Dynamic Affective Memory Management for Personalized LLM Agents
-
ArXiv URL: http://arxiv.org/abs/2510.27418v1
-
作者: Yueyan Li
-
发布机构: Beijing University of Posts and Telecommunications
TL;DR
本文提出了一种名为DAM-LLM的动态情感记忆管理系统,通过引入基于贝叶斯的更新机制和记忆熵概念,使智能体能够自主维护一个动态更新的记忆数据库,以解决传统静态记忆的冗余、过时和一致性差的问题,从而提供更具个性化的情感交互。
关键定义
本文提出或沿用了以下几个核心概念:
-
信誉加权记忆单元 (Confidence-Weighted Memory Units):本文提出的核心数据结构,用于封装用户对特定实体特定方面的情感。它不记录孤立的事实,而是将用户情感表示为一个动态更新的概率分布(或称置信度分布),通过贝叶斯更新机制整合新的观测证据。
-
类贝叶斯更新机制 (Bayesian-Inspired Update Mechanism):一种用于整合新观测数据的算法。它将记忆单元中现有的情感置信度视为“先验信念”,将新的用户输入视为“观测证据”,通过加权平均的方式计算出“后验信念”,从而平滑地更新记忆。其核心公式为:$C_{\text{new}}=(C\times W+S\times P)/(W+S)$,其中 $C$ 是旧置信度,$W$ 是旧权重,$S$ 是新证据强度,$P$ 是新证据的置信度。
-
信念熵 (Belief Entropy):用于量化单个记忆单元不确定性的指标。其定义为 $H(m)=-\sum_{k\in{\text{pos,neg,neu}}}p_{k}\log_{2}p_{k}$,其中 $p_k$ 是情感极性 $k$ 的归一化置信度分数。低熵表示高确定性,高熵表示高不确定性或“困惑”。信念熵是驱动记忆压缩和优化的核心信号。
-
熵驱动压缩 (Entropy-Driven Compression):一种旨在对抗记忆膨胀的算法。它在检索过程中通过修剪和合并低价值或过时的观测来最大化记忆库的信息密度。该过程由最小化全局信念熵的目标驱动,包括合并相似记忆和删除高熵、低权重的“噪声”记忆。
相关工作
目前,在情感对话领域,主流研究集中于利用强化学习等方法让智能体在实时交互中动态调整情感策略,以实现更好的交互结果。然而,这些工作普遍忽略了如何对用户的长期情感历史进行持久化存储、演化更新和有效利用,未能形成一个连贯的、具有个性化认知的记忆系统。
在智能体记忆管理领域,现有架构大多基于检索增强生成(Retrieval-Augmented Generation, RAG)。尽管有工作通过混合检索、优化检索过程(如Selfmem)或构建外部记忆库(如MemoryBank)来改进,但仍存在两大瓶颈:
- 静态和不连贯的记忆:传统方法将交互存储为孤立事实的集合,无法综合多次互动形成对用户的演进式理解,导致在用户态度变化时出现矛盾。
- 记忆膨胀和噪声:无差别地存储所有交互导致记忆库无限增长,增加了检索延迟和计算开销,同时引入大量噪声,使得关键信息难以被检索,即“大海捞针”问题。
本文旨在解决上述问题,特别是如何对长期情感记忆进行动态建模和管理,以克服传统RAG架构在处理情感波动时的局限性,并维持记忆的一致性和效率。
本文方法
本文提出了一种用于情感对话的智能体框架DAM-LLM,其核心是动态情感记忆管理。该框架通过最小化全局信念熵来优化记忆系统,将记忆管理从被动存储转变为主动认知过程。
系统架构
DAM-LLM包含三个核心组件:一个中央主智能体 (Master Agent)、一个两阶段混合检索模块和一个分布式记忆单元网络。这三者构成一个闭环认知架构。系统通过最小化全局信念熵 $\sum_{m\in M}H(m)$ 来驱动记忆的动态优化,以最大化对用户偏好建模的确定性。主智能体利用信念熵这一全局感知信号,协调记忆的贝叶斯更新、语义检索和熵驱动压缩等操作。
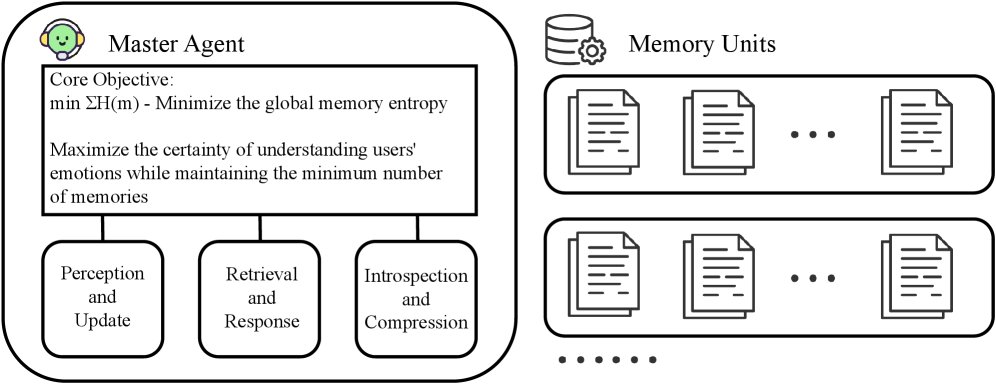
DAM-LLM 智能体
系统的协作流程由多个智能体共同完成,形成一个从问题理解到记忆操作再到响应生成的完整闭环。
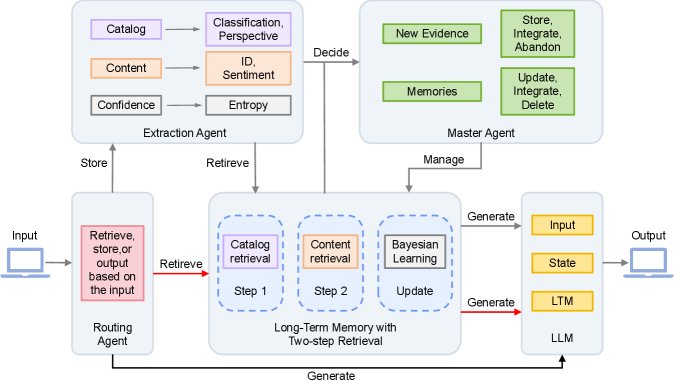
-
输入路由 (Input Routing):路由智能体分析用户意图,决定当前输入是应触发记忆的存储 (Store)、检索 (Retrieve),还是直接生成 (Generate) 响应。
-
证据分析与处理 (Evidence Analysis and Processing):当需要记录用户输入 $x_t$ 时,提取智能体(Extraction Agent)会将其解析为结构化的情感信息,形式为 $\mathrm{\textit{E}\text{-}Agent}(x)\rightarrow E,Q,C,S$,分别代表情感描述、检索查询、情感置信度向量和证据强度。
-
记忆更新与压缩 (Memory Update and Compression):主智能体根据记忆库的当前状态,对新证据进行处理:
- 更新 (Update):将新证据通过类贝叶斯机制整合到现有记忆单元中,动态调整情感置信度,并刷新记忆单元的摘要描述。
- 合并 (Merge):识别并合并关于同一对象但不同方面的多个记忆单元,以形成更全面、熵更低的记忆。
- 删除 (Delete):对于持续表现出高熵和低权重的记忆单元,系统会判定其为“噪声”或过时信息,并将其删除,实现主动“遗忘”。
记忆单元 (Memory Unit)
记忆单元是情感记忆的核心,其创新设计在于将离散的情感观测转化为连续更新的置信度画像。
数据结构设计
每个记忆单元包含多个字段,用于结构化地存储情感信息。
| 字段名 | 描述 |
|---|---|
| \(object_id\) | 对象ID |
| \(object_type\) | 对象类型 |
| \(aspect\) | 方面 |
| \(sentiment_profile\) | 情感画像(置信度分数) |
| $H$ | 信念熵 |
| \(summary\) | 摘要 |
| \(reason\) | 原因 |
类贝叶斯更新机制
这是记忆单元实现自学习的关键。该机制通过加权平均的过程模拟贝叶斯更新,公式为:
\[C_{\text{new}}=(C\times W+S\times P)/(W+S), \quad W_{\text{new}}=W+S\]其中,$C$ 是当前的情感置信度(先验),$W$ 是其权重;$S$ 是新观测证据的强度,$P$ 是其置信度。这个机制使得高强度的证据能更有效地塑造情感画像,同时对低强度的偶然言论保持鲁棒性,从而实现记忆的平滑演进。
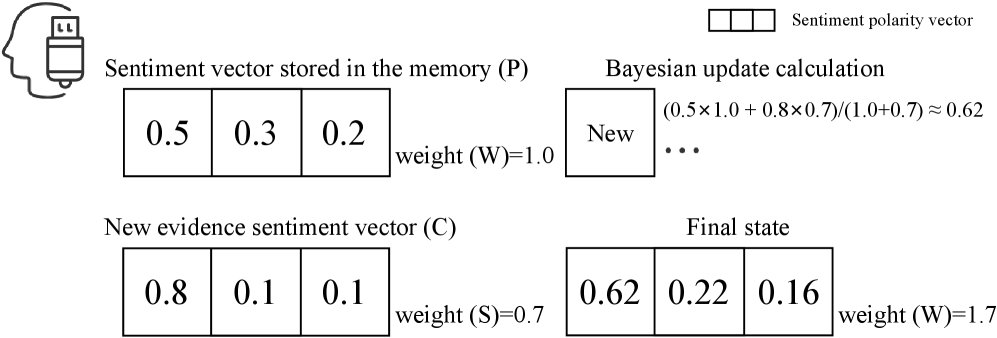
认知的信念熵
信念熵 $H(m) = -\sum_{k\in{\text{pos,neg,neu}}}p_{k}\log_{2}p_{k}$ 是衡量记忆单元认知确定性的统一指标。
- 低熵:表示系统对某个情感状态非常确定,是“健康”的记忆。
- 高熵:表示系统处于不确定或困惑状态,是“不健康”的,需要被优化。
主智能体的目标是最小化所有记忆单元的总熵。
两阶段混合检索
为解决传统向量检索中的语义漂移问题,本文设计了一种与记忆单元结构天然契合的两阶段混合检索机制。
- 第一阶段:基于元数据的过滤 (Metadata-Based Filtering):
- LLM解析用户查询,提取标准化的检索键,如 \(object_type\) 和 \(aspect\)。
- 利用这些元数据进行精确匹配,快速筛选出一个较小的候选记忆集,大幅缩小搜索范围。
- 第二阶段:语义重排 (Semantic Re-Ranking):
- 在候选集内,计算用户查询的语义向量与每个候选记忆摘要向量的余弦相似度。
- 根据相似度得分对候选记忆进行重排序,返回最相关的Top-K结果。
这种“粗筛-精排”的流程将分类任务与内容检索解耦,利用轻量级的元数据进行高效过滤,仅对高度相关的子集进行计算密集的语义匹配,从而确保了检索的准确性和可扩展性。
实验结论
数据集与实施
为评估系统在情感场景下的表现,本文构建了一个名为 DABench 的多轮对话数据集,专注于用户情感表达和情感变化。该数据集包含2500个观测序列、100个会话(共1000轮)的模拟用户交互以及500个查询-记忆对。实验以Qwen-Max为基础LLM,Text-Embedding-V1为文本嵌入模型。
记忆单元验证
- 功能验证:实验表明,记忆单元能够:
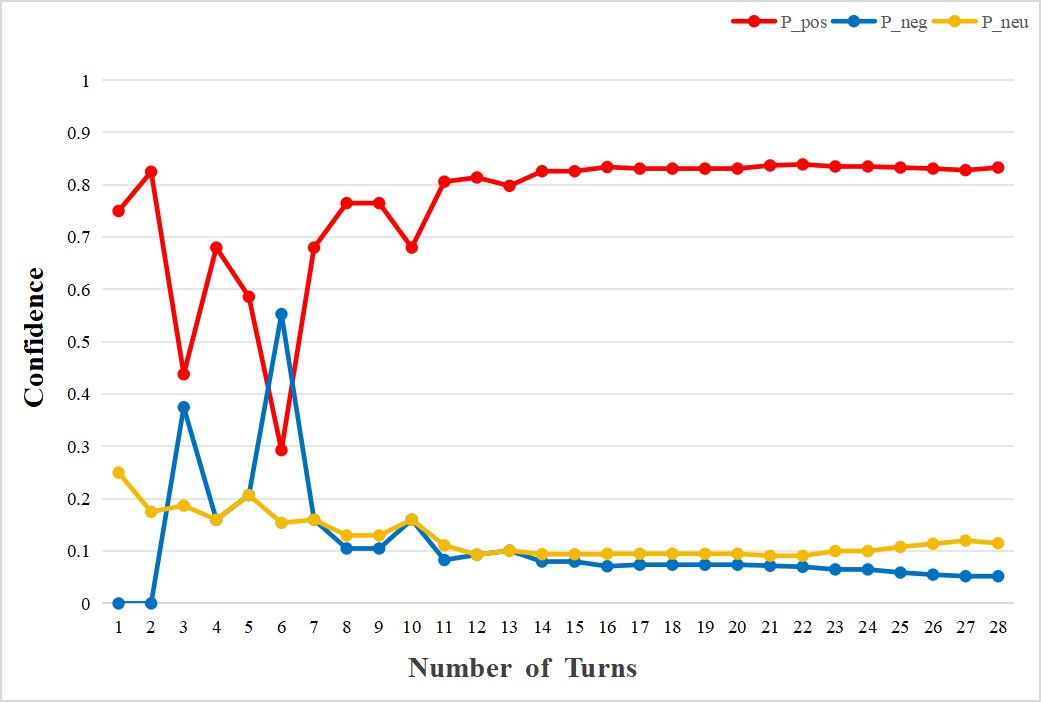
- 在持续交互中累积情感,构建连贯的情感画像(图a)。
- 在用户观点发生冲突时,通过动态重加权解决矛盾,实现情感平滑转变(图b)。
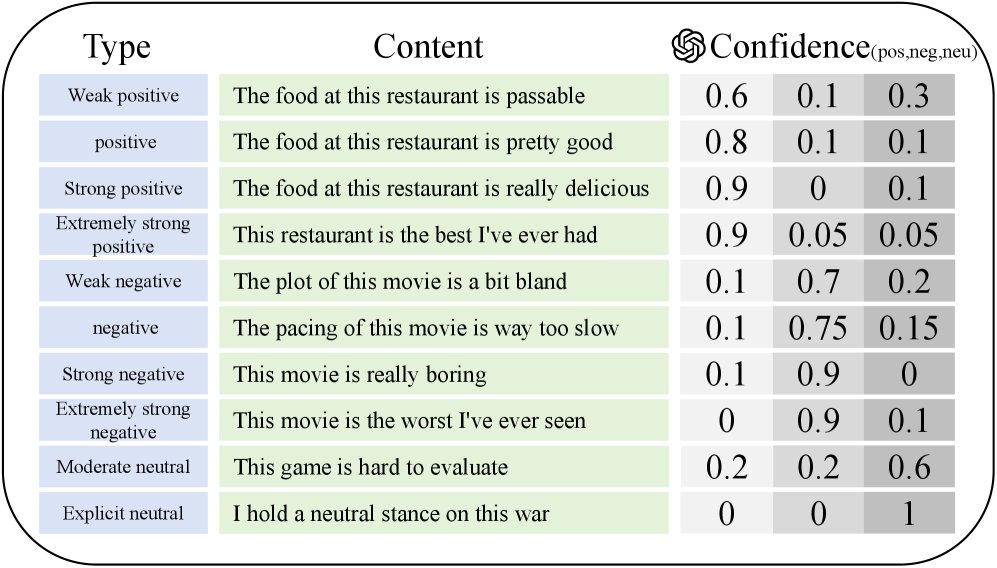
- 根据情感表达的强度给出不同等级的置信度分数,实现精细化评估(下图)。
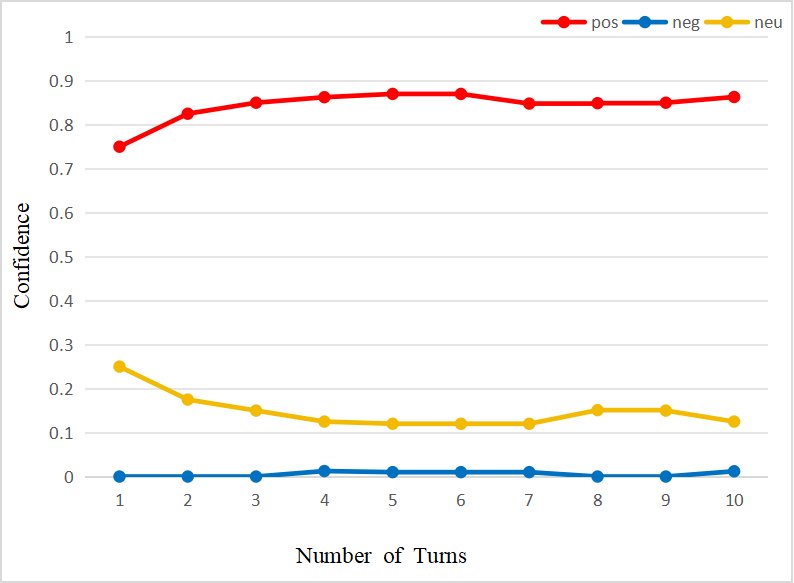
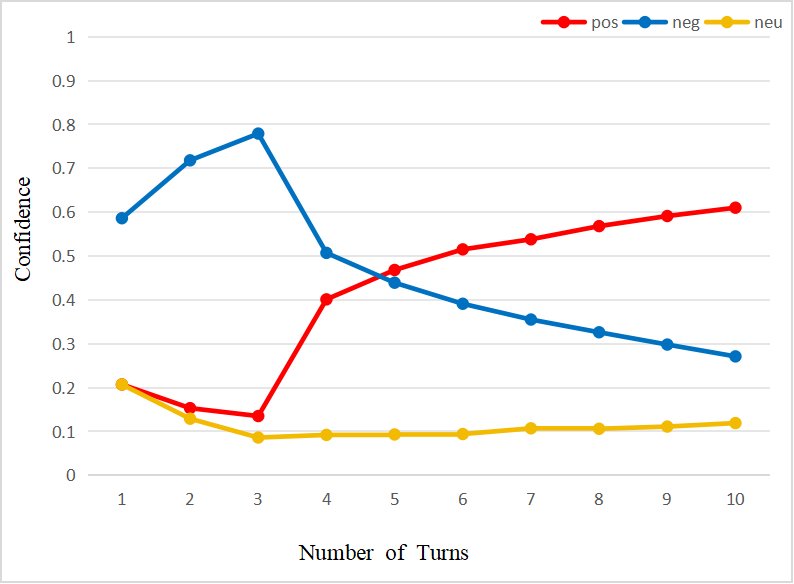
- 稳定性分析:对“咖啡(口味)”的30次观测显示,系统在约15次交互内快速形成初步置信度,随后随着证据积累,置信度曲线逐渐收敛并趋于稳定。该过程还验证了系统能有效地区分并独立存储同一对象的不同方面(如咖啡的口味与包装)。
压缩算法验证
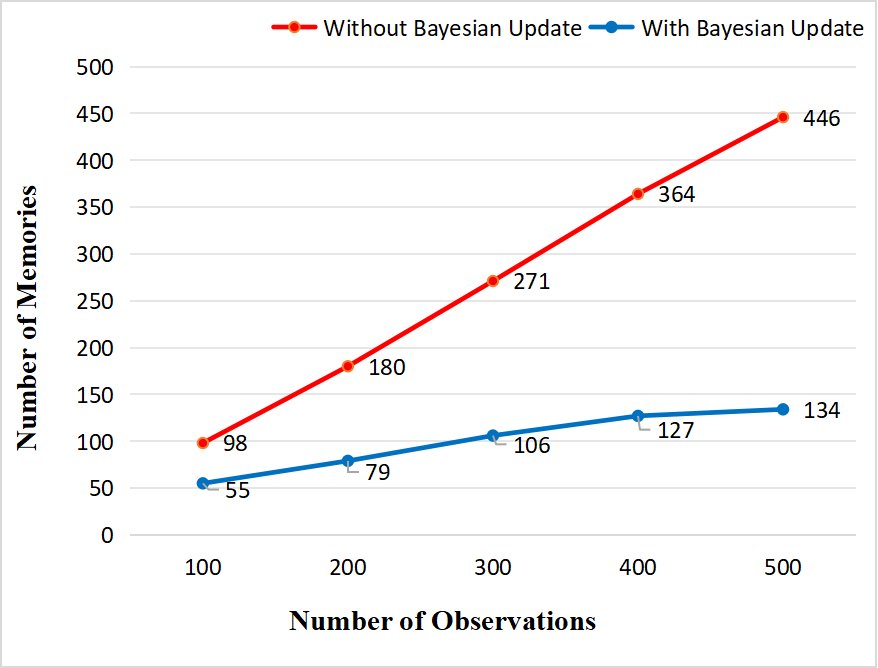
- 记忆增长控制:通过消融实验对比有无贝叶斯更新机制的系统,在处理500次对话后,不带更新机制的系统记忆量呈线性增长,而DAM-LLM的记忆压缩率达到 63.7% 至 70.6%,记忆单元数量稳定在130-140个左右,有效抑制了记忆膨胀。
系统性能评估
采用LLM-as-a-judge(GPT-4)方法,从六个维度对系统进行评估。
| 维度 | 基线模型 | DAM-LLM (本文) |
|---|---|---|
| 准确性 (AC) | 4.31 | 4.35 |
| 逻辑连贯性 (LC) | 4.02 | 4.28 |
| 记忆引用合理性 (RMR) | 3.86 | 4.25 |
| 情感共鸣 (ER) | 3.52 | 4.21 |
| 个性化 (Pers.) | 3.56 | 4.33 |
| 语言流畅性 (LF) | 4.67 | 4.54 |
实验结果表明,DAM-LLM在仅使用约40%内存的情况下,在情感共鸣和个性化维度上显著优于基线系统。特别是在处理大量冗余记忆或复杂情感演变的场景中,其优势更为明显。
总结
本文提出的DAM-LLM框架及其动态记忆系统,在实验中被证明是高效和有效的,为情感对话智能体的记忆架构发展提供了新的方向。