DataFlow: An LLM-Driven Framework for Unified Data Preparation and Workflow Automation in the Era of Data-Centric AI
1万条顶100万条!北大DataFlow:像写PyTorch一样搞定大模型数据

在大模型(LLM)开发的狂热浪潮中,我们往往沉迷于模型架构的微调或参数规模的扩展,却忽略了一个残酷的现实:数据工程依然处于“手工作坊”时代。
ArXiv URL:http://arxiv.org/abs/2512.16676v1
当模型训练代码已经通过 PyTorch 或 TensorFlow 实现了高度标准化和模块化时,数据准备工作却依然充斥着大量临时编写的 Ad-hoc 脚本、难以复现的清洗流程以及缺乏统一标准的“胶水代码”。这不仅效率低下,更让“以数据为中心(Data-Centric AI)”的愿景难以落地。
为了解决这一痛点,北京大学的研究团队推出了一款名为 DataFlow 的全新框架。它不只是一个工具箱,更是一套系统级的解决方案:它让构建数据流水线像写 PyTorch 模型一样优雅、模块化且可编程。
更令人震惊的是,基于 DataFlow 构建的 10K 样本数据集,在训练效果上竟然超越了包含 100 万样本的开源数据集 Infinity-Instruct。
告别“脚本地狱”,拥抱系统化抽象
目前的 LLM 数据处理往往面临两个极端:要么是简单的正则过滤,无法处理复杂的语义任务;要么是复杂的 LLM 合成数据流程,难以维护和复现。
DataFlow 的核心理念是将数据处理流程(Pipeline)提升为一等公民。它引入了类似 PyTorch 的编程接口,通过模块化、可复用、可组合的算子(Operators)来构建数据流。
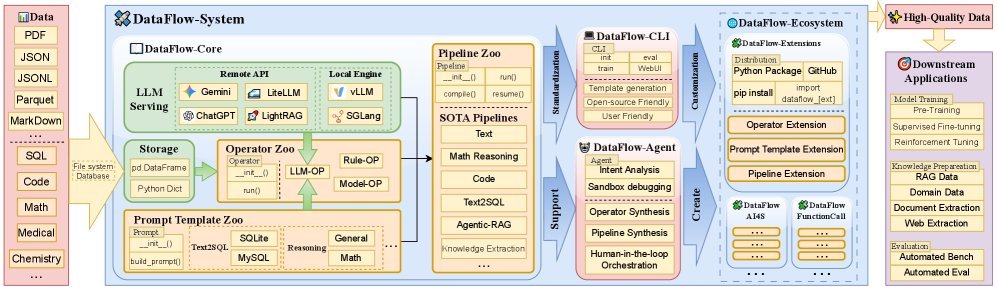
该框架的设计包含四个核心支柱:
-
全局存储抽象:统一管理异构数据源(JSON, Parquet, SQL 等),让算子只关注逻辑,不关注存储细节。
-
层级化编程接口:从底层的 LLM 服务(Serving),到中间层的算子(Operators)和提示词模板(Prompt Templates),再到顶层的流水线(Pipelines),层次分明。
-
丰富的算子库:内置了近 200 个可复用的算子,覆盖了生成、评估、过滤和精炼四大类。
-
插件化扩展:用户可以像发布 Python 包一样发布自己的数据处理算子,形成社区生态。
像搭积木一样构建数据流
DataFlow 最吸引人的地方在于其代码风格。如果你熟悉 PyTorch 的 \(nn.Module\),那么上手 DataFlow 将会毫无门槛。
在 DataFlow 中,一个数据处理流程就是一个 Pipeline 对象,你可以通过 \(add_operator\) 方法将各种处理步骤串联起来。这种显式的依赖关系定义,不仅让代码逻辑一目了然,还支持编译时的检查和优化。

这种设计带来的好处是巨大的:它将复杂的“模型在环”(Model-in-the-loop)数据生成任务,拆解为一个个标准化的原子操作。无论是做 Text-to-SQL 的合成,还是数学推理链(CoT)的生成,都可以通过组合现有的算子快速实现。
DataFlow-Agent:一句话生成流水线
为了进一步降低门槛,研究团队还引入了 DataFlow-Agent。这是一个智能化的编排层,它能理解用户的自然语言指令,自动规划并生成可执行的 Pipeline 代码。
通过算子合成、流水线规划和迭代验证,DataFlow-Agent 可以将模糊的需求(例如“帮我生成一套数学推理数据集”)转化为精确的代码实现。这意味着,开发者甚至不需要自己写 Python 代码,就能构建出 SOTA 级别的数据处理流程。
实验结果:以少胜多的奇迹
DataFlow 的威力在实际应用中得到了验证。研究团队基于该框架构建了六个领域的 SOTA 流水线,涵盖了文本、数学推理、代码、Text-to-SQL、Agentic RAG 和大规模知识提取。
实验数据令人印象深刻:
-
Text-to-SQL:在仅使用不到 10 万条训练数据的情况下,执行准确率比使用 250 万条数据的 SynSQL 还高出 3%。
-
代码能力:在代码基准测试中,平均性能提升了 7%。
-
数学推理:在 MATH 和 GSM8K 等数据集上取得了 1-3 个点的提升。
最引人注目的是数据效率的提升。研究人员将 DataFlow 生成的文本、数学和代码数据组合成了一个仅包含 1 万个样本的数据集 DataFlow-Instruct-10K。
结果显示,仅使用这 1 万条数据微调的 Qwen2-base 模型,其性能竟然超过了使用 100 万条 Infinity-Instruct 数据训练的模型!
总结
DataFlow 的出现,标志着 LLM 数据准备工作正在从“炼金术”走向“系统工程”。通过提供统一的抽象、丰富的算子库和智能化的 Agent,DataFlow 不仅大幅降低了高质量数据构建的门槛,更证明了在数据为王的时代,好的数据工程架构本身就是生产力。
对于所有致力于打造高性能大模型的开发者来说,DataFlow 提供了一个清晰的信号:与其盲目堆砌数据量,不如先升级你的数据“流水线”。