数据智能体“高考”来了!字节跳动DAComp揭示:顶级模型成功率不足20%

AI Agent正以前所未有的速度渗透到各个领域,尤其是在数据处理方面,人们期待它能像资深专家一样,自动完成从原始数据到商业洞察的全过程。但它们真的准备好了吗?最近,一份来自字节跳动、中国科学院等机构联合发布的“数据智能体高考卷”——DAComp,给所有顶尖大模型泼了一盆冷水。测试结果显示,即使是GPT-4/5级别的先进模型,在模拟真实企业级数据任务时也步履维艰,在最复杂的数据工程任务上,端到端成功率竟不足20%!
ArXiv URL:http://arxiv.org/abs/2512.04324v1
这究竟是一份怎样的“魔鬼考卷”?它又揭示了当前AI Agent发展的哪些核心瓶颈?
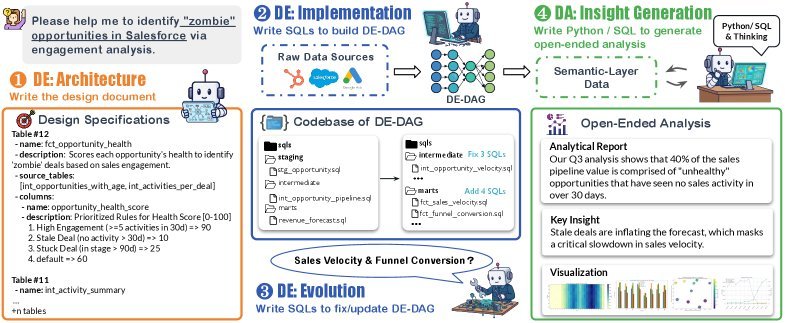
图1: DAComp旨在评估大模型在完整数据智能生命周期中的表现,涵盖数据工程(DE)和数据分析(DA)
DAComp:不止是代码生成,更是真实世界的试炼场
以往的基准测试,大多将数据任务简化为孤立的代码生成,比如Text-to-SQL。这就像只考学生“单词默写”,却忽略了“阅读理解”和“命题作文”的能力。
DAComp则完全不同,它首次构建了一个覆盖数据智能全生命周期(full-lifecycle data intelligence)的综合性基准,包含210个高难度任务。它将AI Agent置于两个真实的企业角色中进行考验:
-
数据工程师(Data Engineer):负责“硬核”的工程实现。这不仅是写几行SQL,而是要在一个包含数十个文件、数千行代码的代码仓库(Repository)中,从零开始构建或修改复杂的多阶段数据处理流水线(Pipeline)。
-
数据分析师(Data Analyst):负责“开放”的分析推理。面对一个开放式的商业问题(如“如何提升用户渗透率和盈利能力?”),需要自主规划分析步骤、探索数据、解读结果,并最终形成包含图表和可行性建议的分析报告。
简单来说,DAComp同时考察了AI Agent的工程落地硬实力和分析洞察软实力。
DAComp-DE:数据工程师的“硬核”挑战
数据工程(DAComp-DE)任务的复杂度是前所未有的。它模拟了企业中真实的数据仓库建设场景,平均每个任务涉及32个表、412个列,解决方案的代码量动辄超过2000行。
具体任务类型包括:
-
DE-Architecture:规划详细的工程规范,考验高层设计能力。
-
DE-Implementation:从零开始构建一个完整的多层数据流水线。
-
DE-Evolution:根据新的业务需求,修改一个已存在的复杂系统。
为了精准评估,研究者设计了三级递进的执行评估指标:
-
组件得分(CS):独立评估每个代码组件的正确性,衡量单点代码生成能力。
-
级联失败得分(CFS):按数据流(DAG)顺序评估,一旦上游节点出错,下游即为0分。这能有效衡量端到端数据完整性,模拟“一步错,步步错”的真实场景。
-
严格成功率(SR):要求流水线中所有组件全部完美正确,是最严苛的指标。
DAComp-DA:数据分析师的“开放”考题
数据分析(DAComp-DA)任务则彻底告别了“标准答案”。它要求Agent像真正的数据分析师一样,进行开放式探索。
这项任务的评估是另一个亮点。研究团队开创性地设计了一套分层级、多路径的评估框架(hierarchical rubrics),并由LLM-judge进行打分。
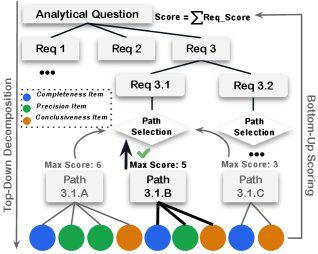
图2: 分层级评估框架细节
这意味着什么呢?对于同一个商业问题,优秀的分析师可能有多种不同的分析思路。这套评估框架预设了多种有效的“解题路径”(solution paths)。LLM-judge会判断Agent的回答与哪条路径最匹配,并仅根据该路径的标准进行打分。这既保证了评估的客观性,又鼓励了分析策略的多样性。
评估维度不仅包括准确性(Accuracy)和完整性(Completeness),更包含了洞察力(Insightfulness)、可读性(Readability)、分析深度(Analytical depth)和可视化(Visualization)等软性指标。
成绩单出炉:顶级Agent为何纷纷“折戟”?
实验结果令人震惊。无论是开源模型(如Qwen3, DeepSeek-V3.1)还是闭源的顶尖模型(如GPT和Gemini系列),在DAComp上都表现不佳。
数据工程(DE):整体编排能力是最大瓶颈
在DE任务上,即便是最强的GPT-5,其综合得分也仅为42.88%,严格成功率更是低至20%。
一个关键发现是,从组件得分(CS)到级联失败得分(CFS)出现了断崖式下跌。例如,GPT-5在Implementation任务中CS为61.85,但CFS骤降至30.49。
这说明,当前Agent的最大瓶颈并非生成单个正确的代码片段,而是在复杂的代码仓库中进行整体的、端到端的流水线编排和依赖管理能力。
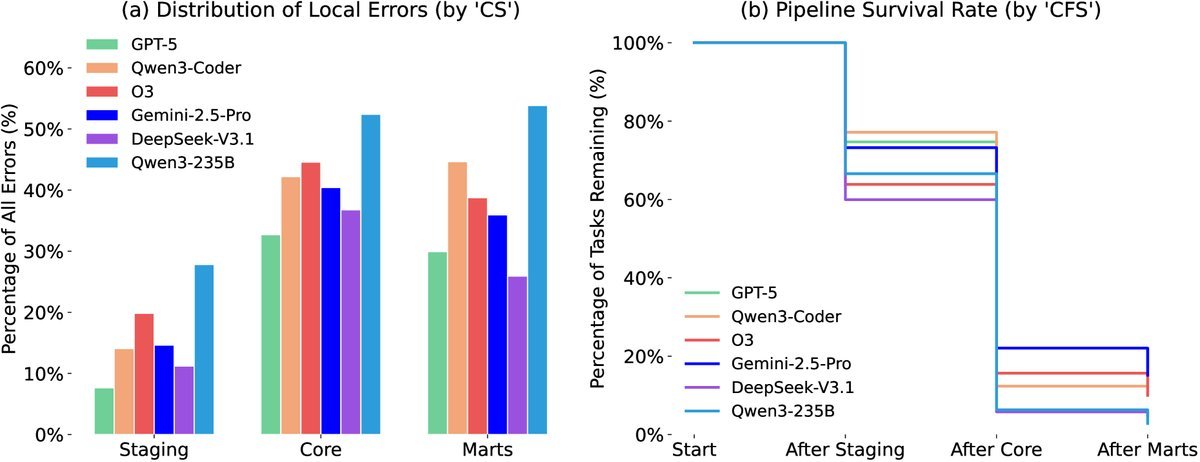
图5: 错误分布(左)与流水线存活率(右)
从上图可以看出,错误主要集中在逻辑更复杂的中间层(core),并且错误会像滚雪球一样传递下去,导致整个流水线在到达终点(marts)前就已“阵亡”。
数据分析(DA):“会算数”不等于“有洞察”
在DA任务上,表现最好的模型总分也仅为56.14%。
分析发现,高下之分主要体现在分析深度和洞察力上。一些模型表现出明显的“计算器行为”:它们能准确地计算出数字(Accuracy得分高),却无法将这些数字合成为有条理、有洞察、人类易读的分析报告(Readability和Depth得分极低)。
这表明,开放式的数据分析需要超越纯粹代码生成的综合推理能力,而这正是许多模型的短板。
错误分析:依赖管理与错误级联是两大“杀手”
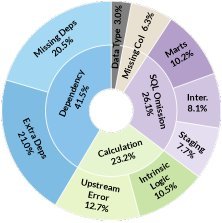
图7: DE任务的错误分析
深入的错误分析揭示了两个主要问题:
-
依赖管理失败:Agent在修改或创建代码时,常常忘记更新相关的依赖项,或者错误地处理数据血缘关系,这是导致流水线崩溃的首要原因。
-
错误级联效应:上游组件的一个小错误(如计算逻辑错误)会像瘟疫一样传播到下游,导致后续所有分析都基于错误数据,最终整个任务失败。在表现较好的模型中,由上游传播而来的错误数量是其自身产生错误的三倍之多。
结语
DAComp的发布,无疑为火热的AI Agent领域提供了一剂“清醒剂”。它用无可辩驳的数据证明,从生成孤立的代码片段到成为能够自主处理复杂企业级任务的“数据智能体”,我们还有很长的路要走。
这份“高考卷”的意义不仅在于揭示了短板,更在于指明了方向。未来的研究需要从关注单点技能,转向提升Agent的整体规划、系统级编排、开放式推理和深度洞察等综合能力。只有这样,我们才能真正迈向由AI驱动的数据智能新时代。