DR. WELL: Dynamic Reasoning and Learning with Symbolic World Model for Embodied LLM-Based Multi-Agent Collaboration
-
ArXiv URL: http://arxiv.org/abs/2511.04646v1
-
作者: Narjes Nourzad; Carlee Joe-Wong; Hanqing Yang
-
发布机构: Carnegie Mellon University; University of Southern California
TL;DR
本文提出了DR. WELL,一个去中心化的神经符号框架,该框架通过结构化的协商协议和动态演化的符号世界模型,使基于大语言模型(LLM)的具身智能体能够高效地进行协作规划、学习与自我优化。
关键定义
本文提出或沿用了以下几个核心概念:
-
DR. WELL (Dynamic Reasoning and Learning with Symbolic World Model):一个去中心化的神经符号规划框架。它使基于LLM的智能体能够通过一个动态世界模型,在相互依赖的任务中进行协作。该框架的核心是结构化通信和基于经验的符号规划。
- 两阶段协商协议 (Two-phase negotiation protocol):一种结构化的通信机制,用于在去中心化智能体之间分配任务。
- 提议阶段 (Proposal stage):空闲的智能体根据世界模型提供的历史经验,各自提议一个候选任务并陈述理由。
- 承诺阶段 (Commitment stage):智能体在共识和环境约束下,对任务分配达成最终一致,并作出承诺。
- 符号世界模型 (Symbolic World Model, WM):一个共享的、动态的符号知识库,是智能体协作与推理的基础。它以分层图的形式组织知识,记录环境状态、智能体行动和任务结果,并在多个回合中不断演化,积累经验。它在两个关键阶段发挥作用:
- 协商指南 (Negotiation guidebook):在协商阶段,提供历史任务的成功率、耗时等统计数据,帮助智能体做出更明智的决策。
- 规划库 (Plan library):在规划阶段,提供过去成功的抽象规划原型 (prototypes) 和具体的规划实例 (instances),帮助智能体生成和优化自己的规划。
- 符号规划与执行 (Symbolic Planning and Execution):智能体不直接生成详细的底层运动轨迹,而是生成由高级宏观动作(如 \(align\), \(push\))组成的序列。执行控制器负责检查每个动作的前提条件并将其转化为底层动作,而环境则验证动作的最终效果。
相关工作
当前,在多智能体强化学习 (MARL) 中实现可泛化的协作行为仍然是一个挑战。虽然近期研究引入了大语言模型 (LLM) 以提升灵活性,但在去中心化的具身环境中,直接使用LLM输出的策略非常脆弱。这主要是因为智能体需在部分可观测、通信受限和异步执行的条件下协调,且LLM对提示词非常敏感,难以泛化到不同的智能体数量或环境条件。
将协调建立在底层轨迹层面容易失败,因为微小的时间或移动偏差会迅速累积并导致冲突。因此,研究的瓶颈在于如何在不依赖中心化控制和脆弱的底层对齐的情况下,实现稳定、高效的多智能体协作。
本文旨在解决这一问题:如何通过提升抽象层次,让去中心化的具身LLM智能体在有限通信下,实现鲁棒、可解释且能够通过经验学习不断优化的协作规划。
本文方法
本文提出了DR. WELL框架,这是一个结合了神经方法(LLM的推理能力)和符号系统(结构化表征与规划)的去中心化协作框架。其核心设计在于通过符号抽象来简化协调问题。
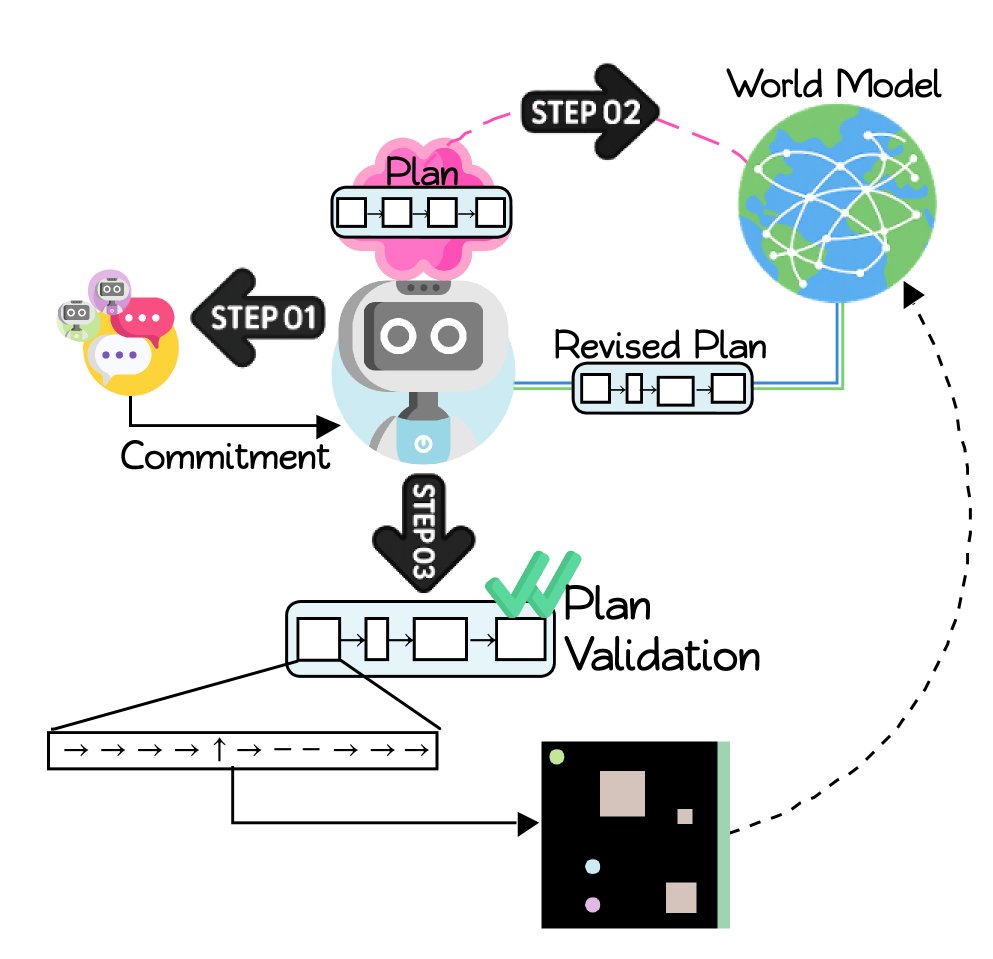
协商协议
当一个或多个智能体变为空闲状态时,它们会进入一个共享的“通信室”,并触发一个结构化的两轮协商协议来分配任务。
- 提议阶段:每个空闲智能体按照轮询顺序,向世界模型(WM)查询历史数据(如任务成功率、平均耗时等),然后提出一个它认为最合适的任务(例如,在推箱子任务中选择一个特定的箱子),并附上简短的理由。
- 承诺阶段:所有智能体共享彼此的提议,并根据共识(如投票)和环境约束(如一个任务所需的最少智能体数量),最终确定每个智能体的任务分配。
这种设计将通信限制在必要的同步点,避免了持续的“自由交谈”,提高了通信效率,并确保智能体在行动前就对协作目标达成了一致。
符号规划与执行
任务承诺一旦确定,每个智能体便独立地进入规划与执行循环。
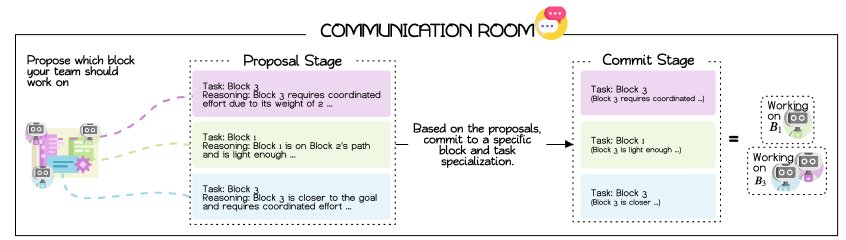
- 生成与修订规划:每个智能体利用其LLM,基于已承诺的任务生成一个初步的符号规划草案。然后,它查询共享的世界模型(WM),利用其中存储的成功规划原型和实例来修订和优化该草案,使其更有效、更符合当前情境。最终的规划是一个由预定义词汇表中的符号化宏观动作(如\(sync\), \(align\), \(push\))组成的序列。
- 执行与验证:一个符号控制器负责逐一执行规划中的动作。
- 前提条件检查:控制器在本地检查每个动作的前提条件是否在当前世界状态下满足。例如,一个需要2个智能体协作的\(push\)动作,只有当2个智能体都\(align\)到指定位置时才能执行。
- 后置条件验证:动作的实际效果由环境来验证。控制器将符号动作翻译为底层移动指令并执行,环境会报告动作是否成功实现了预期的效果。
- 失败处理:如果前提条件不满足(如等待协作伙伴超时),动作失败,规划将跳至下一步或中止。如果规划执行完毕或失败,智能体返回空闲状态,准备新一轮的协商。
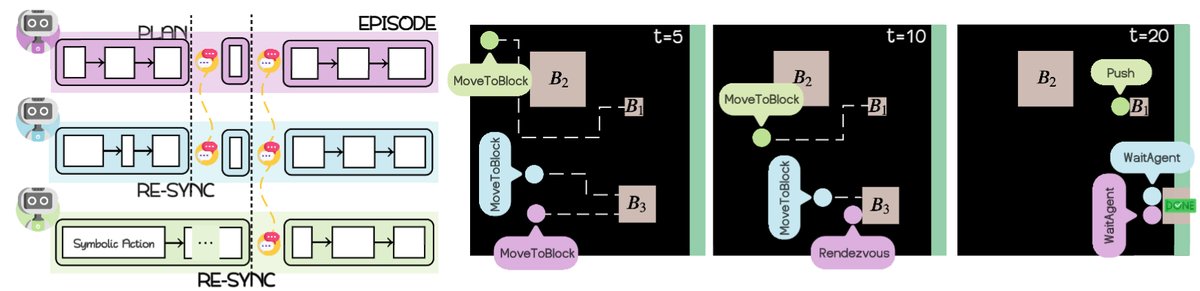
世界模型 (WM)
世界模型是该框架的创新核心,它既是共享的记忆库,也是学习和优化的引擎。
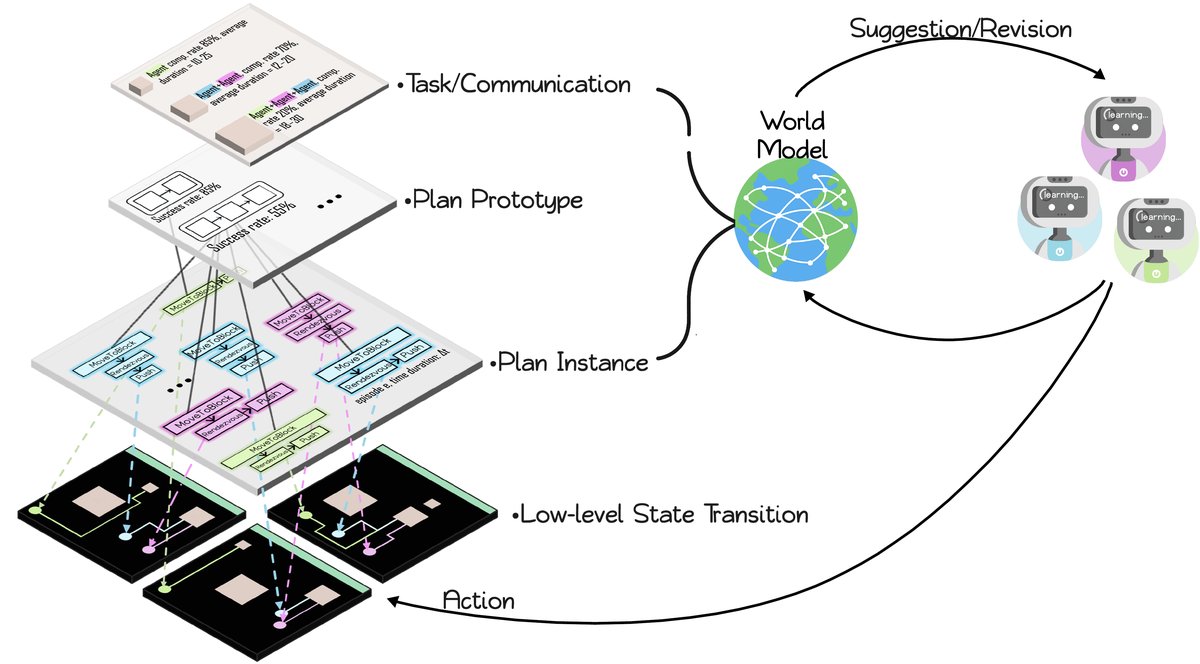
创新点
-
动态演化的分层图结构:WM被构建为一个动态的符号图,其形式为:
\[\mathcal{G=(V,E)},\quad\mathcal{V=V_{epi}}\cup V_{task}\cup V_{proto}\cup V_{inst},\quad E=E_{epi\rightarrow task}\cup E_{task\rightarrow proto}\cup E_{proto\rightarrow inst}\]其中,节点分为四个层级:回合 (episodes)、任务 (tasks)、规划原型 (plan prototypes,即抽象的动作序列) 和规划实例 (plan instances,即带具体参数的动作序列)。每个新的回合都会向图中添加新的节点和边,图结构随经验积累而不断丰富。
\[\mathcal{G}_{k+1}=\mathcal{G}_{k}\cup\Delta\mathcal{G}_{k}\]这种结构将高层的抽象(任务)与底层的执行结果(规划实例的成败)联系起来,使得模型能捕捉可复用的协作模式。
-
双重功能:
- 协商指南 (Negotiation guidebook):在协商时,WM向智能体提供关于各任务历史表现的统计数据,如尝试次数、成功率、平均时长等,为智能体提议任务提供数据支持。
- 规划库 (Plan library):在规划时,WM提供针对特定任务的、按成功率排序的规划原型和实例。智能体可以借鉴这些成功的经验来生成和修订自己的规划,实现自我优化。
通过这种方式,WM将分散的、个体的经验整合为集体智慧,引导智能体群体朝着更高效的协作策略演化。
实验结论
本文在定制的协作推箱子环境 (Cooperative Push Block, CUBE) 中对DR. WELL框架进行了评估。在该环境中,推动不同尺寸的箱子需要不同数量的智能体协作。
基线智能体表现
基线智能体以零样本方式运行,没有协商、共享记忆或通信机制,仅根据固定提示(总是处理离目标最近的箱子)独立决策。
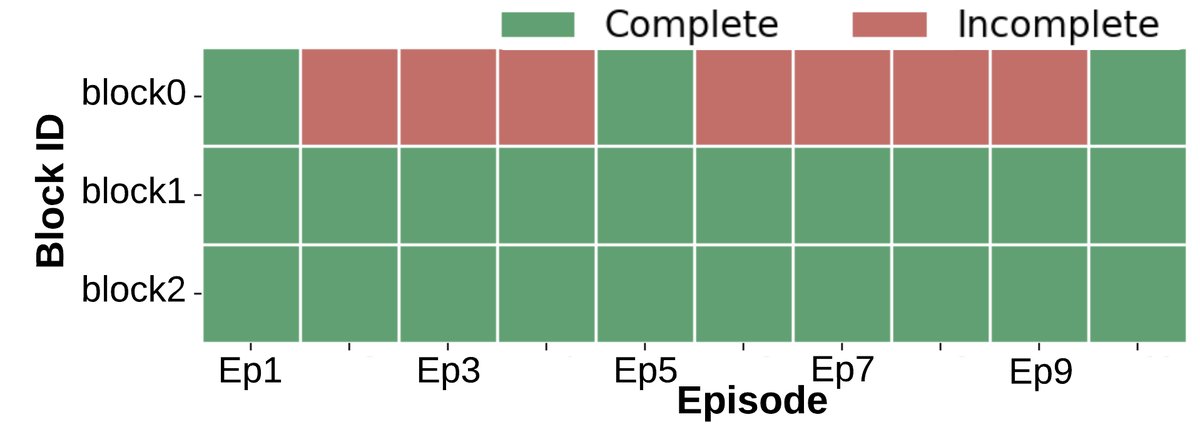
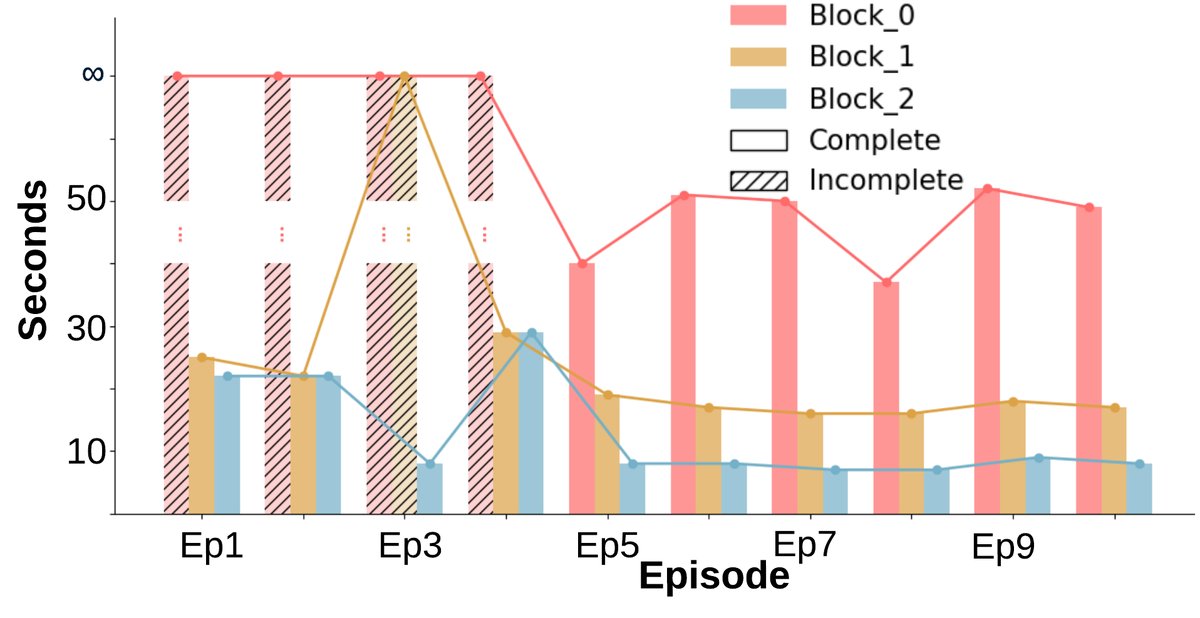
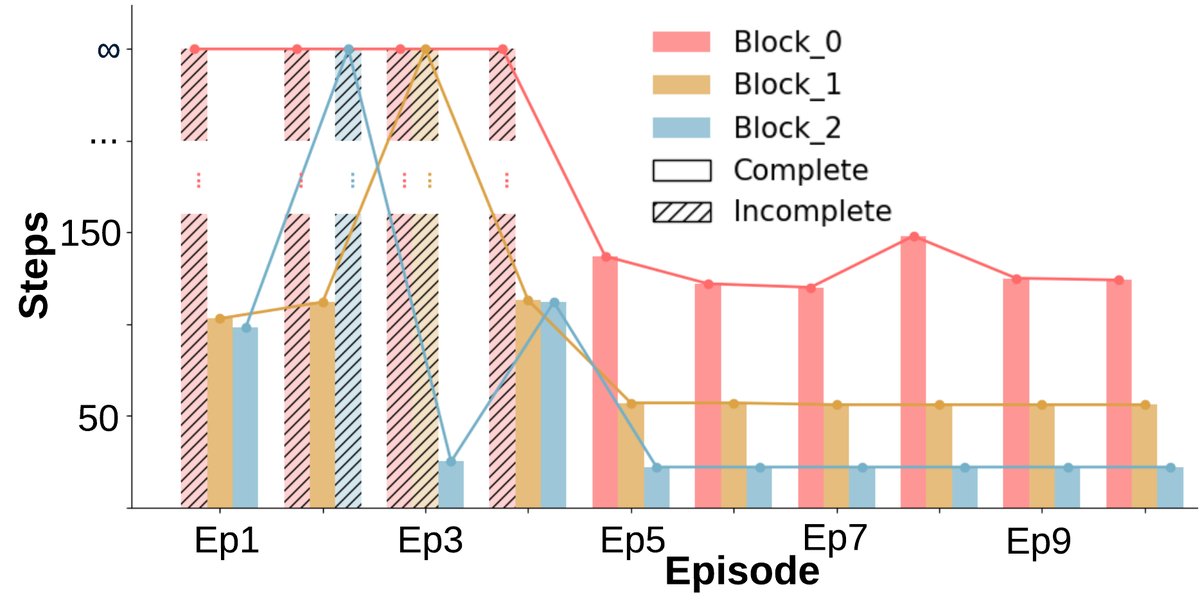
- 无学习迹象:任务完成情况(图a)呈现二元模式(完成或未完成),没有随回合数增加而改善。完成时间(图b, c)也基本保持不变。
- 效率低下:所有智能体倾向于涌向同一个箱子,即使该任务不需要多人协作,导致资源浪费。
DR. WELL 框架表现
DR. WELL框架下的智能体通过共享的世界模型和协商协议进行协调。
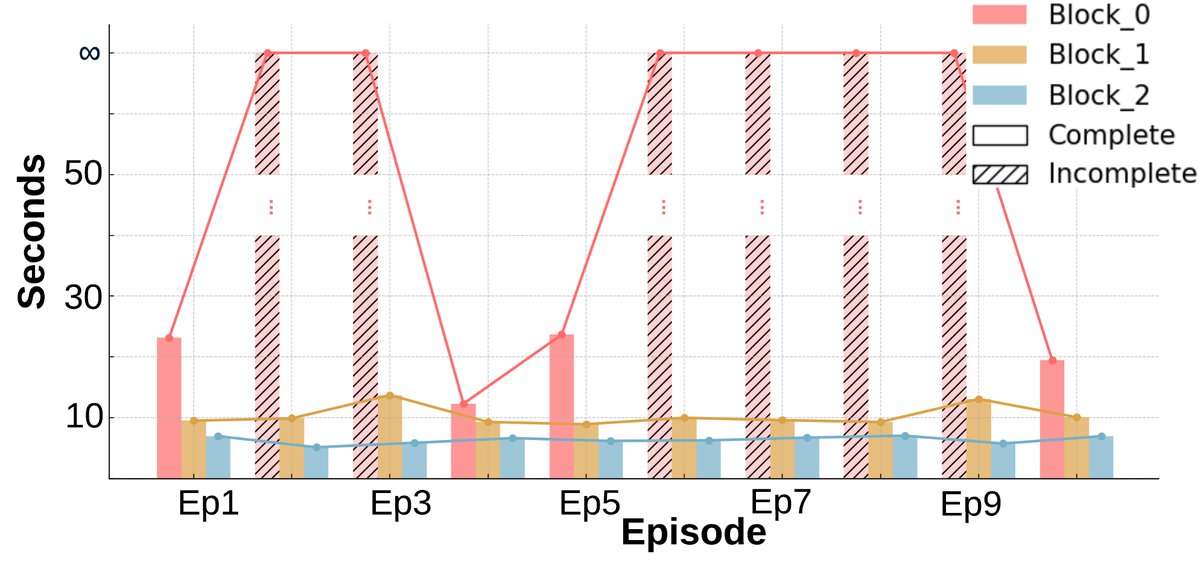
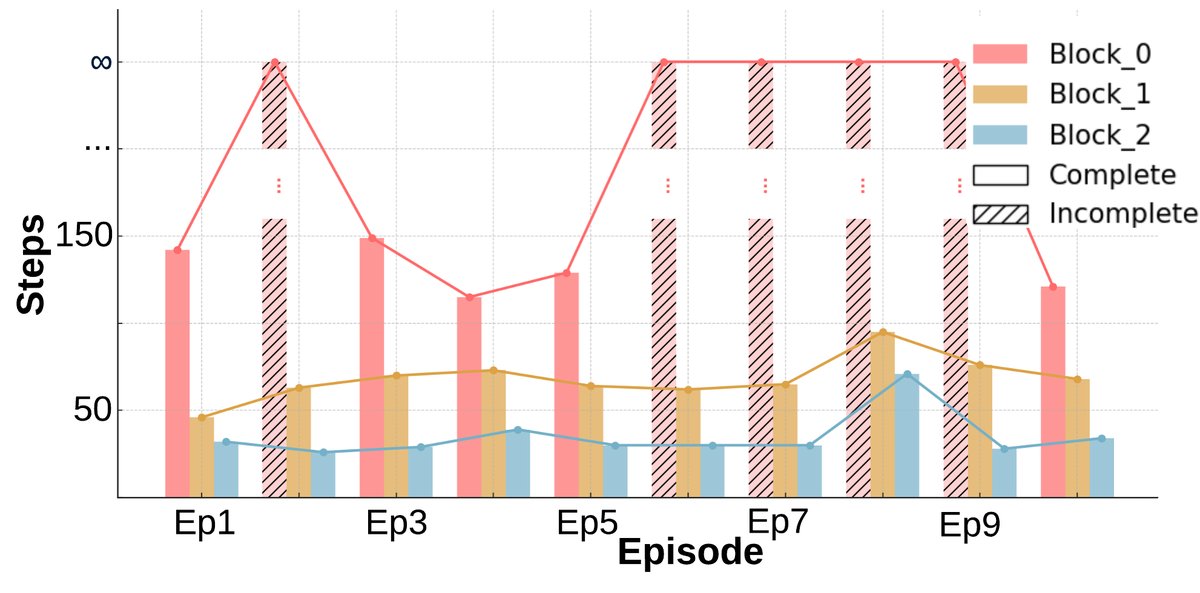
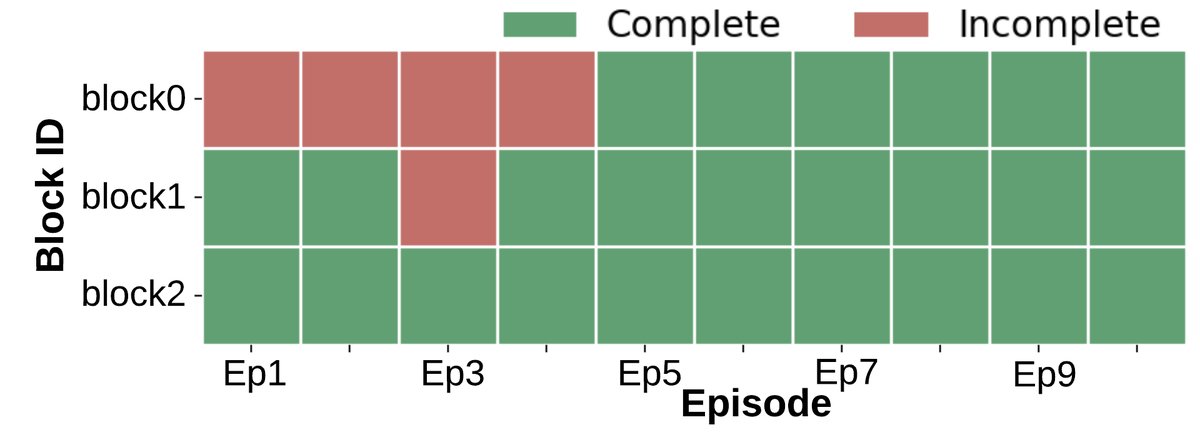
- 显著的学习与适应性:与基线不同,在早期回合后,几乎所有箱子都能被稳定完成(图a)。完成任务所需的环境步数(图b)和墙上时钟时间(图c)均呈现明显的下降趋势,表明智能体学会了更高效的策略。
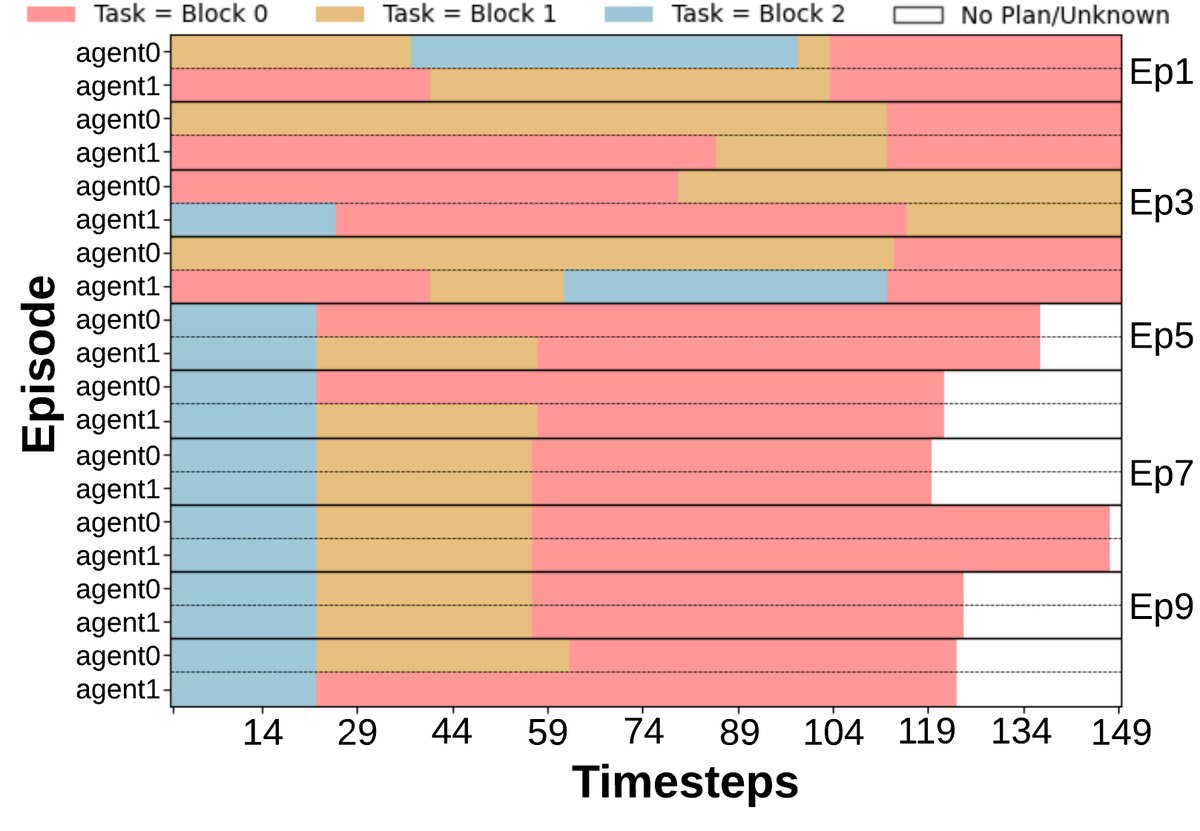
- 协作效率提升:任务承诺模式(图d)显示,经过几个回合后,智能体能够达成稳定的分工,减少了不必要的任务重叠。
- 成本与收益:尽管协商和重新规划带来了一些额外的墙上时钟时间开销,但总的环境交互步数显著下降。这表明智能体用少量规划时间换取了更高效的物理执行,整体协作效率更高。
世界模型的演化
通过可视化世界模型的图结构,可以看到其随回合数增加而演化的过程。
- 从第1回合的稀疏图,到第5回合的结构初现,再到第10回合的密集图,WM清晰地记录和组织了任务、可复用的规划模式以及具体的执行案例。这证明了WM不仅是日志记录器,更是一个能够整合经验、提炼抽象知识的动态记忆系统。
 回合 1 |  回合 5 |  回合 10 |
总结
实验结果有力地证明,本文提出的DR. WELL框架通过结合结构化协商和动态符号世界模型,使LLM智能体群体能够从经验中学习,逐步优化其协作策略,从而在多智能体协作任务中取得更高的完成率和执行效率。