ELLA: Efficient Lifelong Learning for Adapters in Large Language Models
内存仅需1/35!亚马逊ELLA:无需回放的大模型终身学习新SOTA

大模型(LLM)虽然在预训练中展现了惊人的能力,但它们往往像是一个“记性不好”的学生:一旦开始学习新任务,就会迅速遗忘之前学过的知识。这就是著名的灾难性遗忘(Catastrophic Forgetting)。
ArXiv URL:http://arxiv.org/abs/2601.02232v1
为了解决这个问题,传统的终身学习(Continual Learning, CL)方法要么依赖“数据回放”(需要保存旧数据,涉及隐私和存储问题),要么采用严格的“正交投影”(强行让新旧知识互不干扰,却扼杀了知识迁移的可能性)。
最近,来自 AWS AI Labs 和普渡大学的研究团队提出了一种名为 ELLA 的新框架。它无需任何数据回放,也不增加模型推理负担,仅凭1/35的内存占用,就在多项基准测试中取得了SOTA性能,甚至还能提升模型对未见任务的Zero-shot能力。
告别“非黑即白”:ELLA的核心洞察
在终身学习中,我们面临着一对经典的矛盾:稳定性(Stability,记住旧知识)与可塑性(Plasticity,学习新知识)。
现有的基于适配器(Adapter,如 LoRA)的方法通常走极端:
-
完全隔离:强制新任务的参数更新与旧任务完全正交。这虽然保护了旧知识,但也切断了新旧任务之间的联系,导致模型随着任务增多,“可用的脑容量”越来越小。
-
完全混合:不加限制地更新,导致新知识直接覆盖旧知识。
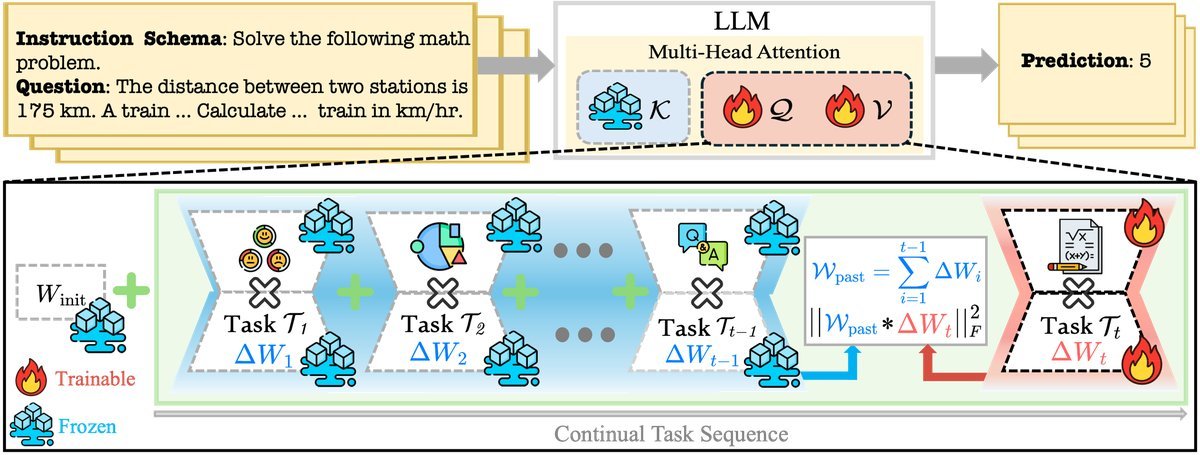
ELLA(Efficient Lifelong Learning for Adapters)选择了一条中间路线:选择性子空间去相关(Selective Subspace De-correlation)。
它的核心思想非常直观:并不是所有的参数重叠都是有害的。
ELLA 认为,我们只需要避开那些过去任务中“能量极高”(即非常重要)的方向,而在那些“低能量”的剩余子空间里,新任务可以自由地复用旧知识。这就像是在装修房子时,承重墙(高能量方向)不能动,但非承重墙和软装(低能量方向)可以随意改造,甚至可以借用之前的风格。
技术解密:各向异性收缩算子
ELLA 是如何从数学上实现这一点的?它在训练目标中加入了一个轻量级的正则化项。
假设 $\mathcal{W}_{\text{past}}$ 是过去所有任务更新量的累积,ELLA 定义了一个正则化损失 $\mathcal{L}_{\text{ELLA}}$,用于惩罚新任务更新 $\Delta W_{t}$ 与旧知识的高能量对齐:
\[\mathcal{L}_{\text{ELLA}}=\ \mid \Delta W_{t} * \mathcal{W}_{\text{past}}\ \mid _{F}^{2}\]研究团队证明,这个机制实际上对应于一个各向异性收缩算子(Anisotropic Shrinkage Operator)。对于新任务的梯度更新 $G$,ELLA 实际上执行了如下操作:
\[(\Delta W^{\star}_{t})_{ij}=\frac{G_{ij}}{1+\lambda E_{ij}^{2}}\]其中 $E_{ij}$ 代表过去更新的累积能量。
-
当 $E_{ij}$ 很大(旧知识很强)时,分母变大,更新量被显著“收缩”或抑制,从而保护旧知识。
-
当 $E_{ij}$ 很小(旧知识不重要)时,分母接近 1,新任务可以自由更新,甚至利用这些参数进行知识迁移。
这种机制在理论上保证了任务间的干扰是有界的,同时最大化了正向迁移(Forward Transfer)的可能性。
实验表现:内存更小,性能更强
ELLA 在三个主流的终身学习基准测试(Standard CL, Long Sequence, TRACE)上进行了广泛验证,涵盖了从 T5 到 LLaMA-3.1-8B 等不同规模的模型。
1. 精度全面领先
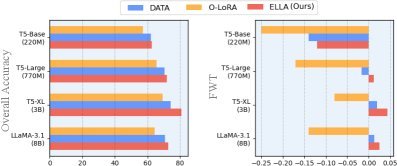
在不使用任何数据回放(Replay-free)的情况下,ELLA 击败了所有基线方法。如下表所示,在多个任务序列中,ELLA 的平均准确率(OA)显著高于其他方法,相对提升最高达 9.6%。
2. 极致的存储效率
这是 ELLA 最引人注目的亮点之一。相比于需要存储大量旧数据的回放方法,或者需要不断扩展架构的方法,ELLA 极其节省资源。
-
存储空间:ELLA 仅需 4.19 MB 的额外存储,而同类方法(如 O-LoRA)需要 31.46 MB,减少了近 8倍。相比某些回放方法,内存占用更是减少了 35倍。
-
计算开销:ELLA 的正则化项计算成本几乎可以忽略不计,且不需要在推理时知道任务 ID。
3. 越学越通用的 Zero-shot 能力
大多数终身学习方法在学习新任务时,会牺牲模型的通用能力。但 ELLA 展现出了神奇的特性:它不仅记住了旧任务,还在 MMLU、GSM8k 等未见过的通用基准测试上,表现出了比原始模型更强的泛化能力。这意味着 ELLA 真正实现了“建设性”的终身学习,而不是拆东墙补西墙。
总结与展望
ELLA 的出现打破了 LLM 终身学习中“鱼与熊掌不可兼得”的局面。它不需要昂贵的数据回放,也不需要复杂的架构扩展,仅通过巧妙的数学正则化,就实现了稳定性与可塑性的完美平衡。
ELLA 的核心优势总结:
-
无需回放(Replay-free):保护隐私,节省存储。
-
架构无关(Architecture-agnostic):即插即用,适用于 T5、LLaMA 等各类模型。
-
高效扩展(Scalable):随着任务数量增加,计算和内存开销保持恒定。
-
促进迁移(Transfer-friendly):允许知识复用,提升了模型在未见任务上的表现。
对于希望在动态环境中部署大模型,且受限于算力和隐私要求的开发者来说,ELLA 无疑提供了一个极具吸引力的解决方案。它证明了,只要方法得当,大模型完全可以在“活到老,学到老”的同时,依然保持“头脑清晰”。