Decide Then Retrieve: A Training-Free Framework with Uncertainty-Guided Triggering and Dual-Path Retrieval
告别“无脑”检索:无需训练,DTR框架利用不确定性让RAG性能全面提升

现有的检索增强生成(RAG)系统往往患有一种“强迫症”:无论用户的问题是简单如“1+1等于几”,还是复杂如“量子纠缠的原理”,它们都会机械地触发检索流程。这种“无脑”检索不仅浪费计算资源,引入的无关文档噪声甚至会扰乱大模型原本正确的判断,导致“幻觉”产生。
ArXiv URL:http://arxiv.org/abs/2601.03908v1
为了解决这一痛点,来自百度、香港大学和北京大学的研究团队提出了一种全新的无需训练(Training-Free)的框架——Decide Then Retrieve(DTR)。该框架赋予了RAG系统“三思而后行”的能力:它能根据生成的不确定性自动判断是否需要检索,并通过双路机制精准捕获关键信息。
RAG系统的“阿喀琉斯之踵”
RAG技术虽然通过引入外部知识极大地增强了LLM的能力,但在实际应用中面临两个主要瓶颈:
-
滥用检索:对于模型内部参数知识(Parametric Knowledge)已经覆盖的简单问题,强制检索往往会引入噪声。研究指出,只有当“检索准确率 $\times$ 生成准确率 > 参数知识准确率”时,检索才是正收益的。
-
检索质量低:用户的查询(Query)往往简短且语义稀疏,直接检索容易匹配到不相关的内容。
针对这些问题,DTR框架提出了一套简洁而高效的解决方案,其核心架构如下图所示:
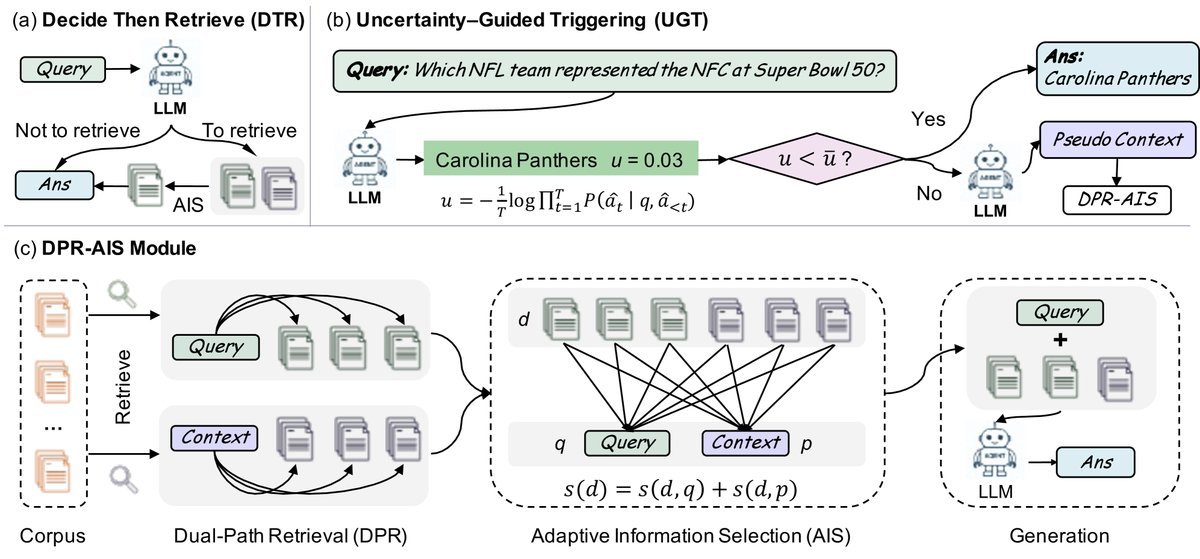
核心机制一:基于不确定性的触发策略
DTR的第一步是“决策”(Decide)。该研究引入了不确定性引导触发(Uncertainty-Guided Triggering, UGT)机制。
其原理非常直观:利用大模型(LLM)自身的生成概率来衡量其“自信程度”。
对于给定查询 $q$,模型生成答案 $\hat{a}$ 的不确定性 $u$ 可以通过计算生成token的平均负对数似然来获得:
\[u=-\frac{1}{T}\log P(\hat{a}\mid q)\]如果 $u$ 低于设定的阈值,说明模型对答案非常有信心,此时直接使用模型的参数知识回答,跳过检索步骤;反之,则触发检索。这种策略不仅节省了推理成本,更重要的是避免了低质量检索内容对模型“自信”领域的干扰。
核心机制二:双路检索与自适应选择
当确定需要检索时,DTR并未采用传统的单路检索,而是设计了双路检索(Dual-Path Retrieval, DPR)配合自适应信息选择(Adaptive Information Selection, AIS)。
传统的查询扩展方法(如HyDE)通常是将生成的伪文档与原查询拼接,这可能会放大模型幻觉带来的噪声。DTR则采取了“分而治之”的策略:
-
双路并行:系统同时执行两条检索路径。
-
路径一:基于原始查询 $q$ 进行检索。
-
路径二:基于LLM生成的伪上下文(Pseudo-Context)$p$ 进行检索。
-
-
自适应融合:在获得两组候选文档后,AIS机制会计算每个文档与“原始查询”和“伪上下文”的联合相似度。
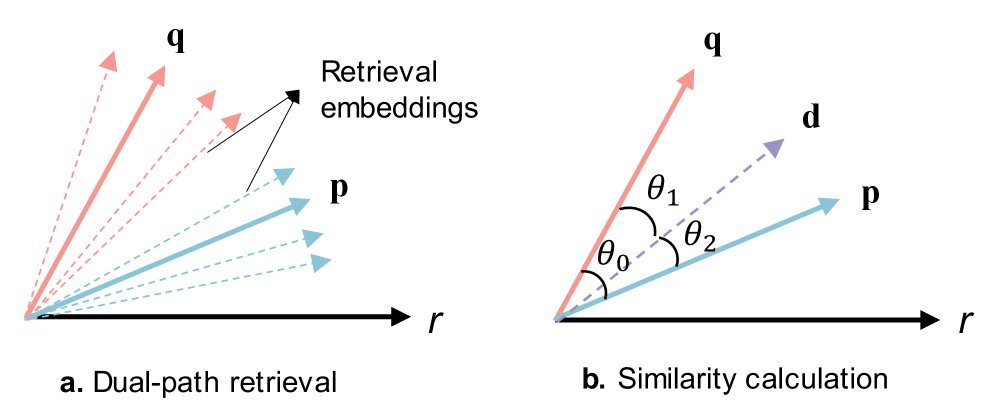
具体的评分公式为:
\[s(d)=s\_{1}(d,q)+s\_{2}(d,p)\]其中 $s_1$ 和 $s_2$ 分别代表文档与查询、文档与伪上下文的余弦相似度。这种机制确保了最终选出的文档既符合用户原始意图,又在语义上与模型生成的上下文保持一致,从而大大提高了证据的质量。
实验结果:全面超越基线
研究团队在NaturalQA、HotpotQA等五个开放域问答基准上,使用Qwen2.5系列模型(7B和72B)进行了广泛实验。
实验结果表明,DTR在无需任何额外模型训练的情况下,性能表现优异:
-
准确率提升:在EM(精确匹配)和F1分数上,DTR一致性地超越了标准RAG以及HyDE、LLM Judge等强基线模型。
-
减少噪声:通过UGT机制,DTR成功避免了大量不必要的检索。例如在72B模型上,对于简单问题,DTR能有效利用模型参数知识直接作答,避免了画蛇添足。
下表展示了在不同数据集上的主要对比结果:
(注:表格数据展示了DTR在多项指标上的领先优势)
总结
Decide Then Retrieve(DTR)框架通过“先决策、后检索”的范式,巧妙地平衡了LLM的内部知识与外部检索信息。它无需训练、易于部署,且能显著提升RAG系统的鲁棒性和准确性。对于正在构建RAG应用的开发者而言,DTR提供了一个低成本、高收益的优化思路:有时候,让模型学会“偷懒”(不检索),反而能获得更好的效果。