AI当上CUDA工程师:性能超NVIDIA官方库26%,CUDA-L2来了!

在AI的世界里,从大模型训练到推理,几乎所有计算的核心都离不开一个基础操作:矩阵乘法。为了榨干GPU的每一滴性能,NVIDIA的工程师们用数十年经验打造了像cuBLAS这样神级的官方优化库。大家普遍认为,这已经是人类优化的天花板。但如果说,一个AI系统现在能自动写出比cuBLAS更快的代码,你敢信吗?
ArXiv URL:http://arxiv.org/abs/2512.02551v1
这正是DeepReinforce团队最新研究CUDA-L2所实现的目标。该研究表明,通过结合大语言模型(LLM)和强化学习(RL),AI不仅能编写CUDA代码,甚至能在最关键的矩阵乘法任务上,系统性地超越NVIDIA官方高度优化的闭源库,在某些场景下性能提升高达26%!
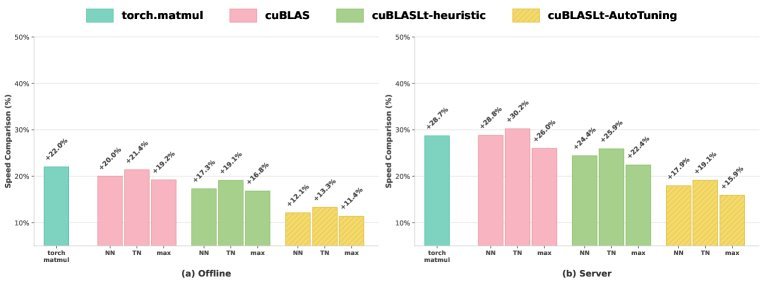
图1:CUDA-L2在1000种不同矩阵尺寸配置下的性能表现,分别对比了torch.matmul, cuBLAS, cuBLASLt-heuristic, 和 cuBLASLt-AutoTuning。
矩阵乘法优化的“珠穆朗玛峰”
为什么矩阵乘法优化如此之难?
首先,它的性能对矩阵的维度($M, N, K$)极其敏感。一个在特定尺寸下表现优异的优化策略,换个尺寸可能就判若两人。
其次,不同的GPU架构(如Ampere, Hopper, Blackwell)硬件特性迥异,一个架构上的“神优化”很难直接搬到另一个上。
这导致手动优化的工作量巨大,几乎不可能为成千上万种配置和不同GPU都找到最优解。尽管cuBLAS已经做得非常出色,但它依然像一个“黑盒”,无法做到对所有情况都完美。这为AI自动化优化留下了宝贵的探索空间。
CUDA-L2:LLM与强化学习的强强联合
CUDA-L2并非凭空出世,它是在其前身CUDA-L1的基础上,针对矩阵乘法这一硬骨头进行了多项关键升级。可以把CUDA-L2想象成一个不断学习、自我进化的“AI CUDA工程师”。
它的训练过程分为几个核心阶段:
-
海量代码预训练:首先,研究团队让一个强大的基础模型(DeepSeek 67B)学习了海量的CUDA代码。这些代码不仅来自网络,还包括PyTorch、CUTLASS等高质量库的实现。这让AI对CUDA编程有了广泛而深入的理解。
-
通用能力强化学习:接着,AI进入第一阶段的强化学习。它尝试优化各种通用的CUDA核函数(如卷积、池化等),并以代码的“执行速度”作为奖励信号。跑得越快,奖励越高。这锻炼了它通用的代码优化能力。
-
专精领域强化学习:最后,AI进入专精训练阶段,火力全开,专注于半精度矩阵乘法(Half-precision General Matrix Multiply, HGEMM)。它在1000种不同的矩阵尺寸组合上反复生成代码、编译、运行、评估速度,并根据结果进行迭代。
在这个过程中,CUDA-L2还引入了两大“秘密武器”:
-
更丰富的决策信息:除了速度,AI还会参考NVIDIA Nsight Compute工具提供的详细性能指标,如内存吞吐、SM占用率、缓存效率等,从而做出更精细的优化决策。
-
检索增强生成(RAG):为了让AI能跟上最新的硬件和技术(比如新的GPU架构或CUTLASS库版本),CUDA-L2整合了检索能力,让模型能随时查阅新知识。
惊人的性能超越
是骡子是马,拉出来遛遛。CUDA-L2直接挑战了当前最主流、最强大的几个基准:
-
\(torch.matmul\): PyTorch用户的默认选择。
-
\(cuBLAS\): NVIDIA官方高性能库,行业标准。
-
\(cuBLASLt-heuristic\): cuBLASLt库的启发式推荐算法。
-
\(cuBLASLt-AutoTuning\): cuBLASLt的“自动调优”模式,它会测试多达100个候选算法,并选出最快的那个,是目前公认最强的基准之一。
评测在两种模式下进行:离线模式(Offline),模拟GPU满负荷持续计算;服务器模式(Server),模拟真实世界中请求随机到达的场景。
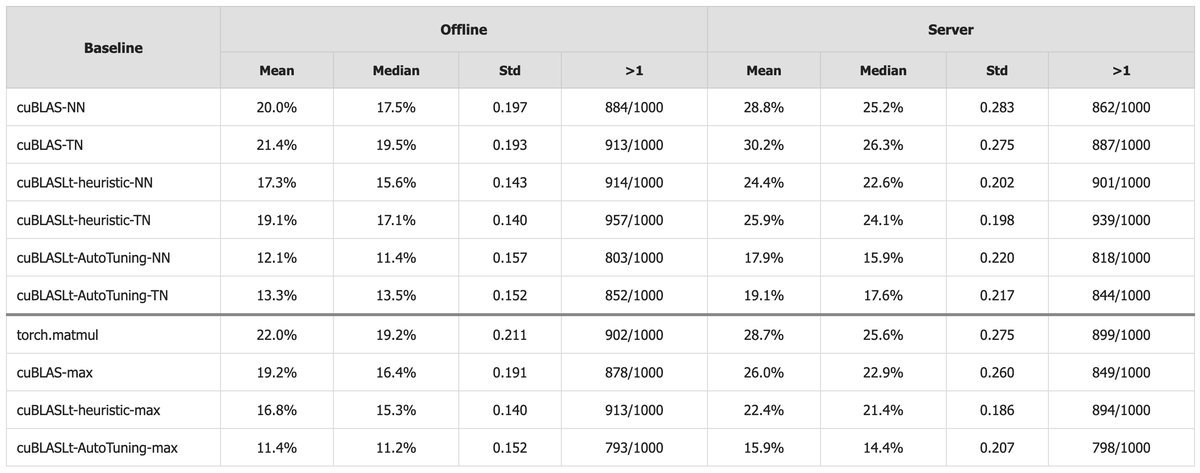
表1:CUDA-L2相较于各大基准的性能加速比。
结果令人震撼:
-
全面超越:在所有1000个配置的平均性能上,CUDA-L2全面胜出。
-
离线模式:相较于最强的\(cuBLASLt-AutoTuning\),CUDA-L2平均提速11.4%。对比更常用的\(cuBLAS\),提速更是高达19.2%。
-
服务器模式:性能优势进一步扩大!由于真实场景下GPU缓存会变冷,CUDA-L2生成的核函数适应性更强。对比\(cuBLAS\),提速达到惊人的26.0%;对比\(cuBLASLt-AutoTuning\),提速也达到了15.9%。
这意味着,在模拟真实推理服务的场景下,AI生成的代码比NVIDIA官方最强的自动调优库还要快近16%!
AI学会了哪些优化绝技?
CUDA-L2的成功并非偶然。通过分析AI生成的代码,研究人员发现它自主“领悟”并应用了许多高级的优化技巧。
一个有趣的发现是,CUDA-L2学会了根据问题规模选择不同的实现策略。
对于小尺寸矩阵,GPU很容易“吃不饱”,此时计算不是瓶颈,访存和调度开销才是。CUDA-L2会生成更轻量级的代码,直接使用底层的WMMA(Wavefront Matrix Multiply-Accumulate)指令,减少不必要的抽象和开销。
这种“因地制宜”的智慧,恰恰是人类专家进行优化的精髓,而现在,AI也学会了。
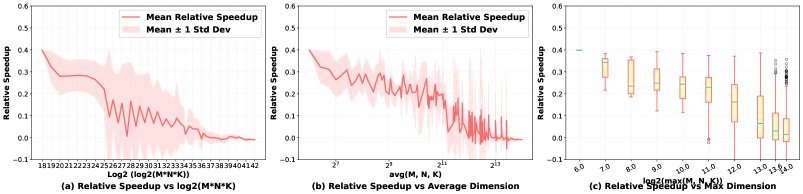
表3:在离线模式下,CUDA-L2相对于cuBLASLt-AutoTuning在不同矩阵尺寸下的加速比。
从上表可以看出,CUDA-L2在中小尺寸矩阵上的优势尤为明显,这正是许多大模型中Attention和FFN层常见的计算规模。
结语
CUDA-L2的出现,标志着AI在底层系统优化领域迈出了里程碑式的一步。它证明了即使是在矩阵乘法这样被人类专家优化到极致的领域,LLM引导的自动化探索仍然能发现新的性能提升空间。
目前,这项研究主要在NVIDIA A100 GPU上进行,但其框架具有通用性。团队正在努力将其扩展到更多GPU架构,包括RTX 4090、H100乃至最新的Blackwell B200。
或许在不远的将来,为特定硬件编写和优化底层代码的繁重工作,将越来越多地由AI工程师来完成,而人类开发者则能更专注于算法和架构的创新。一个由AI驱动的软件性能优化新时代,正悄然来临。