Diffusion Language Models are Super Data Learners
-
ArXiv URL: http://arxiv.org/abs/2511.03276v1
-
作者: Qian Liu; Chao Du; Tianyu Pang; Longxu Dou; Zili Wang; Hang Yan; Jinjie Ni
-
发布机构: National University of Singapore; Sea AI Lab; Shanghai Qiji Zhifeng Co., Ltd.; StepFun
TL;DR
本文通过大量实验证明,在训练数据稀缺但计算资源充足的条件下,扩散语言模型(Diffusion Language Models, DLMs)相比同等规模的自回归模型(Autoregressive Models, AR)能从有限数据中学习到更多信息,最终在性能上实现超越,这一现象被称为“智能交叉”(Intelligence Crossover)。
关键定义
本文主要沿用并对比了两种核心的语言模型范式:
-
自回归语言模型 (Autoregressive Language Models, AR): 这是当前主流大语言模型(如GPT系列)采用的范式。它通过链式法则对文本序列的联合概率分布进行建模,即在生成时,每个 token 的预测都依赖于其之前的所有 token。其概率公式为:
\[p_{\theta}(x_{1:T})=\prod_{i=1}^{T}p_{\theta}\!\left(x_{i}\mid x_{<i}\right).\]这种模型训练高效,但其固有的从左到右的因果结构(causal structure)限制了其对数据的利用方式。
-
掩码扩散语言模型 (Masked Diffusion Language Models, DLM): 一种基于“加噪-去噪”框架的生成模型。它首先通过一个前向过程(forward process)随机“掩码”(mask)输入序列中的一部分 token,然后在反向过程(reverse process)中,模型需要学习根据剩余的未掩码 token 恢复出被掩码的原始 token。其学习目标是最小化一个变分界,形式如下:
\[\mathcal{L}\;=\;\int_{0}^{1}w(t;\alpha)\;\mathbb{E}_{q_{t \mid 0}(x_{t}\mid x_{0})}\!\left[\sum_{i:\,x_{t}^{(i)}=m}-\log p_{\theta}\!\left(x_{0}^{(i)}\mid x_{t}\right)\right]\mathrm{d}t,\]由于模型在训练时可以看到双向的上下文信息,DLM 具备任意阶建模(any-order modeling)能力,不受从左到右的顺序限制。
-
智能交叉 (Intelligence Crossover): 这是本文发现并命名的核心现象。指在总训练 token 数固定但唯一(unique)数据量有限的情况下,DLM 的性能曲线在训练到某个点后会向上穿越并持续优于 AR 模型的现象。这个交叉点的位置受数据量、数据质量、模型规模等因素影响。
相关工作
当前,以自回归(AR)模型为代表的解码器架构(decoder-only Transformers)主导了大型语言模型领域。它们在拥有海量、不断增长的高质量数据和有限计算资源的时代取得了巨大成功。这种模型的成功依赖于其高效的训练方式(teacher forcing)和推理方式(KV-caching)。
然而,研究范式正在发生转变:随着模型规模的持续扩张,高质量、独特的训练数据正逐渐取代计算资源(FLOPs),成为限制模型能力进一步提升的主要瓶瓶颈。
因此,本文旨在解决一个前瞻性的问题:当数据成为稀缺资源而非计算时,哪一种语言建模范式能够从每个独特的 token 中榨取更多的“智能”?
本文方法
本文的核心贡献并非提出一个全新的模型架构,而是通过严谨的对比实验,发现并系统性分析了在数据受限场景下,DLM 相对于 AR 模型的优越性,即“智能交叉”现象。
核心发现:智能交叉
本文的主要实证发现是,当总训练 token 量固定而唯一数据量有限时(即数据被多次重复训练),DLM 的性能最终会稳定地超过同等规模的 AR 模型。这一“交叉”现象并非偶然,它系统性地随着多个核心因素变化:数据越少、模型越大,交叉点出现得越早;数据质量越高,交叉点出现得越晚。
交叉现象的成因分析
作者将 DLM 的优势归因于三个协同作用的因素:
-
放宽的归纳偏置 (Relaxed Inductive Bias): AR 模型严格遵循从左到右的因果顺序,而 DLM 的任意阶建模能力(any-order modeling)使其能够从任意方向学习序列中的依赖关系。这为模型在有限的数据集上提供了更大的拟合自由度,能够从每个样本中挖掘更复杂的模式。
-
超密集计算 (Super-dense Compute): DLM 在训练和推理过程中都需要更多的计算量。训练时,双向注意力和时序优化(temporal refinement)让模型能更彻底地“消化”有限的数据;推理时,并行的多 token 生成也需要大量并行 FLOPs。这种高计算密度使得模型能够更深入地学习。
-
内置的噪声数据增强 (Built-in Noisy Augmentation): DLM 的扩散目标函数(diffusion objective)通过对输入序列进行各种模式的随机“腐蚀”(corruption),天然地将一个样本序列变成了许多信息丰富的训练变体。这种蒙特卡洛采样机制相当于一种强大的内置数据增强,极大地提升了数据利用效率。
实验证明,尽管为 AR 模型手动加入输入噪声(掩码)或参数噪声(dropout)也能在数据稀缺时提升性能,但其效果远不及 DLM,这表明 DLM 的优势是上述三个因素共同作用的结果,而不仅仅是数据增强。
实验结论
本文通过一系列受控实验,系统地验证了“智能交叉”现象,并揭示了其背后的规律。
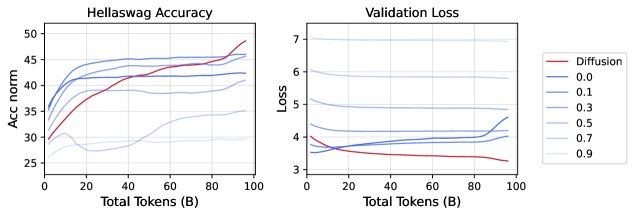
数据预算决定交叉点
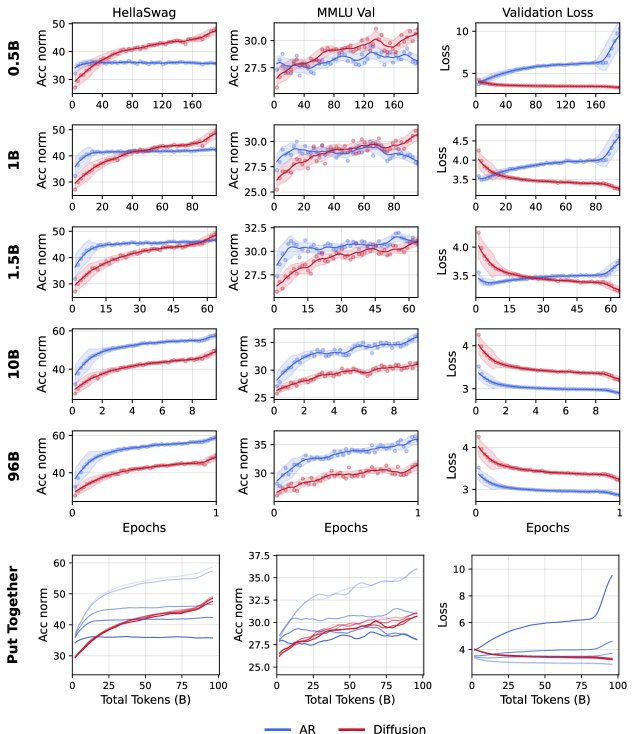
实验固定总训练量为 96B token,改变唯一数据量从 0.5B 到 96B。结果显示,唯一数据量越少(即数据重复次数越多),DLM 超越 AR 的交叉点出现得越早。实证表明,DLM 的数据效率比 AR高出约3倍以上(例如,在 0.5B 独特数据上训练的 DLM 性能可媲美在 1.5B 独特数据上训练的 AR 模型)。
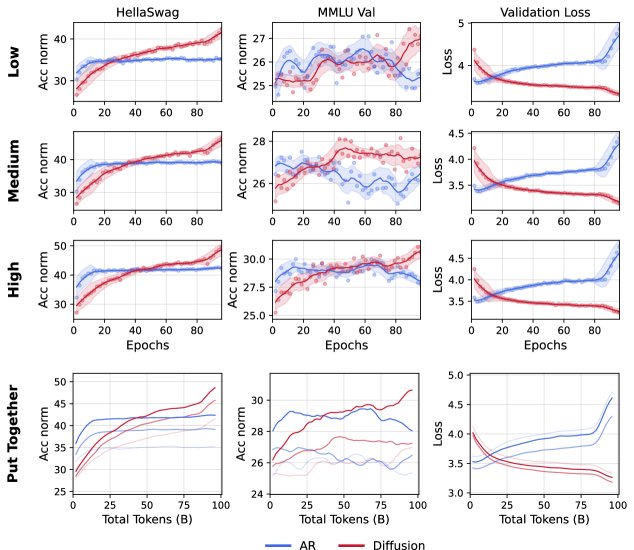
数据质量的影响
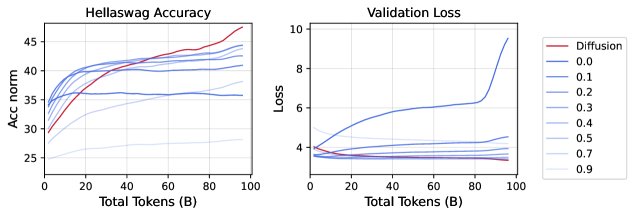
实验在 1B 独特数据上使用低、中、高三种质量的数据进行训练。结果发现,随着数据质量的提高,DLM 和 AR 模型的性能都得到提升,但交叉点会略微向后推迟。这表明 AR 模型可能对数据质量的变化更为敏感。
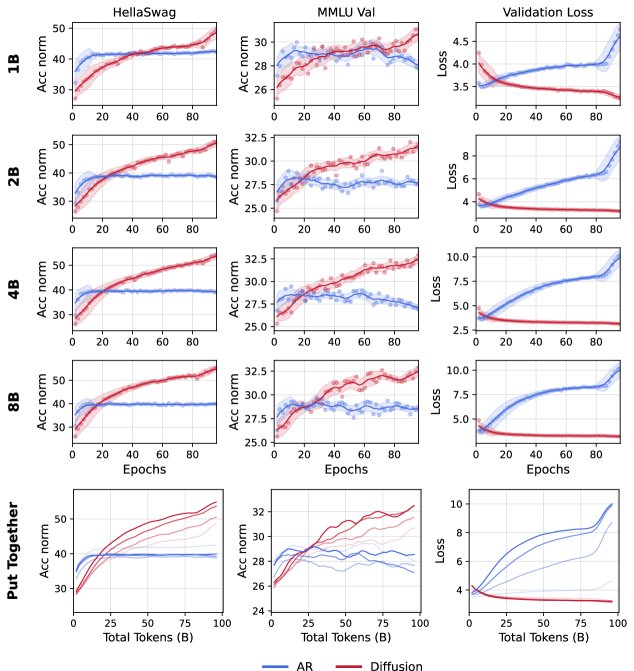
模型规模的影响
在 1B 独特数据上,训练 1B 到 8B 参数不等的模型。结果显示,模型规模越大,交叉点出现得越早。这是因为在数据有限时,更大的 AR 模型会更快地饱和甚至过拟合,而 DLM 则能持续从模型规模的增长中受益。
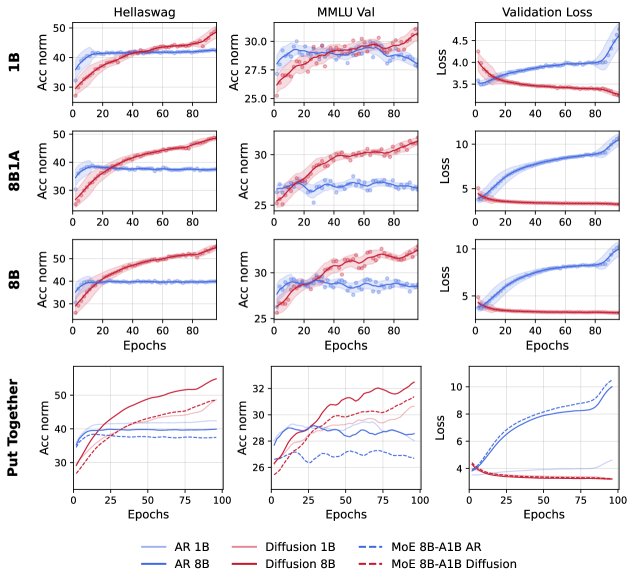
稀疏与密集架构的对比
实验对比了密集模型、稀疏专家混合模型(Mixture-of-Experts, MoE)在数据受限下的表现。
- DLM 在所有架构配置(密集或稀疏)中都一致优于 AR 模型。
- 对于 AR 模型,在数据受限时扩大模型规模(无论是密集扩展还是稀疏扩展)反而损害性能,显示出在数据稀缺时“小即是美”的特点。
- 对于 DLM,稀疏的 MoE 模型性能则如预期地介于其参数匹配和计算匹配的密集模型之间,表明 DLM 能更好地利用增加的参数。
噪声注入实验
为了分离出“噪声增强”的贡献,实验向 AR 模型注入了不同比例的输入掩码噪声和参数 dropout 噪声。
- 结果表明,适度的噪声(如10%的掩码)确实能提升 AR 模型在数据受限时的性能,验证了噪声增强的有效性。
- 然而,即便是最优的噪声配置,AR 模型的性能仍远不及 DLM,且会更快饱和。这证实了 DLM 的优势并不仅仅来自噪声,还来自其独特的任意阶建模和高计算密度。
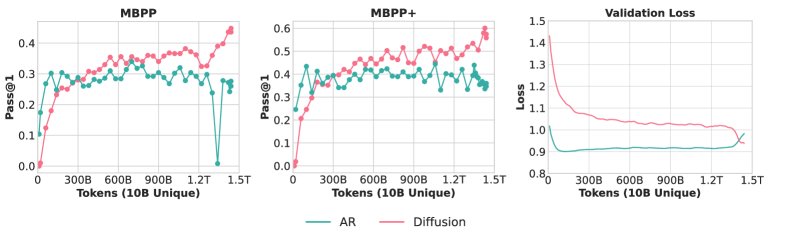
万亿级 Token 规模的验证
为了验证交叉现象在更大数据量和实际任务上的普适性,作者在 10B 独特 Python 代码数据上训练了 1.7B 参数的 AR 和 DLM 模型(总计算量约1.5T token)。结果再次观察到清晰的早期性能交叉,最终 DLM 代码模型的性能达到了与使用数万亿独特 token 训练的 SOTA AR 代码模型相媲美的水平。
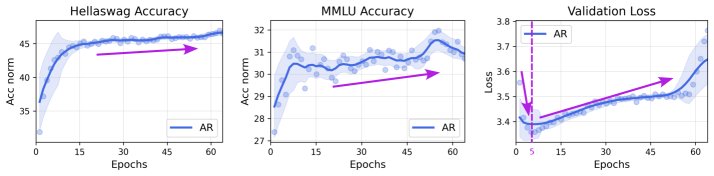
对“过拟合”现象的重新审视
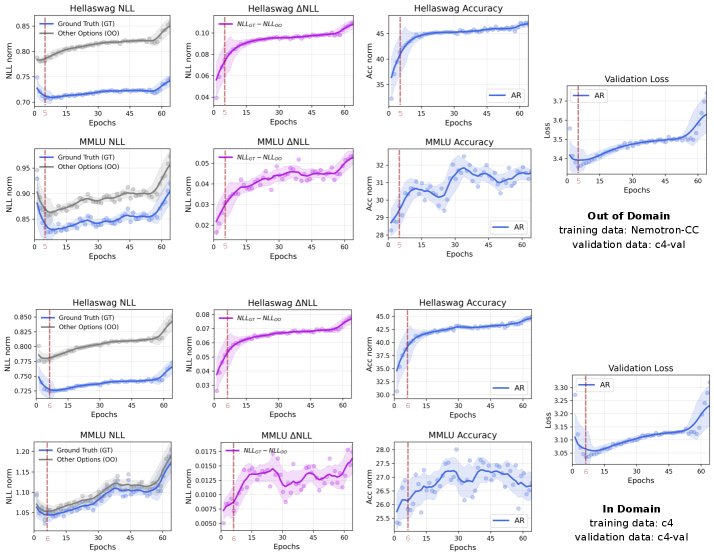
本文发现一个有趣的现象:验证集损失上升不等于下游任务性能下降。 实验观察到,即使 AR 模型在预训练验证集上的交叉熵损失开始上升(即通常所说的“过拟合”),其在下游基准测试(如 MMLU)上的准确率依然在持续提升。 原因在于,多项选择题的准确率取决于模型为正确选项和错误选项分配的相对对数似然差异(\(ΔNLL\)),而非绝对损失值。即使模型因过拟合而变得“过于自信”,导致所有选项的绝对 \(NLL\) 值都上升,但正确选项与错误选项之间的 \(NLL\) 差距可能仍在扩大,这意味着模型的判别能力仍在增强。
最终结论
在未来高质量数据成为最稀缺资源的“数据受限时代”,尽管需要付出更多的计算成本,但扩散语言模型(DLM)凭借其卓越的数据学习潜力,是推动模型能力边界的一个极具竞争力的范式。