Data-Efficient RLVR via Off-Policy Influence Guidance
-
ArXiv URL: http://arxiv.org/abs/2510.26491v1
-
作者: Jie Tang; Dazhi Jiang; Aohan Zeng; Minlie Huang; Yuxian Gu; Yilin Niu; Erle Zhu; Yuan Wang; Xujun Li; Jiale Cheng; 等11人
-
发布机构: Tsinghua University; Z. AI
TL;DR
本文提出了一种名为CROPI的数据高效强化学习框架,通过一种新颖的离策略影响函数估计方法,以极低的计算成本识别并挑选对模型训练最有价值的数据,从而在大型语言模型的推理能力训练中实现显著的加速。
关键定义
- 强化学习与可验证奖励 (Reinforcement Learning with Verifiable Rewards, RLVR):一种训练大型语言模型(LLM)进行推理任务的范式。在此范式中,模型的推理过程被建模为马尔可夫决策过程,并通过给予最终答案正确与否的可验证奖励(如正确为1,错误为0)来进行强化学习。
- 影响函数 (Influence Functions):一种理论上成熟的方法,通过分析单个数据点对学习目标的贡献来评估其重要性。本文中,它被用来衡量一个训练数据点(问题)对模型在另一个测试数据点上性能表现的影响,具体通过计算两者策略梯度的内积来实现。
- 离策略影响估计 (Off-Policy Influence Estimation):本文提出的核心技术。传统影响函数计算需要昂贵的在线策略梯度,这在LLM中不可行。该方法利用预先收集的离线轨迹(由一个固定的行为策略生成)来近似估算当前在线策略的梯度,从而避免了实时生成轨迹(rollout)的巨大开销。
- CROPI (Curriculum RL with Off-Policy Influence guidance):本文提出的多阶段课程学习框架。该框架在每个训练阶段,利用“离策略影响估计”为所有训练数据评分,然后选择得分最高的一部分数据用于下一阶段的策略优化,从而形成一个动态的、由数据影响力驱动的学习课程。
相关工作
当前,在LLM的RLVR训练中,数据选择方法主要依赖启发式规则,例如根据任务难度或模型输出的不确定性来筛选数据。这些方法虽然在某些场景有效,但普遍缺乏理论保证,并且在不同任务和模型间的泛化能力较差。
应用影响函数这一更具理论基础的方法,面临一个巨大障碍:计算影响函数需要获取策略梯度,而为LLM计算策略梯度需要进行策略“rollout”(即模型根据当前策略生成完整的解题步骤),这一过程计算成本极高,使得在线、实时地评估每个数据点的影响力变得不切实际。
本文旨在解决的核心问题是:如何将影响函数这种强大的数据评估工具应用于LLM的RLVR训练中,同时规避其高昂的计算成本,从而实现高效的数据选择和训练加速。
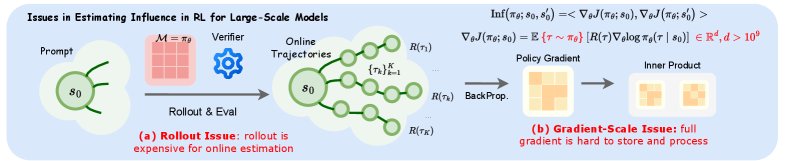
本文方法
为了解决上述挑战,本文提出了一套名为CROPI的课程学习框架,其核心在于一种高效的“离策略影响估计”方法和一种用于处理高维梯度的“稀疏随机投影”技术。
创新点:离策略梯度估计
本文方法的最大创新在于提出了一种无需在线Rollout的离策略梯度估算方法。其核心思想是,利用一个固定的行为策略 \($\beta\)$(在实践中,使用训练开始前的初始策略 \($\pi\_{\theta\_0}\)$)预先为数据集中的每个问题生成一批解答轨迹。在后续的训练过程中,当需要评估某个数据点对当前策略 \($\pi\_{\theta}\)$ 的影响时,不再需要用 \($\pi\_{\theta}\)$ 去重新生成轨迹,而是直接利用预先存储的由 \($\beta\)$ 生成的轨迹来估算梯度。
\($\pi\_{\theta}\)$ 的策略梯度 \($\nabla\_{\theta}J(\theta;s\_0)\)$ 可以通过一个离策略估计器 \($\widehat{g}\_{\beta}\)$ 来近似:
\[\widehat{g}_{\beta}(\theta,s_{0},\{\tau_{k}\}_{k=1}^{K}) \approx\frac{1}{K}\sum_{k=1}^{K}\frac{1}{ \mid \tau_{k} \mid }\sum_{t=0}^{ \mid \tau_{k} \mid -1}\nabla_{\theta}\rho_{k,t}^{\pi_{\theta}}\widehat{A}^{\beta}_{k,t}\]其中,\($\rho\_{k,t}^{\pi\_{\theta}} = \frac{\pi\_{\theta}(x\_{k,t} \mid s\_{k,t})}{\beta(x\_{k,t} \mid s\_{k,t})}\)$ 是重要性采样权重,\($\widehat{A}^{\beta}\_{k,t}\)$ 是基于行为策略 \($\beta\)$ 计算的优势函数。由于在线RL训练通常会用KL散度约束 \($\pi\_{\theta}\)$ 与初始策略的距离,这保证了该离策略估计的相对准确性。
通过这种方式,数据点 \($s\_0\)$ 对验证点 \($s\_0^{\prime}\)$ 的影响 \($\text{Inf}(\pi\_{\theta};s\_{0},s\_{0}^{\prime})\)$ 可以通过计算它们各自的离策略梯度估计值的内积来高效获得:
\[\widehat{\text{Inf}}_{\beta}(\pi_{\theta};s_{0},s_{0}^{\prime}) =\widehat{g}_{\beta}(\theta,s_{0})^{\top}\widehat{g}_{\beta}(\theta,s_{0}^{\prime})\]这种方法将原本需要昂贵在线计算的动态过程,转化为了基于离线数据的轻量级计算。
创新点:稀疏随机投影
LLM的梯度维度极高,直接存储和计算内积的开销巨大。为解决此问题,本文采用了稀疏随机投影技术。与标准随机投影不同,该方法并非对整个梯度向量进行投影,而是:
- 随机丢弃 (Dropout):首先从梯度向量的所有维度中随机选择一小部分(例如10%)。
- 投影:仅将这部分被选中的维度投影到一个更低的维度空间。
实验表明,这种“先丢弃再投影”的稀疏化操作,反直觉地比直接对完整梯度进行投影更能保持梯度之间相似度的排序,作者推测这可能与高维梯度中存在的数值噪声有关,稀疏化操作可能过滤了部分噪声。
CROPI框架
基于上述技术,本文构建了CROPI(Curriculum RL with Off-Policy Influence Guidance)框架,这是一个迭代式的课程学习流程。
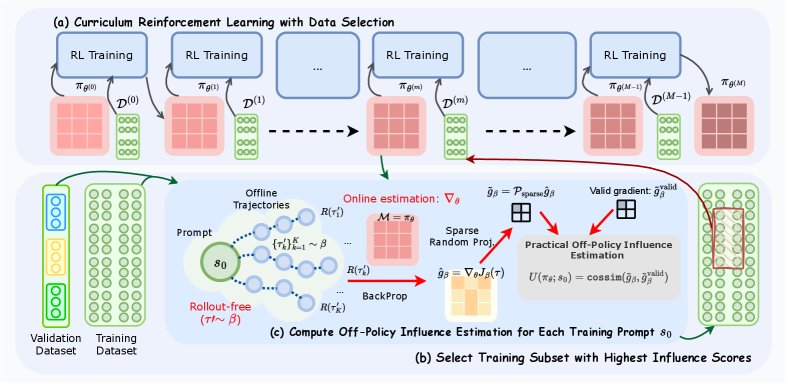
该框架将整个强化学习过程分为多个阶段(Phase):
- 影响力计算:在每个阶段开始时,利用当前的策略检查点 \($\pi\_{\theta^{(m)}}\)$,通过离策略梯度估计和稀疏随机投影,计算训练集中每个数据点 \($s\_0\)$ 对于一个或多个验证集 \($\mathcal{D}\_{\text{val}}\)$ 的影响力得分。当有多个验证集时,使用倒数排序融合(Reciprocal Rank Fusion, RRF)方法整合来自不同验证集的分数。
- 数据选择:根据影响力得分,从整个训练集中选出排名最高的 \($\alpha\%\)$(例如10%)的数据,形成当前阶段的训练子集 \($\mathcal{D}^{(m)}\)$。
- 策略优化:仅使用筛选出的子集 \($\mathcal{D}^{(m)}\)$ 对策略进行若干步的优化(使用GRPO算法),得到更新后的策略 \($\pi\_{\theta^{(m+1)}}\)$。
- 迭代:重复以上步骤,直到训练结束。
通过这种方式,CROPI构建了一个动态课程,使得模型在每个阶段都专注于学习当前最有价值的知识,从而加速整体学习进程。
实验结论
实验在1.5B到7B参数量的多个模型上进行,覆盖了多个数学推理基准测试集。
-
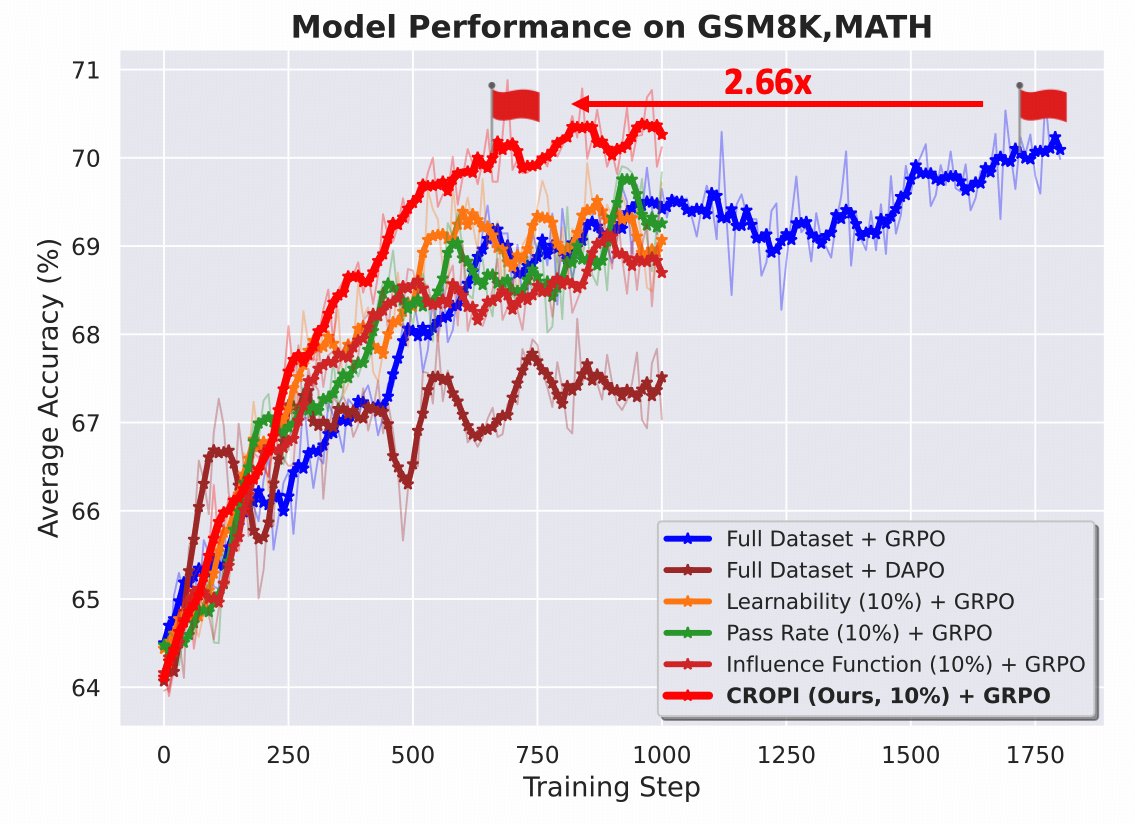
显著的训练加速:CROPI在所有实验设置中均显著优于全数据训练和其他数据选择基线方法。在1.5B模型上,CROPI仅用每阶段10%的数据,实现了2.66倍的步数级别训练加速,达到了与全数据训练相当甚至更好的性能。
-
优越的样本效率:如下图所示,CROPI的训练曲线(橙色)在早期阶段迅速爬升,远超全数据训练(蓝色)和其他基线方法。其他静态数据选择方法(如Learnability, Pass Rate)虽然初期有一定提升,但很快陷入瓶颈,因为它们无法适应策略的动态变化。
-
良好的泛化能力:CROPI不仅在用于指导数据选择的目标任务(Targeted)上表现出色,在未被用于选择的非目标任务(Untargeted)上也取得了显著性能提升,证明其筛选出的数据能够提升模型的通用推理能力。
-
时间成本分析:尽管数据选择过程(计算梯度)本身需要时间,但在考虑这部分开销后,CROPI仍然实现了2.16倍的整体时间加速。作者指出,梯度计算过程还有很大的优化空间,因此实际应用中的加速潜力更大。
| 时间成本(秒) | |
|---|---|
| 数据选择 (1阶段) | 2776 |
| 训练 (1阶段) | 3584 |
| 总计 (1阶段) | 6360 |
- 分析验证:
- 稀疏投影有效性:分析证实,稀疏随机投影(例如,仅使用10%的梯度维度)在保持梯度相似度排序方面,效果远好于对完整梯度进行投影,支持了该设计的有效性。
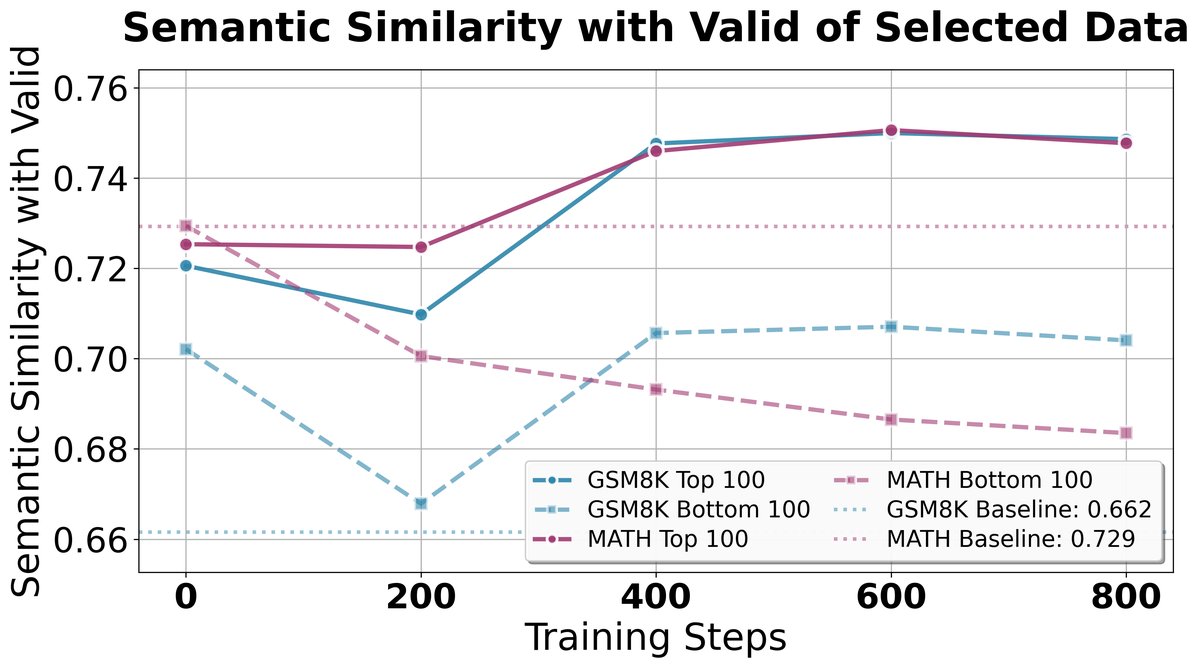
- 数据选择的语义相关性:分析表明,CROPI选出的数据在语义上与验证集更相似,说明该方法能自动识别与目标任务最相关的训练样本。
最终结论:本文成功地将影响函数理论应用于大规模语言模型的RLVR训练中,通过创新的离策略估计和稀疏投影技术,有效解决了计算瓶颈。实验证明,CROPI框架能够大幅提升训练效率和模型性能,展示了基于影响力的动态数据选择在高效AI模型训练中的巨大潜力。