Detecting Data Contamination in LLMs via In-Context Learning
-
ArXiv URL: http://arxiv.org/abs/2510.27055v1
-
作者: Meriem Boubdir; Michał Zawalski; Besmira Nushi; Klaudia Bałazy
-
发布机构: NVIDIA
TL;DR
本文提出了一种名为 CoDeC 的新方法,通过衡量上下文学习(In-Context Learning)对模型置信度的影响,来有效检测和量化大语言模型中的训练数据污染问题。
关键定义
本文主要提出了一个核心概念:
- CoDeC (Contamination Detection via Context):一种通过上下文进行污染检测的方法。其核心思想是,模型对于在训练中见过的数据(污染数据)和未见过的数据,在面对来自同一分布的上下文示例时,其响应模式存在差异。对于未见过的数据,上下文示例通常能提升模型的预测置信度;而对于已见过的数据,上下文示例反而可能因为破坏了模型的记忆模式而降低其置信度。
- 污染分数 (Contamination Score):本文定义的一个量化指标,用于衡量数据集的污染程度。其计算方式为:在一个数据集中,因添加了上下文示例而导致模型预测置信度下降的样本所占的百分比。分数越高,代表数据污染的可能性越大。
相关工作
目前,检测大语言模型(LLM)中的数据污染对于确保评估的公正性至关重要。现有的方法主要包括:
- 基于损失值的方法:通过设定损失值或困惑度的阈值来判断样本是否被记忆。
- 基于参考模型的方法:使用一个外部的、更小的模型来校准分数,以区分记忆和泛化。
- 显式重叠检查:直接通过n-gram等方式检查评测集和训练集之间的文本重叠。
- 成员推断攻击 (Membership Inference Attacks, MIAs):旨在判断某个特定样本是否被用于模型训练。
这些传统方法存在诸多瓶DE颈,例如:通常需要访问模型的训练数据、需要进行繁琐的参数调优、计算成本高昂(如训练影子模型),并且对于现代的大型语言模型,其结果往往不够可靠和直观。尤其是在模型仅训练一个轮次(epoch)的情况下,许多早期方法会失效。
本文旨在解决上述问题,提出一种无需访问训练数据、无需参数调优、模型和数据类型无关、可扩展且能提供直观可解释结果的自动化数据污染检测方法。
本文方法
核心思想
本文方法 CoDeC 的核心思想基于一个关键观察:大语言模型(LLM)对于是否见过的数据,在接收上下文示例(In-Context Examples)时的反应截然不同。
- 对于未见过的数据:当模型处理一个来自其训练分布之外的数据集时,提供一些从该数据集中抽取的上下文示例,通常能帮助模型更好地理解数据分布的模式、风格和结构,从而提升其对目标样本的预测置信度(即泛化能力得到增强)。
- 对于已见过的数据(受污染):如果模型在训练阶段已经“记住”了某个数据集,那么额外的上下文示例提供的新信息非常有限。更重要的是,这些上下文示例可能会干扰模型已经形成的固定记忆模式,导致其预测变得混乱,从而降低预测置信度。
因此,通过比较模型在有无上下文示例两种情况下对同一数据样本的预测置信度变化,就可以有效地区分模型是在泛化还是在记忆,进而判断数据污染的程度。
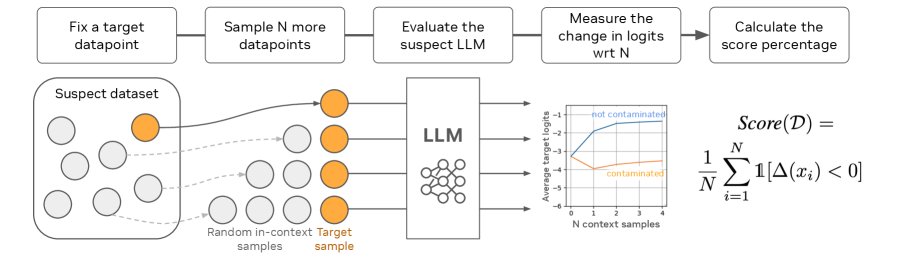
CoDeC 流水线
如上图所示,CoDeC 的具体执行步骤如下:
- 计算基线置信度:对于待检测数据集 $\mathcal{D}$ 中的每一个样本 $x$,计算模型 $M$ 对其序列中所有Token的平均对数似然概率,记为 $\text{logprob}_{\text{baseline}}(x)$。
- 计算上下文置信度:从数据集 $\mathcal{D}$ 中(除去样本 $x$ 本身)随机抽取 $n$ 个其他样本 $x_1, \dots, x_n$,将它们拼接在 $x$ 的前面,形成一个新的输入序列 $x_1 \mid \dots \mid x_n \mid x$。然后,再次计算模型 $M$ 对 $x$ 部分的平均对数似然概率,记为 $\text{logprob}_{\text{in-context}}(x)$。
- 计算置信度差异:计算两种情况下的置信度差异 $\Delta(x) = \text{logprob}_{\text{in-context}}(x) - \text{logprob}_{\text{baseline}}(x)$。
-
计算污染分数:对数据集中所有样本重复以上步骤。最终的污染分数 $S_{\text{CoDeC}}(\mathcal{D})$ 定义为置信度差异小于零的样本所占的比例:
\[S_{\text{CoDeC}}(\mathcal{D})=\frac{1}{N}\sum_{i=1}^{N}\mathds{1}[\Delta(x_{i})<0]\]其中 $\mathds{1}$ 是指示函数。这个分数直观地表示了“因加入上下文而导致模型更不自信”的样本比例。
创新点
- 利用置信度“变化”作为信号:与传统方法依赖绝对损失值或困惑度不同,CoDeC 巧妙地利用了“上下文学习”前后模型置信度的相对变化作为判断依据。这是一个全新的、更鲁棒的信号。
- 无监督且无需校准:该方法完全自动化,不需要访问训练数据,也不依赖任何外部参考模型进行校准。其输出是一个介于 0% 到 100% 之间的分数,直观易懂,无需针对不同模型或数据集进行阈值调整。
- 高效且通用:CoDeC 仅需对每个样本进行两次前向传播,计算效率高。它适用于任何可以表示为文本序列的数据集,并且与模型架构无关,仅需获得模型输出的Token概率(灰盒访问)。
优点
CoDeC 的有效性源于几个核心原理:
- 信息冗余与干扰:对于已记忆的数据,上下文是冗余信息;更甚者,上下文中的记忆模式会干扰模型对目标样本的既有记忆通路,导致预测混乱和置信度下降。
- 衡量学习潜力:CoDeC 实际上在衡量模型对于特定数据集还有多少“学习空间”。受污染的模型类似于接近饱和的微调模型,额外信息(上下文)带来的增益极小甚至为负。
- 与过拟合的关联:污染通常与过拟合相关。过拟合的模型处在损失曲面一个狭窄而陡峭的局部最小值中,容易被上下文等微小扰动破坏稳定性。而未见过的数据对应于更平坦、更稳定的损失区域,上下文信息能引导模型做出更稳健的预测。
实验结论
本文通过广泛的实验验证了 CoDeC 方法的有效性、稳定性和实用性。
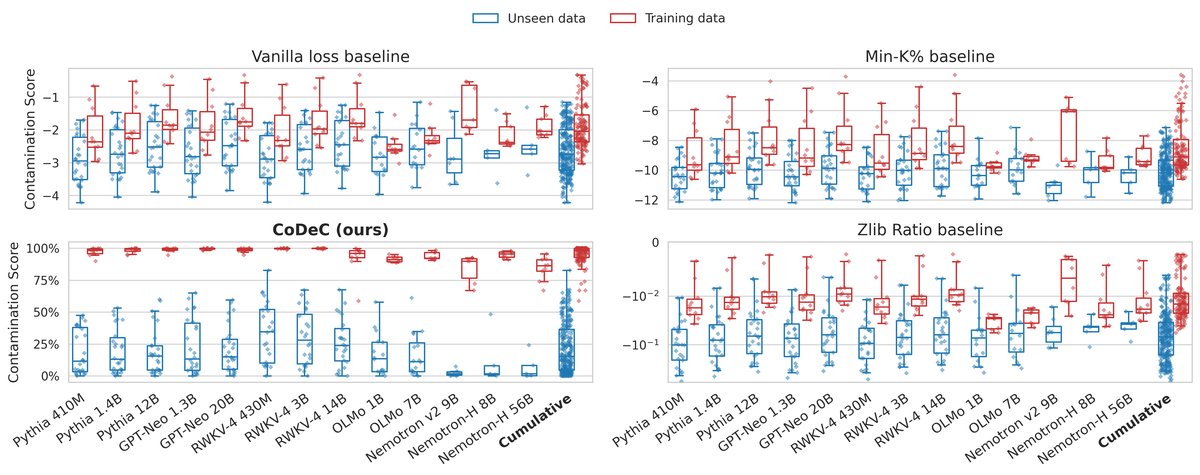
主要验证
- 清晰区分 seen/unseen 数据:如上图所示,CoDeC 能够极其清晰地区分模型训练时见过(seen)和未见过(unseen)的数据集。对于 seen 数据,其污染分数普遍很高;而对于 unseen 数据,分数则很低。相比之下,几种基线方法的得分区间存在大量重叠,无法提供可靠的判断。
- 高准确率:在所有被评估的模型上,CoDeC 在数据集级别的污染检测任务中均取得了近乎完美的 AUC(曲线下面积)分数。
| 模型 | CoDeC | Loss | Min-K% | Zlib |
|---|---|---|---|---|
| Pythia-2.8B | 100.0 | 71.3 | 68.3 | 75.8 |
| OLMo-1.7B | 100.0 | 86.6 | 76.5 | 87.6 |
| OLMo-7B | 100.0 | 90.9 | 82.2 | 87.2 |
| Nemotron-v2-8B | 97.0 | 72.8 | 66.8 | 63.8 |
| Nemotron-H-8B | 100.0 | 92.5 | 86.8 | 84.1 |
- 分数稳定性:对于同一个数据集,不同模型(只要它们在相似的语料上训练,如 The Pile)得出的 CoDeC 分数表现出很高的一致性。这表明分数的异常偏离可以作为数据污染的有力信号。
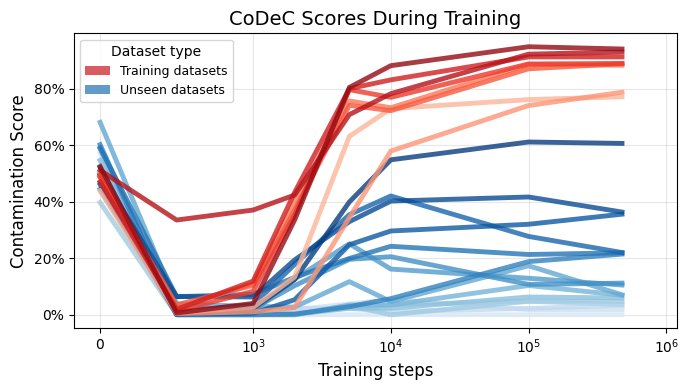
训练过程中的污染检测
- 早期检测能力:上图展示了 OLMo-7B 模型在训练过程中 CoDeC 分数的变化。结果显示,污染信号在训练的极早期(1k到10k步之间,约占总训练量的2%)就已非常明显。对于训练集内的数据,污染分数急剧上升并保持稳定,而对于未见过的数据则稳定在较低水平。这证明 CoDeC 是一个有效的工具,可用于在开发早期防止基准泄露。
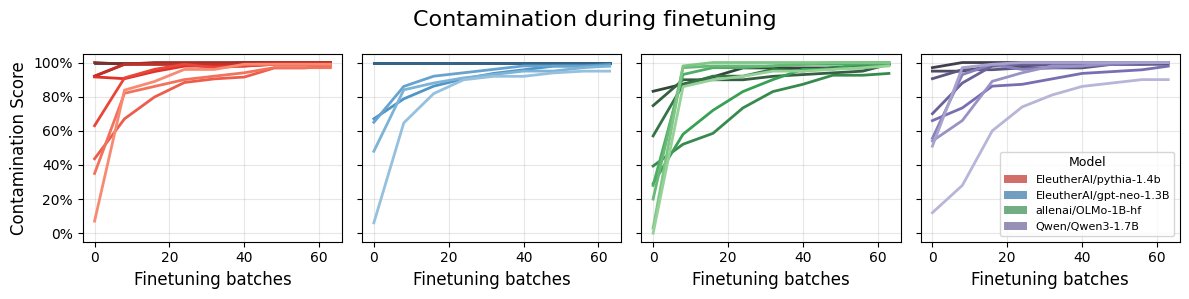
通过微调验证污染检测
- 微调即污染:实验通过在不同模型上对特定数据集(包括 seen 和 unseen)进行微调。结果如上图所示,无论原始数据是否见过,经过微调后,CoDeC 分数都稳定地上升到 90% 以上。这证实了 CoDeC 能够可靠地检测到因微调而引入的污染,并且该验证方法适用于任何模型,即使是训练数据未公开的模型。
- 污染传递效应:在 MMLU 数据集上微调模型,不仅使其在该数据集上表现出高度污染,还会对其他格式或主题相似的问答(QA)数据集产生轻微的“污染传递”效应。这表明 CoDeC 能够捕捉到分布层面的相似性。同时,实验证明,简单的数据增强(如文本截断或改写)无法规避 CoDeC 的检测。
- 揭示过拟合:实验发现,增加上下文示例对模型置信度的影响曲线与以温和学习率进行微调的效果高度相似。受污染的数据集对学习率非常敏感,微小的更新都可能导致置信度下降,这支持了污染与过拟合(模型陷入狭窄的损失谷底)密切相关的观点。
消融研究
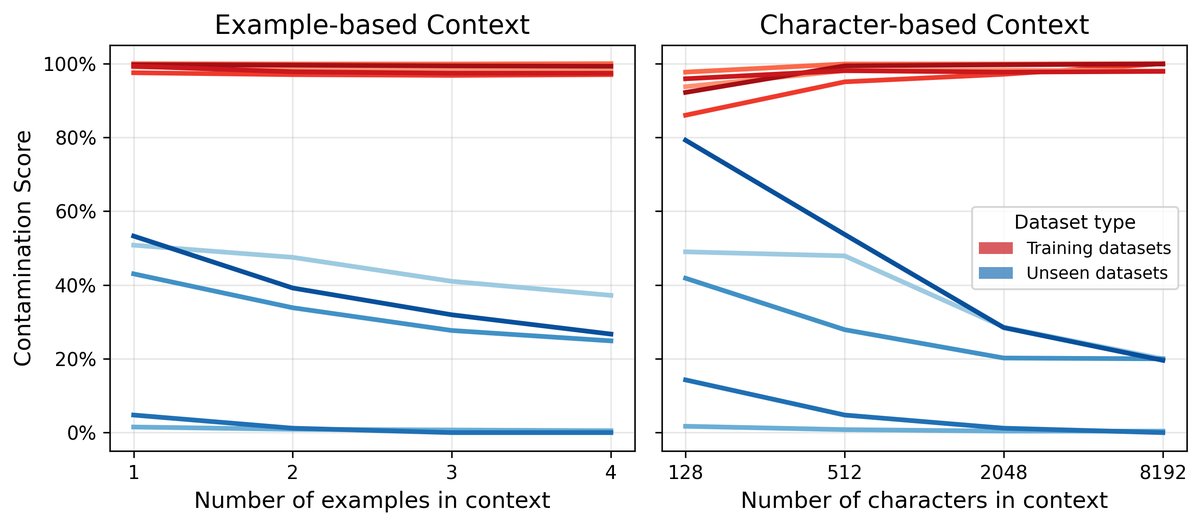
- 上下文大小:增加上下文示例的数量(从1个增加到更多)可以使 seen 和 unseen 数据集的分数差距更明显,但也会增加计算成本。在实践中,仅使用1个上下文示例已能提供非常强的信号,是效率和效果的良好平衡。
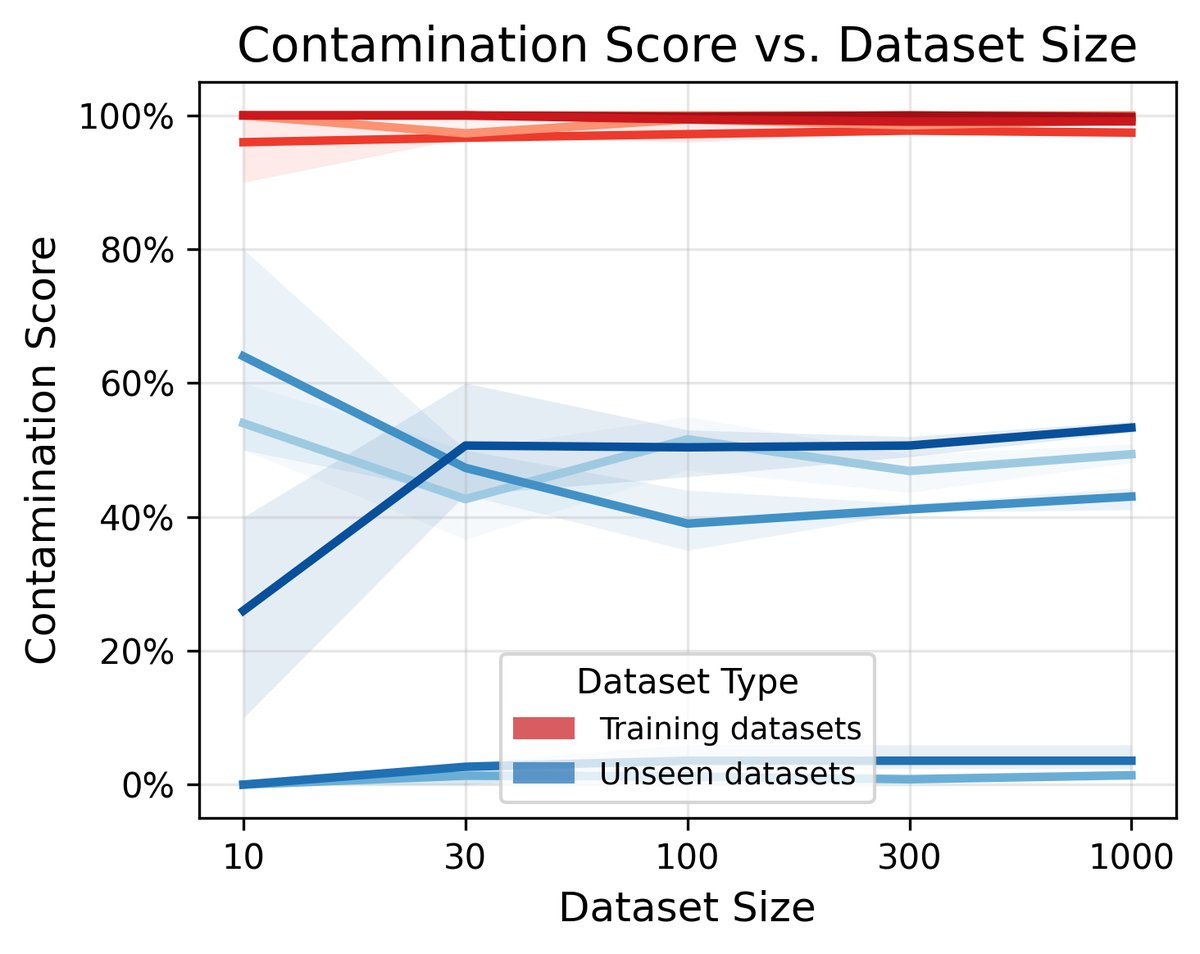
- 数据集大小:CoDeC 具有很高的样本效率。大约100个样本就足以得到稳定的污染分数估计,使其在小型基准测试上也同样适用。
结论
- CoDeC 是一种强大、可靠且实用的数据污染检测工具。 它通过一个简单而新颖的视角——上下文学习对置信度的影响——成功解决了现有方法的诸多痛点。
- 高分提示污染:通常,CoDeC 分数高于80%应被视为数据污染的强烈信号。而对于中等分数,应与其它模型在该数据集上的分数进行比较,以区分是数据集本身特性(如高度多样性)还是部分污染。
- 衡量泛化能力:在基准测试准确率相近的模型中,CoDeC 分数较低的模型通常具有更好的泛化能力,而不是依赖于记忆。
- 应用广泛:CoDeC 已被应用于40多个近期模型,揭示了一些潜在的污染案例,证明了其在维护模型评估公平性方面的巨大价值。