CRoPE: Efficient Parametrization of Rotary Positional Embedding
RoPE“瘦身”术:砍掉Attention层50%参数,性能却几乎无损

Transformer 架构如今已是大语言模型的绝对基石,而 旋转位置编码(Rotary Positional Embedding, RoPE) 更是其中的“标配”。从 LLaMA 到 DeepSeek,几乎所有主流开源模型都采用了 RoPE 来处理序列的位置信息。
ArXiv URL:http://arxiv.org/abs/2601.02728v1
然而,来自斯坦福大学和 d-Matrix 的研究人员最近提出了一个颠覆性的观点:我们目前对 RoPE 的实现方式,可能存在巨大的参数浪费。
这篇名为《CRoPE: Efficient Parametrization of Rotary Positional Embedding》的论文指出,虽然 RoPE 在数学形式上借用了复数旋转的概念,但在代码实现中,我们通常还是使用实数矩阵来进行 $Q/K/V$ 的线性投影。这种做法实际上赋予了模型“过剩”的表达能力。研究表明,通过回归复数域的本质,我们可以将 Attention 模块中投影层的参数量直接砍掉 50%,而模型性能几乎没有任何损失。
重新审视 RoPE:复数视角的回归
RoPE 的核心直觉非常优雅:通过将词向量旋转一定的角度来编码相对位置信息。在数学公式中,这通常表示为复数乘法:$f(x, m) = x \cdot e^{im\theta}$。
但是,在实际的 Transformer 实现(如 PyTorch 代码)中,我们并没有直接使用复数神经网络。相反,我们是在实数域中操作。对于 $Q$、$K$、$V$ 的投影矩阵 $\mathbf{W}$,我们通常将其视为一个标准的实数线性层。
论文作者敏锐地发现,这种“实数实现”与 RoPE 的“复数本质”之间存在不匹配。
如果我们将嵌入向量看作是复数向量(将每两个实数维度组合成一个复数),那么标准的实数线性变换实际上比复数线性变换要“宽泛”得多。
具体来说,一个复数线性变换 $\tilde{y} = \tilde{w}\tilde{x}$(其中 $\tilde{w}, \tilde{x}$ 均为复数),如果展开成实数矩阵形式,具有特殊的结构:
\[{\mathbf{W}}_{CRoPE}=\begin{pmatrix}a & b \\ -b & a \end{pmatrix}\]这就意味着,对于每一对维度,我们只需要 $a$ 和 $b$ 两个参数。然而,在标准的实数全连接层中,一个 $2 \times 2$ 的子矩阵有 4 个自由参数($a, b, c, d$):
\[{\mathbf{W}}_{Standard}=\begin{pmatrix}a & b \\ c & d \end{pmatrix}\]CRoPE(Complex RoPE)的核心思想就是:强制 $Q/K/V$ 投影矩阵遵循复数乘法的结构。通过这种方式,每处理一对维度,我们只需要存储 2 个参数而不是 4 个。这直接导致了投影层参数量减少了 50%。
我们到底“砍”掉了什么?
减少参数通常意味着模型表达能力的下降。那么,CRoPE 砍掉的那一半参数,原本是干什么用的呢?
为了回答这个问题,论文从几何角度进行了深入分析。对于二维平面上的向量,一个通用的 $2 \times 2$ 实数矩阵可以实现以下变换的组合:
-
旋转(Rotation)
-
缩放(Scaling)
-
反射(Reflection,即镜像)
-
剪切(Shearing)
而 CRoPE 所对应的复数乘法,在几何上仅对应于 旋转 和 缩放。
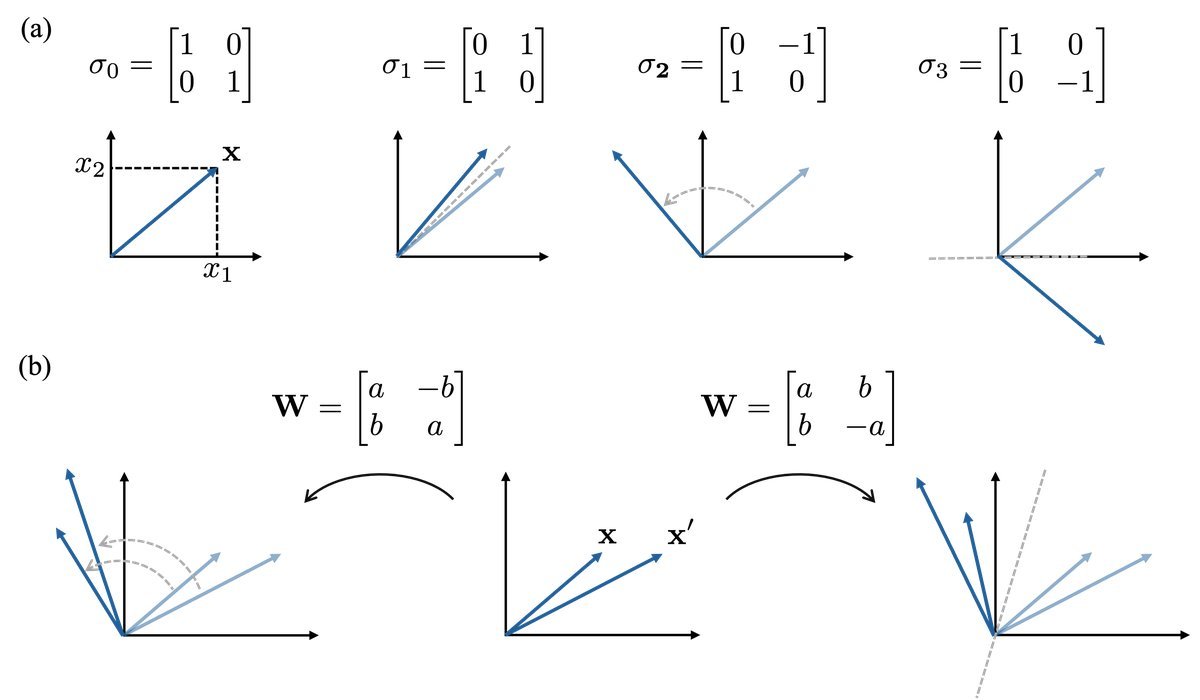
如上图所示,CRoPE 的函数空间(左图)保留了旋转和缩放能力,但丢失了反射能力(右图)。
关键问题来了:Transformer 的注意力机制真的需要“反射”能力吗?
作者通过理论推导和简单的合成任务证明,对于 Token 匹配(关注相似 Token)和位置匹配(关注特定相对位置)这两个核心功能,旋转和缩放已经完全足够了。反射操作对于混合 Token 内容和位置信息并不是必须的。
换句话说,标准 RoPE 实现中多出的那 50% 参数,很多时候是在学习如何进行“反射”等操作,而这些操作对于语言建模任务来说可能是冗余的。CRoPE 通过一种更强的归纳偏置(Inductive Bias),帮模型“省去”了这部分不必要的学习负担。
实验验证:参数减半,效果不减
理论分析听起来很美,实际效果如何?
研究团队在 WikiText-2、Penn Treebank 和 PG-19 等数据集上,使用 GPT-2 架构进行了对比实验。他们将标准 RoPE 模型的 $Q/K/V$ 投影层替换为 CRoPE 结构(即参数量减半),然后从头开始训练。
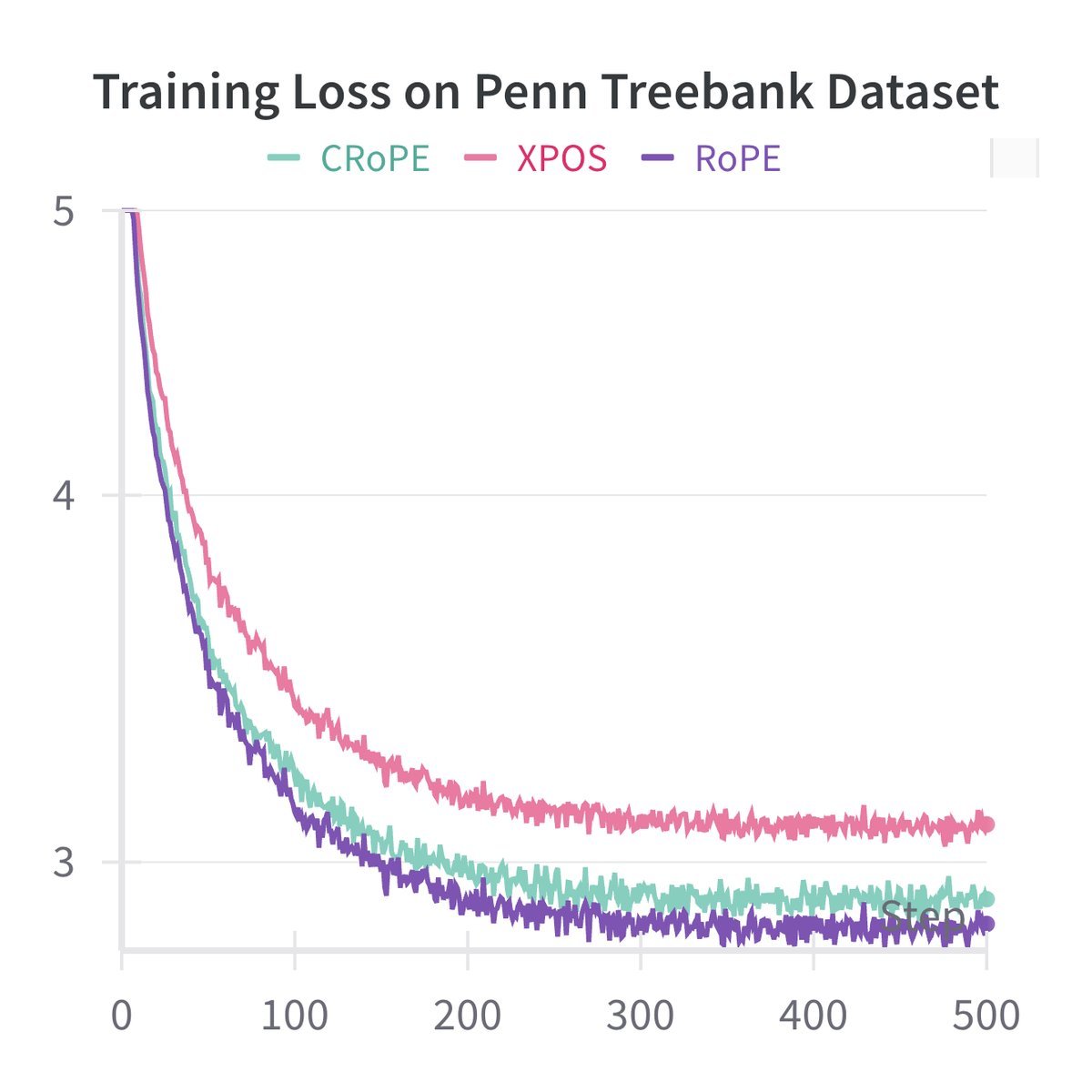
上图展示了在 WikiText-2 数据集上的验证损失(上)和训练损失(下)。
-
蓝色线:标准 RoPE
-
橙色线:CRoPE
-
绿色线:XPOS(另一种位置编码)
结果令人惊讶:CRoPE 的曲线与标准 RoPE 几乎完全重合。尽管参数量大幅减少,但模型在训练集内(In-sample)和训练集外(Out-of-sample)的表现都没有出现明显的下降。在 PG-19 等长文本数据集上,结论依然成立。
总结与启示
CRoPE 的提出为我们优化 Transformer 架构提供了一个极佳的视角。它不仅仅是一个参数压缩技巧,更是一次对位置编码本质的深度思考。
-
效率提升:在 Attention 模块内部,CRoPE 实现了近乎 50% 的参数缩减。虽然对于整个大模型来说(考虑到 FFN 层和 Embedding 层),总参数量的减少比例不到 50%,但这依然是一个显著的瘦身。
-
更自然的参数化:复数形式可能是处理旋转位置编码更“自然”的方式。去除冗余的自由度(如反射),反而可能让优化过程更加直接。
-
兼容性:CRoPE 是一种架构层面的改进,它与现有的量化(Quantization)、剪枝(Pruning)等技术完全兼容,可以叠加使用。
在追求大模型“大”的今天,CRoPE 提醒我们,有时候“小”而“精”的数学直觉,能带来意想不到的惊喜。也许,我们的模型中还隐藏着更多像“反射”这样从未被用到的冗余能力,等待着被优化。