告别“深度诅咒”:谷歌新方法LIDAS让LLM动态生长,训练提速29%!

你是否想过,当我们费尽心力将语言模型(LLM)堆叠到数百上千层时,这些层真的都在“努力工作”吗?一个残酷的现实是,许多Transformer模型的深层网络贡献甚微,甚至有些“懒惰”,这种现象被称为深度诅咒(Curse of Depth)。这不仅造成了巨大的计算资源浪费,也限制了模型潜力的完全释放。
ArXiv URL:http://arxiv.org/abs/2512.08819v1
现在,来自谷歌和亥姆霍兹AI的一项新研究,为我们揭示了一种破解“深度诅咒”的迷人方法:让模型在训练中“动态生长”。该研究不仅深入剖析了为何这种方法有效,还提出了一种更优的生长策略LIDAS,在提升推理能力的同时,实现了高达1.29倍的训练加速!
两种“生长式”Transformer:MIDAS与LIDAS
这项研究的核心思想借鉴了渐进式堆叠(gradual stacking)的理念,即在训练过程中逐步增加模型的深度。想象一下,我们不是一开始就训练一个庞然大物,而是从一个小模型开始,在训练到一定阶段后,在模型的“腰部”(中间位置)插入新的网络层,让它“长高”,然后继续训练。
研究首先复现了前人提出的MIDAS方法,它通过在模型中间复制整个Transformer块(block)来实现增长。实验证实,这种方法确实能提升模型的推理性能。
在此基础上,研究团队提出了一个更精妙的变体——LIDAS。与MIDAS粗犷地复制整个块不同,LIDAS在插入新层时,巧妙地交错融合了相邻层的权重。这种设计旨在提供一个更平滑、更有效的初始化,从而更好地保留和传递学习到的知识。
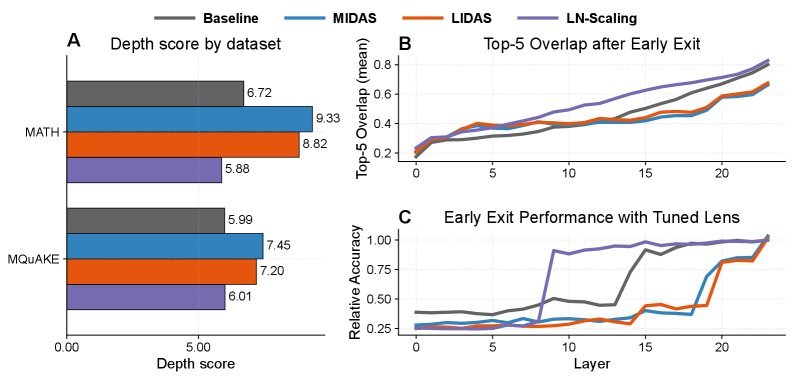
图1:在多个指标上,生长式模型(MIDAS, LIDAS)都表现出比基线模型更强的深度利用率。
实验结果令人振奋。无论是在360M还是1.7B参数规模的模型上,MIDAS和LIDAS在数学和推理任务上的表现都超越了传统训练的基线模型。更重要的是,LIDAS在提升推理能力的同时,并未牺牲通用的语言建模性能,综合表现更胜一筹。
深度诅咒真的被破解了吗?
为了回答这个问题,研究者们进行了一系列“深度”诊断。他们发现:
-
后期层变得至关重要:在传统模型中,跳过或移除最后几层可能对性能影响不大。但在MIDAS和LIDAS模型中,这样做会导致性能急剧下降。如图1(C)所示,生长式模型的准确率直到最后一层仍在持续攀升,而基线模型在约18层后就已饱和。
-
深度得分更高:研究者使用“深度得分”这一指标来量化模型对深层网络的依赖程度。结果显示,生长式模型在各项任务上,尤其是数学任务上,获得了显著更高的深度得分(图1A)。
这些证据共同表明,渐进式生长确实能有效对抗“深度诅咒”,促使模型将重要的计算任务分配到网络的更深层次,让每一层都物尽其用。
可重排的计算模块:深层网络的新结构
更有趣的发现还在后面。生长式训练似乎催生出了一种全新的网络结构——可重排的计算模块(permutable computational blocks)。
研究者做了一个大胆的实验:交换模型中不同块(block)的位置。对于传统模型,这种“大手术”几乎是致命的,会导致性能断崖式下跌。然而,MIDAS和LIDAS模型却表现出惊人的鲁棒性。即使是交换多达4个连续层组成的块,它们的性能也仅有轻微下降。
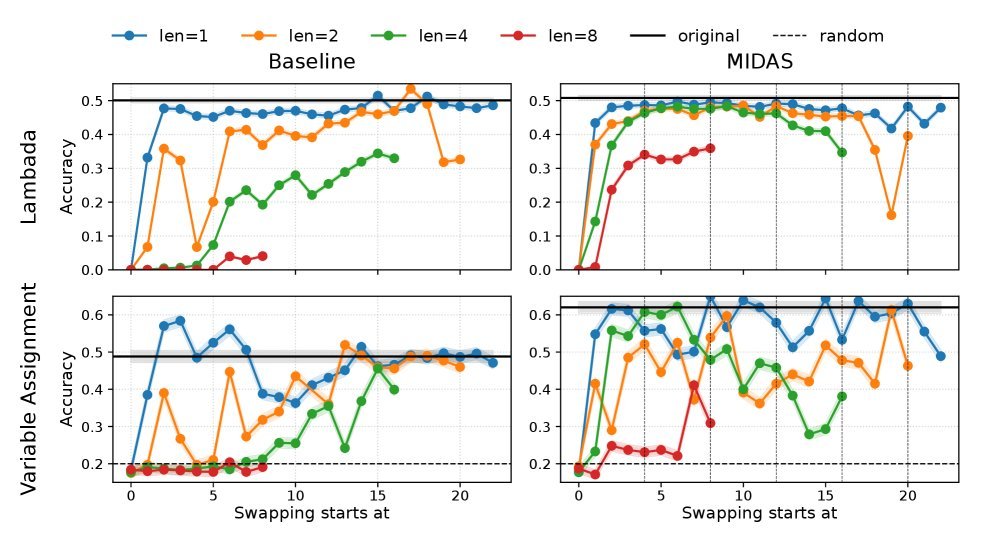
图3:在交换层块的实验中,生长式模型(MIDAS, LIDAS)比基线模型表现出更强的鲁棒性,尤其是在交换大尺寸块时。
这表明,生长式训练让模型学会了功能相似但可互换的“计算单元”。模型不再严重依赖于特定层的绝对位置,而是形成了一种类似循环或递归的计算模式。每个模块负责一部分计算,它们之间可以有一定程度的自由组合。
LIDAS:更对称、更高效的生长策略
既然生长式训练如此有效,那么如何“生长”才是最优的呢?这正是LIDAS的闪光点。
研究发现,MIDAS的块复制策略会导致一种不对称的权重结构。而LIDAS通过更精细的层级交错复制,创造出了更对称的权重分布。这种对称性更接近于循环Transformer(Looped Transformer)的理论思想,即反复应用同一个计算单元。
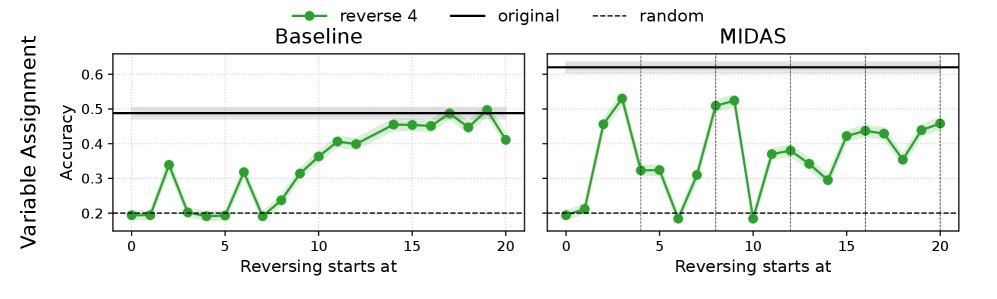
图7:(a) LIDAS的权重相似性(左)比MIDAS(中)更对称。(b) 在中间层跳过注意力子层时,LIDAS(右)受到的影响比MIDAS(中)更大,表明其注意力层参与度更高。
分析显示(图7),LIDAS不仅在权重结构上更对称,其注意力子层在网络中部的参与度也更高。这意味着LIDAS能更有效地利用注意力机制来处理和传递信息,这或许是其在推理任务上表现更优的深层原因。
结论
这项研究为我们揭示了LLM训练的一种全新范式。通过在训练中“动态生长”,模型可以自发地学习到一种高效的、可重复的计算结构,从而有效克服“深度诅咒”的限制。
该研究提出的LIDAS方法,作为一种轻量级的改进,不仅在推理性能上超越了以往的方法,还带来了29%的训练加速。这无疑为未来开发更高效、更强大的语言模型铺平了道路。或许,未来的LLM不再是静止的庞然大物,而是在学习中不断进化、生长的“有机体”。