Mistral AI新作QuacK:不靠归一化,动态学习率让Transformer训练提速10%

Transformer模型的训练过程,有时就像驾驶一辆狂野的赛车,稍有不慎就可能“翻车”——训练过程突然崩溃,损失函数(Loss)直接飙升到无穷大。为了驯服这头性能猛兽,研究者们想出了各种办法,其中最著名的当属QK Norm。然而,这个“稳定器”并非万能,在一些更高效的注意力机制(如MLA)中会“水土不服”。
ArXiv URL:http://arxiv.org/abs/2511.21377v1
现在,来自Mistral AI和布里斯托大学的研究者们提出了一种全新的思路:与其强行限制注意力得分的大小,不如去控制它的“变化速度”!
这个名为QuacK的简单方法,不仅成功稳住了训练过程,甚至在某些场景下比QK Norm还要快10%,并且完美兼容各种新式注意力架构。
问题的根源:失控的注意力权重
Transformer训练不稳定的一个主要元凶,是自注意力机制中的Query($Q$)和Key($K$)权重矩阵。在训练中,它们的数值(范数)会不受控制地增长,导致计算出的注意力Logits $L$ 过大,进而引发梯度爆炸和训练崩溃。
\[\mathbf{L}=\frac{\mathbf{Q}\mathbf{K}^{T}}{\sqrt{d}}\]为了解决这个问题,QK Norm应运而生。它通过在计算$Q$和$K$后强制进行归一化,把它们的范数限制在可控范围内,从而保证了训练的稳定性。
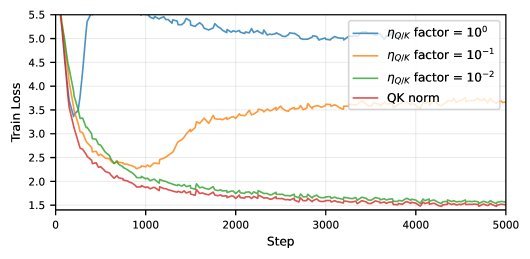
图1:仅需降低Q/K权重的学习率,就能在极高的基础学习率下稳定训练过程
但QK Norm有个前提:它需要在推理时完整计算出$Q$和$K$矩阵。这对于多样本上下文学习(Multi Latent Attention, MLA)这类为了效率而不完全实例化$Q$和$K$的先进架构来说,是无法接受的。
有没有一种更通用、更轻量级的稳定方案呢?
QuacK:控制变化而非控制大小
这篇研究的思路发生了根本性转变:我们真的需要严格限制Logits的大小吗?也许,真正导致不稳定的是Logits在训练步骤之间的剧烈变化($\Delta L$)。
研究者们从最大更新参数化(Maximal Update Parametrization, $\mu$P)中获得灵感,发现可以通过动态调整$Q$和$K$权重矩阵的学习率来控制$\Delta L$。
核心思想出奇地简单:
-
Query权重($W_Q$)的学习率,与其“搭档”Key权重($W_K$)的范数成反比。
-
Key权重($W_K$)的学习率,也与其“搭档”Query权重($W_Q$)的范数成反比。
用公式表达就是:
\[\eta_{Q}\propto\ \mid \mathbf{W}_{K}\ \mid ^{-1},\;\;\eta_{K}\propto\ \mid \mathbf{W}_{Q}\ \mid ^{-1}\]这意味着,当$W_K$的范数变大时,我们就自动调小$W_Q$的学习率,减缓它的更新步伐,从而抑制两者乘积(即Logits)的剧烈变化。反之亦然。
这个方法被命名为QuacK,它的实现极其简单,只需在优化器更新参数前,根据对方权重的当前范数动态调整学习率即可,几乎是“零成本”的即插即用改进。
实验效果:稳定、高效、兼容
那么,QuacK的实际效果如何?研究者在一个1B参数模型上进行了预训练实验,结果令人印象深刻。
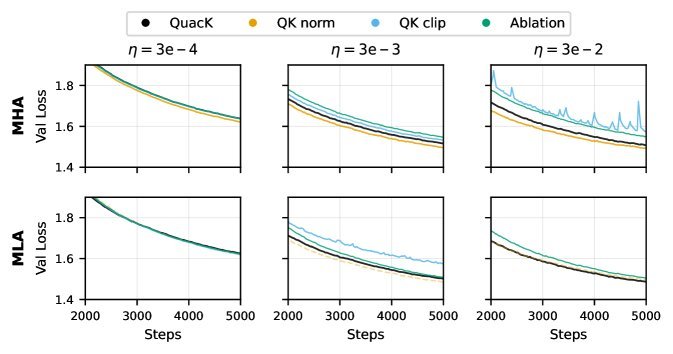
图2:QuacK在各种设置下均表现稳定,尤其在高学习率和MLA场景下优势明显
-
超强稳定性:在高达\(3e-2\)的超高学习率下,其他方法(如QK clip)早已崩溃,而QuacK依然稳如泰山,表现出与QK Norm相媲美的稳定性。
-
性能与效率双赢:
-
在标准多头注意力(Multi-Head Attention, MHA)设置下,QuacK的性能与QK Norm相当。但由于它省去了两次RMS Norm计算,训练速度提升了约10%!
-
在QK Norm不适用的MLA设置下,QuacK的表现远超其他备选方案,充分展示了其兼容性和实用价值。
-
核心优势与未来展望
总结来说,QuacK的核心优势在于:
-
理念新颖:从控制“Logits变化量”而非“Logits大小”入手,为训练稳定问题提供了新视角。
-
实现简单:无需复杂的归一化层或定制化的CUDA Kernel,几行代码即可集成。
-
高效通用:不仅训练更快,还完美兼容MLA等高效注意力架构,解决了QK Norm的局限。
当然,该研究也承认其局限性,如实验仅在单一模型和数据集上进行,且训练步数较短。但它无疑为我们揭示了一条充满前景的道路。
QuacK证明了,有时候最优雅的解决方案并非来自复杂的模块堆砌,而是源于对问题本质的深刻洞察。通过巧妙地“驾驭”学习率,我们就能让Transformer这匹烈马跑得又快又稳。