LLM长文本“失效”有救了!DoPE:免训练为RoPE降噪,解锁64K超长上下文

当大语言模型(LLM)处理的文本越来越长,我们常常会发现一个令人沮丧的现象:模型好像“忘记”了开头的内容,注意力过度集中在最近的文本上。这就是所谓的“注意力沉没”(Attention Sink)问题。即使是像旋转位置编码(Rotary Position Embedding, RoPE)这样先进的技术,也难以幸免。
论文标题:DoPE: Denoising Rotary Position Embedding
ArXiv URL:http://arxiv.org/abs/2511.09146v1
现在,一篇来自中科院、港大等机构的论文提出了一个无需训练、即插即用的解决方案——DoPE(Denoising Rotary Position Embedding)。它通过给位置编码“降噪”,显著提升了模型在长达64K上下文任务中的表现。
RoPE的“噪声”问题
我们知道,LLM依赖位置编码来理解Token的顺序。RoPE通过旋转Query和Key向量来编码相对位置,因其高效性而成为主流选择。
然而,该研究发现,RoPE并非完美无缺。在长序列中,某些低频的旋转分量会产生异常大的数值,形成所谓的“异常通道”(outlier channels)。
这会导致注意力矩阵中出现刺眼的“亮带”,使得模型不自觉地将过多注意力分配给少数几个位置(比如句首或句尾),而忽略了中间的关键信息。
DoPE的研究者们换了一个新视角:他们将带有位置编码的注意力图视为一张“带噪特征图”,而这些异常的低频分量就是“噪声”的来源。
用“熵”来诊断噪声
如何精准地识别并清除这些“噪声”呢?DoPE引入了一个优雅的物理学概念:截断矩阵熵(Truncated Matrix Entropy)。
简单来说,这个指标可以衡量每个注意力头中,位置编码信息分布的“混乱”程度或“有效秩”。
-
低熵:表示位置编码的能量高度集中在少数几个维度上,形成了“尖峰”结构。这些就是产生“注意力沉没”的“坏”头。
-
高熵:表示位置编码的能量分布更均匀、更平衡。这些是表现良好的“好”头。
通过计算每个注意力头的截断矩阵熵,DoPE能够像医生一样,精确地“诊断”出哪些头是“生病”的,需要进行“降噪”处理。
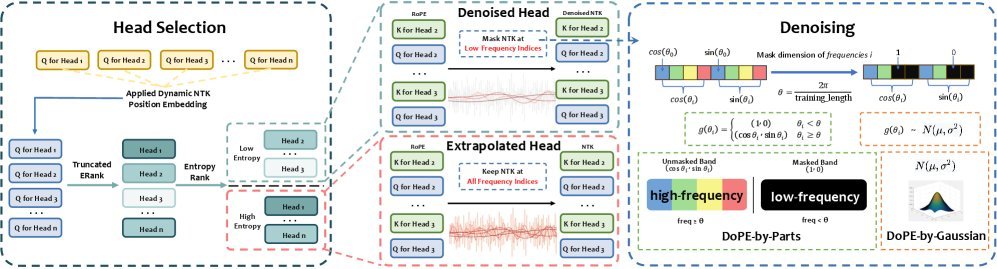
图1:DoPE方法的可视化解释
三种“降噪”手术
诊断出问题后,DoPE提供了几种简单而有效的“降噪”策略,它们都无需重新训练模型:
-
DoPE-by-parts:仅移除或衰减那些被识别为“低熵”的特定频率分量。
-
DoPE-by-all:更直接,直接禁用整个“低熵”注意力头的位置编码功能。
-
DoPE-by-Gaussian:一种更平滑的处理方式。在禁用“低熵”头的位置编码后,用参数无关的高斯噪声取而代之。研究发现,这种方法效果出奇地好,因为它恰好模拟了多层网络中噪声累积的效应。
实验效果:大海捞针也无妨
为了验证效果,研究者们设计了严苛的“大海捞针”(Needle-in-a-Haystack)测试。即在数万字的文本中插入一句关键信息(“针”),看模型能否准确地找出来。
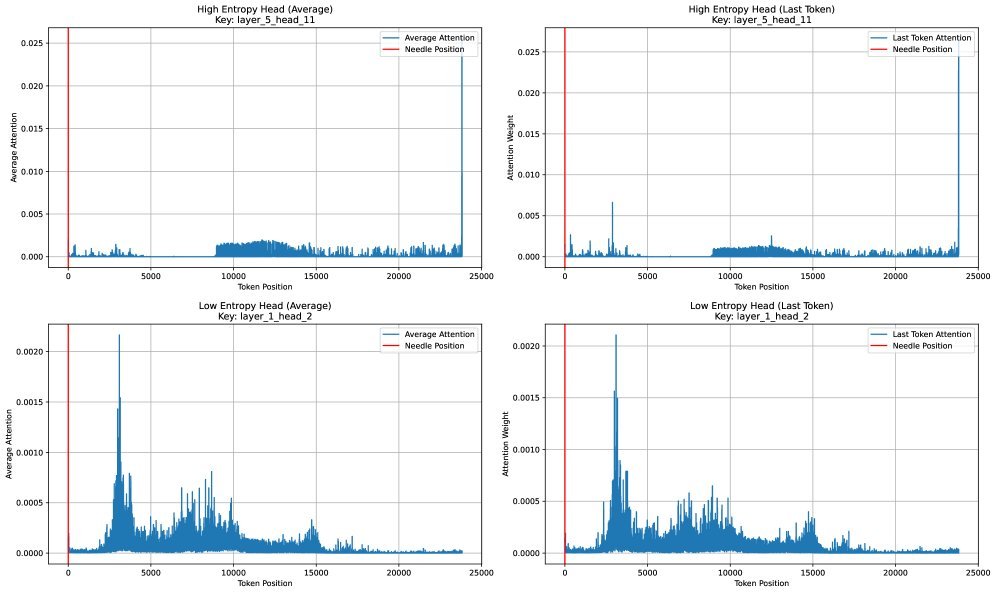
图2:DoPE处理前后,注意力熵的对比。处理后(右图),注意力分布更均衡,成功定位到“针”的位置。
实验结果非常惊人:
-
在64K的超长上下文中,基线模型性能严重下降,而应用DoPE后,检索准确率得到显著提升。
-
在人为添加干扰(模拟注意力沉没)的“噪声”设置下,DoPE展现出强大的鲁棒性,性能远超基线模型。例如,在24K的噪声设置下,DoPE将准确率从75.4%提升至84.4%。
-
实验还发现,截断矩阵熵为1(等价于谱范数)时,在极稀疏(如64K上下文)场景下效果最好,这表明上下文越长,奇异值分布越“尖锐”。
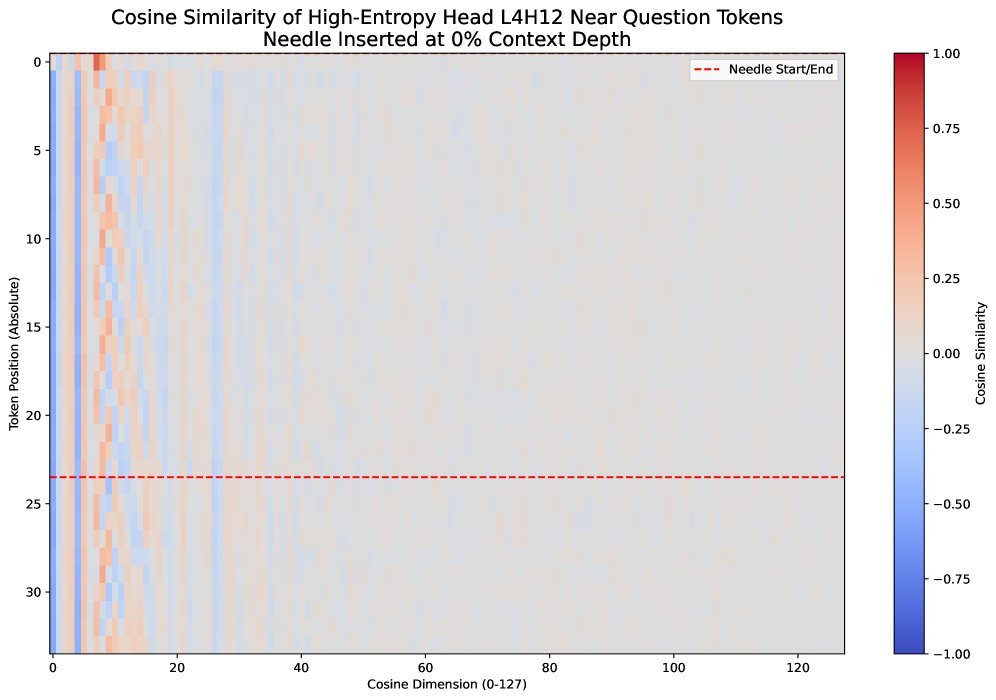
图3:一个被截断矩阵熵识别为“低秩”的注意力头,其相似度矩阵呈现明显的周期性和低秩结构。
熵、低秩与注意力沉没
这项研究最深刻的洞见在于,它揭示了截断矩阵熵、低秩结构和注意力沉没三者之间的内在联系。
被截断矩阵熵识别出的“坏”头,其Query向量在特征空间中表现出明显的“低秩”特性——即它们只利用了非常有限的几个维度来编码位置。
正是这种低秩性,导致了注意力分布的僵化和“沉没”现象。DoPE通过识别并修正这些低秩、低熵的注意力头,恢复了注意力机制的灵活性和平衡性。
结论
DoPE方法为解决LLM的长文本外推问题提供了一个全新的、无需训练的视角。它通过引入“截断矩阵熵”这一强大的诊断工具,精准识别并“降噪”RoPE中的有害成分,有效缓解了“注意力沉没”问题。
这项工作不仅提供了一个即插即用的性能提升工具,更重要的是,它加深了我们对Transformer中位置编码工作机理的理解,为未来设计更优秀的位置编码方案指明了方向。简单,却异常强大。