斩获IMO/IOI金牌!DeepSeek-V3.2发布,推理比肩Gemini 3.0 Pro

开源大模型的世界,刚刚迎来了一位重量级选手!就在人们感叹开源与闭源模型的差距似乎越拉越大时,深度求索(DeepSeek)发布了最新的 DeepSeek-V3.2 模型。它不仅在国际数学奥林匹克(IMO)和国际信息学奥林匹克(IOI)竞赛中取得了金牌级表现,其推理能力更是直接对标顶尖的闭源模型 Gemini 3.0 Pro。
ArXiv URL:http://arxiv.org/abs/2512.02556v1
这究竟是如何做到的?DeepSeek-V3.2 凭借三大技术法宝,成功突破了开源模型面临的效率、性能和Agent能力三大瓶颈,向世界展示了开源力量的巨大潜力。
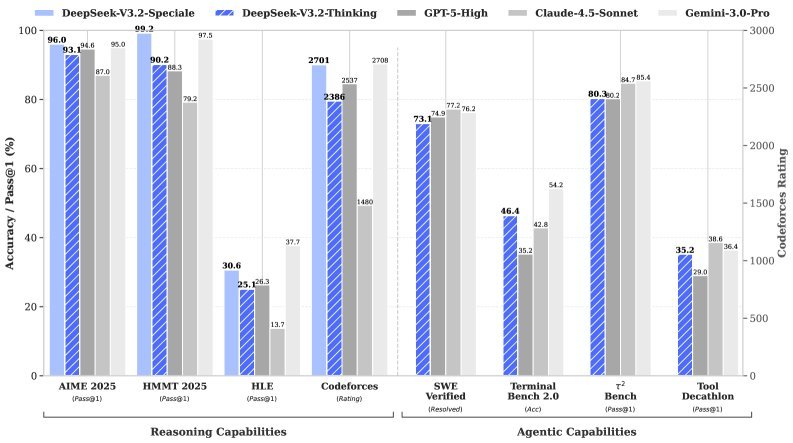
▲ DeepSeek-V3.2 与其他顶尖模型的性能对比
DSA:为长文本推理“降本增效”
大模型处理长文本时,传统的注意力机制(Attention)计算量会随文本长度的平方($O(L^2)$)暴增,这既昂贵又低效。
为了解决这个顽疾,DeepSeek-V3.2 引入了一项全新的架构创新:深度求索稀疏注意力(DeepSeek Sparse Attention, DSA)。
DSA 的核心思想非常巧妙。它包含一个“闪电索引器”(lightning indexer)和一个“细粒度Token选择器”。对于每个需要计算的Token(Query),闪电索引器会快速扫描全部上下文,并精准定位出最相关的 $k$ 个Token(Key-Value)。
这样一来,模型就不再需要进行全局的密集计算,而是将注意力集中在最关键的信息上。
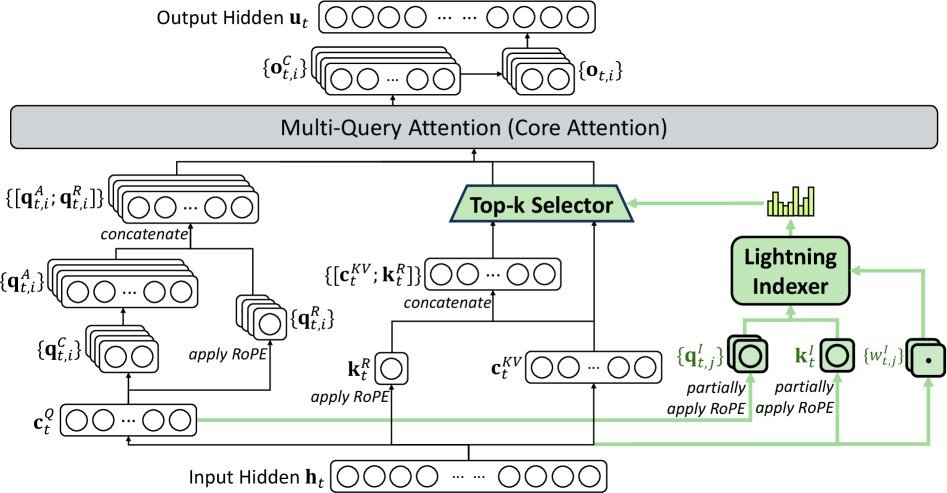
▲ DeepSeek-V3.2 的注意力架构,绿色部分为DSA如何选择Top-k信息
通过这种方式,DSA 将注意力计算的复杂度从 $O(L^2)$ 降低到了 $O(Lk)$,其中 $k$ 远小于 $L$。
更重要的是,这种效率的提升几乎没有牺牲模型性能。无论是在标准基准测试还是长文本评测中,采用DSA的DeepSeek-V3.2都表现出与前代密集注意力模型相媲美的性能。
带来的直接好处就是推理成本的大幅下降。从官方公布的成本对比图可以看出,在处理长序列时,DeepSeek-V3.2 的成本优势极为显著,为大模型在长文本场景的规模化应用铺平了道路。
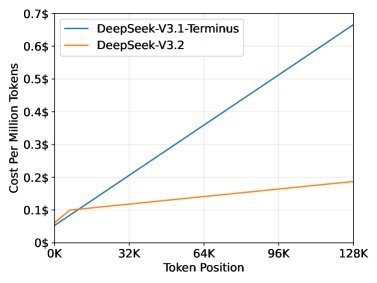
▲ DeepSeek-V3.2 与前代模型的推理成本对比
可扩展强化学习:重金砸出的卓越性能
仅仅有高效的架构还不够。为了让模型具备超凡的推理能力,DeepSeek 在后训练(Post-training)阶段投入了巨大的计算资源——超过预训练成本的10%。
如此大规模的投入,需要一个极其稳定和可扩展的强化学习(RL)框架。该研究基于 GRPO(Group Relative Policy Optimization)算法,并引入了四项关键技术来确保训练的稳定性:
-
无偏KL估计:修正了KL散度的估计算法,消除了系统性误差,让模型收敛更稳定。
-
离策略序列掩码(Off-Policy Sequence Masking):在训练中屏蔽掉可能破坏稳定性的“坏样本”,提升了对离策略(off-policy)数据的容忍度。
-
保持路由(Keep Routing):针对MoE架构,确保训练和推理时专家模块的激活路径一致,避免参数突变。
-
保持采样掩码(Keep Sampling Mask):确保训练和推理时采用相同的采样策略(如Top-p),维持了行为的一致性。
通过这套组合拳,DeepSeek-V3.2 能够稳定地吸收海量数据中的知识,将巨大的计算投入高效转化为模型能力的飞跃。
Agent能力进化:大规模任务合成流水线
让模型学会使用工具(即Agent能力),是通往通用人工智能的关键一步。然而,开源模型在Agent任务的泛化性和指令遵循能力上一直落后于闭源对手。
DeepSeek-V3.2 对此的解决方案是:构建一个强大的 大规模Agent任务合成流水线。
这个流水线可以系统性地、大规模地生成用于训练的Agent任务数据。研究团队通过它合成了超过1800个不同的环境和85000个复杂的任务提示。

▲ 在工具调用场景中保留“思考”过程的机制
为了让模型学会在调用工具时也能进行深度“思考”,研究团队首先通过巧妙的提示工程进行“冷启动”,让模型初步学会在推理路径中嵌入工具调用。随后,利用海量的合成数据进行强化学习,极大地增强了模型在复杂交互环境中的泛化和指令遵循能力。
这个流水线涵盖了搜索、代码、代码解释器等多种真实或合成的Agent任务,为模型提供了前所未有的丰富训练场景。
性能表现:开源模型的荣耀时刻
经过上述三大技术突破的加持,DeepSeek-V3.2 的表现令人惊叹。
-
DeepSeek-V3.2:在多个推理基准上,性能与GPT-5相当,并在Agent任务上大幅缩小了与顶尖闭源模型的差距。
-
DeepSeek-V3.2-Speciale:作为专注于推理的实验版本,它在性能上超越了GPT-5,与Gemini-3.0-Pro并驾齐驱,并在2025年的IMO、IOI等顶级竞赛中取得了金牌水平的成绩。
在 Tool-Decathlon、MCP-Mark 等多个Agent评测基准上,DeepSeek-V3.2 的表现同样出色,证明了其在工具使用和复杂任务规划方面的强大实力。
结语
DeepSeek-V3.2 的发布,无疑是开源社区的一剂强心针。它通过 DSA 解决了效率和成本问题,通过 可扩展的RL框架 释放了模型的推理潜力,并通过 Agent任务合成流水线 补齐了泛化能力的短板。
这不仅是一个模型的迭代,更是一套可行的、能够挑战闭源模型霸权的开源技术路线图。它向我们证明,只要有正确的方法和足够的投入,开源模型同样能够攀登人工智能的最高峰。