味着遗忘,因为它们会被提炼进入全局记忆。
2. 全局记忆(Global Memory):门控更新
这是CoMeT的“长期存储”。它不像传统RNN那样简单地覆盖旧状态,而是引入了类似LSTM的门控更新机制(Gated Update Rule)。
-
作用:专门捕捉长距离依赖。门控机制会智能地判断:哪些新信息需要写入?哪些历史核心信息必须保留?
-
公式:全局状态的更新公式为 $\mathbf{S}^{i}_{\tau+1}=\mathbf{g}\odot\mathbf{S}^{i}_{\tau}+(\mathbf{1}-\mathbf{g})\odot\tilde{\mathbf{S}}^{i}_{\tau+1}$,其中 $\mathbf{g}$ 是门控权重。这有效防止了重要历史信息被后续无关信息“冲刷”掉。
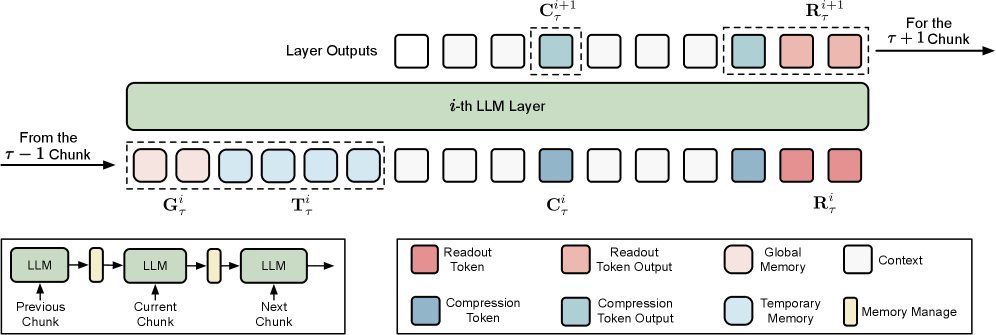
如上图所示,在处理每一个文本块时,模型会同时参考全局记忆 $\mathbf{G}^{i}_{\tau}$ 和临时记忆 $\mathbf{T}^{i}_{\tau}$,从而兼顾了全局大局观和局部细节。
32k训练,1M推理:惊人的泛化能力
CoMeT最令人印象深刻的特性是其强大的外推能力。研究人员仅在32k长度的上下文上对模型进行了微调,然后直接在1M(100万)Token的长度上进行测试。
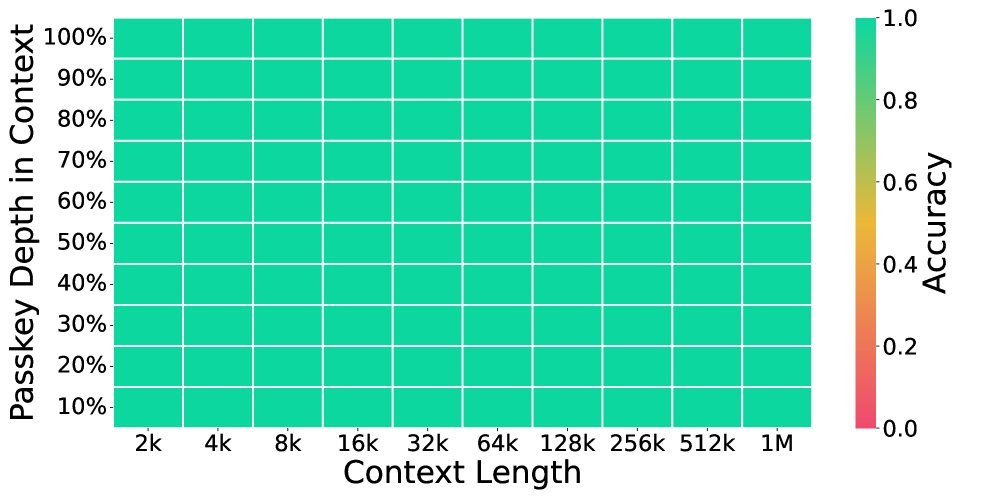
结果如何?请看下图的“大海捞针”(Passkey Retrieval)测试:
-
全绿的准确率:图1(a)显示,无论密钥(Passkey)隐藏在1M上下文的哪个位置,CoMeT都能准确找回,准确率接近100%。
-
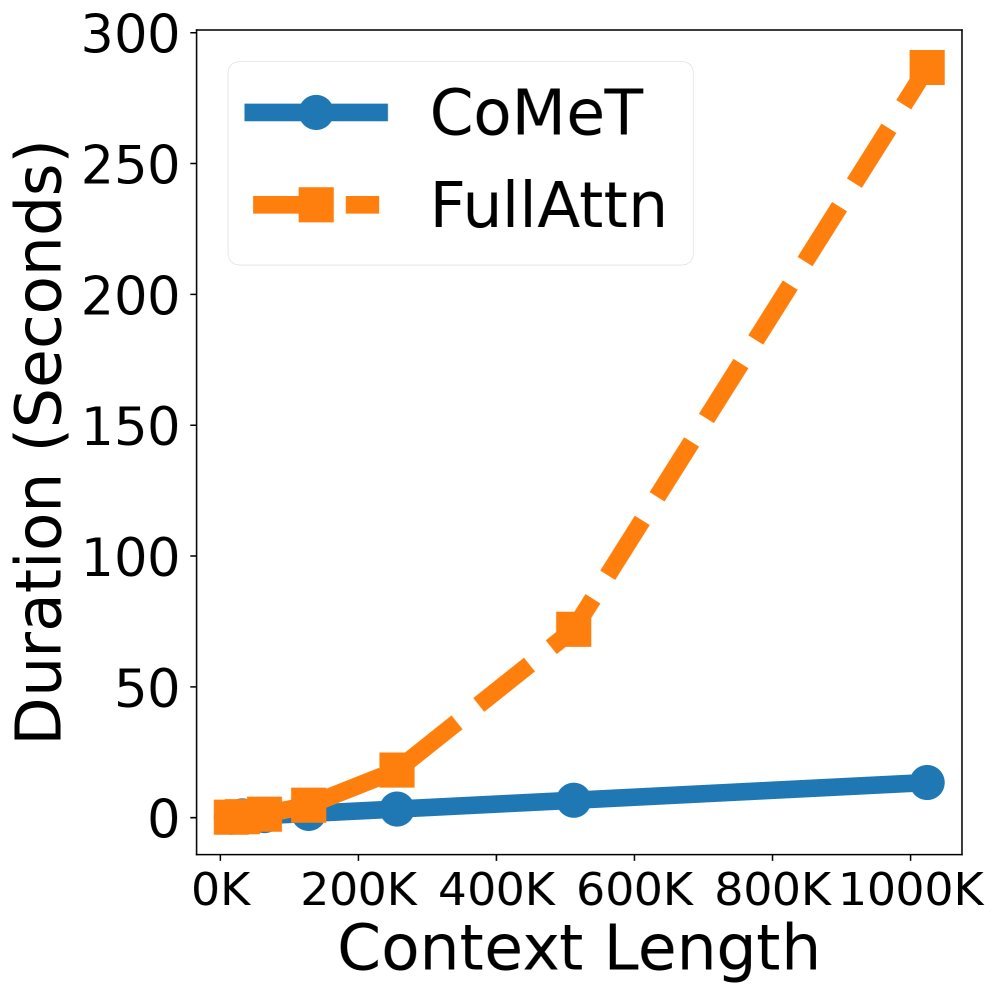
线性的推理时间:图1(b)显示,随着长度增加,CoMeT的推理时间仅呈线性增长,而全注意力机制(Full Attention)则是指数级暴涨。
-
恒定的显存占用:图1(c)最为震撼,无论上下文是10万还是100万,CoMeT的显存占用始终保持在一条水平线上(约10GB),而Full Attention在128k时就已经OOM(显存溢出)了。
训练加速:层级流水线并行
为了让CoMeT能在超长上下文上高效训练,团队还提出了一种层级流水线并行策略(Layer-level Pipeline Parallelism)。
传统的上下文并行(Context Parallelism)在处理序列块时,Worker之间存在严重的等待时间(气泡)。而CoMeT的新策略将不同层的计算流水线化,使得训练速度相比朴素方法提升了2.7倍。这意味着,仅用16张80GB的GPU,就能高效微调128k长度的模型。
实验表现:不仅快,而且准
在SCROLLS长文本基准测试中,CoMeT的表现超越了其他高效方法(如LongLLMLingua、Transformer-XL等),并在摘要任务上达到了与全注意力基线相当的水平。
特别是在真实世界的应用场景——用户行为序列QA中,CoMeT展现了巨大的实用价值。面对电商场景下成千上万条用户交互记录,CoMeT能精准捕捉用户的兴趣点,性能显著优于工业界常用的xRAG和简单的截断策略。
总结
CoMeT的出现,打破了长文本处理中“效率”与“性能”不可兼得的魔咒。
-
对于开发者:它是一个即插即用的模块,改造成本极低。
-
对于资源受限的场景:它让在单卡上处理百万级上下文成为可能。
随着AI Agent和长文档分析需求的爆发,CoMeT这种“恒定显存、无限长度”的架构,或许正是通往下一代高效大模型的关键钥匙。