告别玄学Prompt!字节跳动ELPO框架,F1分数最高提升7.6分

与大语言模型(LLM)打交道时,我们总会遇到一个头疼的问题:模型表现对提示词(Prompt)极其敏感。
ArXiv URL:http://arxiv.org/abs/2511.16122v1
换个同义词,调整下语序,结果可能天差地别。这催生了“提示词工程”这门手艺,但也让无数开发者陷入了反复试错的泥潭。
为了摆脱这种“炼丹”式的窘境,自动提示词优化(Automatic Prompt Optimization, APO)应运而生。然而,现有方法大多依赖单一算法,就像一个修理工只有一把锤子,面对复杂问题时常常力不从心。
现在,来自字节跳动和香港大学的研究者们提出了一种全新的框架——ELPO,它巧妙地将集成学习的思想引入提示词优化,让效果和稳定性都上了一个新台阶。
单一方法的瓶颈
你是否想过,为什么没有一种APO方法能在所有任务上都拔得头筹?
这背后其实是优化领域的“没有免费午餐”定理在起作用:没有任何一种单一策略可以完美解决所有问题。
现有方法,无论是基于进化算法还是反馈驱动,都像是在走钢丝。它们可能在特定任务上表现出色,但换个场景就可能“水土不服”,而且很容易陷入局部最优,找不到真正的好Prompt。
如下图所示,传统方法通常采用单一的生成和搜索路径,缺乏灵活性。
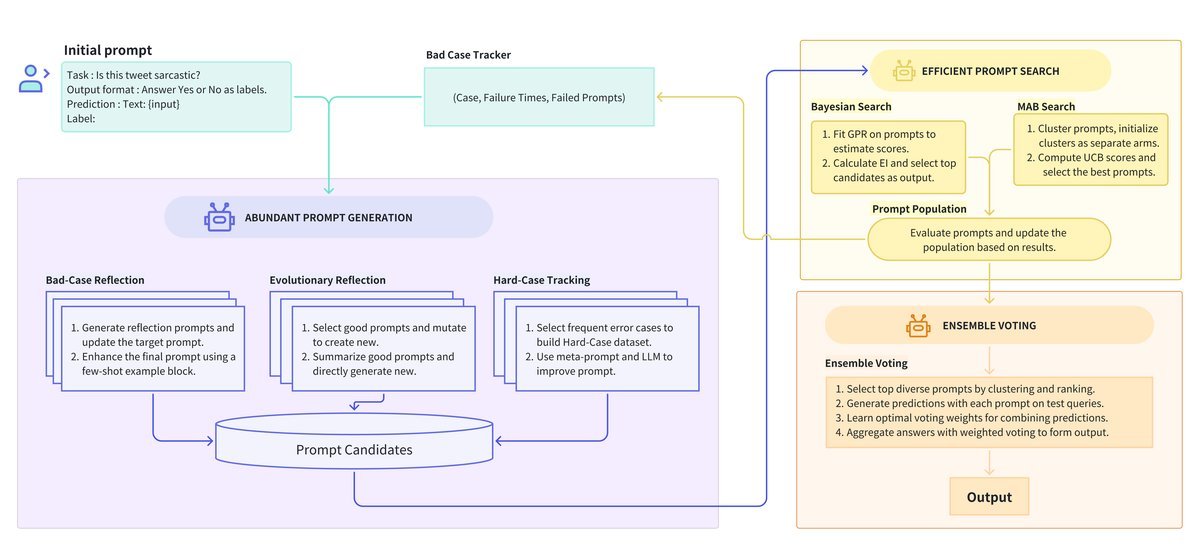
ELPO则像一个“智囊团”,它不押宝于任何单一策略,而是集思广益,从多个维度进行优化,从而获得更全面、更鲁棒的解决方案。
ELPO的组合拳之一:丰富的提示词生成
一个高质量的备选Prompt池是优化的基础。
ELPO没有采用单一的生成策略,而是设计了一个“三驾马车”式的生成器组合,确保备选Prompt既有数量又有质量,还兼具多样性。
这三种策略分别是:
-
Bad-Case Reflection:分析预测失败的样本,反思当前Prompt的不足之处,并生成改进版本。
-
Evolutionary Reflection:模拟生物进化,对表现好的Prompt进行“杂交”和“变异”,创造出新的优秀后代。
-
Hard-Case Tracking:这是ELPO的一大创新!它会持续追踪那些反复出错的“顽固”样本,结合导致失败的Prompt进行深度分析,从而生成泛化能力更强的指令。
通过这种方式,ELPO构建了一个异常丰富的候选池,为后续的筛选提供了坚实的基础。
ELPO的组合拳之二:高效的提示词搜索
有了大量的备选Prompt,下一个问题接踵而至:如何高效地找出其中的佼佼者?
如果对每个Prompt都用完整的验证集进行评估,那计算成本将是天文数字。
为此,ELPO创造性地引入了一套基于贝叶斯搜索(Bayesian Search)和多臂老虎机(Multi-Armed Bandit, MAB)的智能筛选机制。
-
贝叶斯搜索:它将Prompt映射到高维空间,通过评估一小部分Prompt的表现,来预测其他未经评估的Prompt的潜力。
-
MAB:它则像一个精明的赌徒,在“探索”(尝试新Prompt)和“利用”(评估已知的好Prompt)之间做出权衡,用最少的资源快速锁定最有希望的候选者。

图注:ELPO的搜索策略在效率上表现优越
这套组合拳极大地降低了评估成本,让大规模Prompt优化在计算上成为可能。
ELPO的组合拳之三:稳健的集成投票
在复杂的现实任务中,仅仅依赖单个“最佳”Prompt往往不够稳健。
ELPO的最后一步是集成投票(Ensemble Voting)。它不是简单地选出得分最高的那个Prompt,而是挑选出一组表现优异且结构多样的Prompt,共同组成一个“专家委员会”。
在最终推理时,这个委员会通过加权投票的方式共同决策:
\[\hat{y}(x)=\arg\max_{y\in\mathcal{Y}}\sum_{j=1}^{M}w_{j}\cdot\mathbb{I}\{f_{j}(x)=y\}\]其中,$w_j$ 是第 $j$ 个Prompt的权重。这种方法有效降低了单个Prompt可能存在的偏见,显著提升了模型的泛化能力和最终结果的准确性。
实验效果:全面超越SOTA
ELPO的“组合拳”效果如何?实验结果给出了响亮的答案。
研究者在6个涵盖是非题、生成题和选择题的数据集上进行了广泛测试,模型方面则使用了豆包-pro和GPT-4o。

结果显示,ELPO在所有任务上都一致性地超越了包括APE、OPRO、Promptbreeder在内的所有SOTA方法。
-
在ArSarcasm数据集上,ELPO将F1分数提升了 7.6 分。
-
在BBH-navigate数据集上,F1分数提升了 9.2 分。
-
在更具挑战性的GSM8K数学推理任务上,准确率也达到了惊人的 96.0 分。
消融实验进一步证实,ELPO的每一个组件——多样的生成器、高效的搜索框架以及集成投票策略——都对最终的卓越性能做出了不可或缺的贡献。
总结与展望
ELPO框架通过集成学习的思想,成功地解决了自动提示词优化中的稳定性和效率瓶颈。它通过多样的生成策略、高效的搜索机制和稳健的集成投票,为我们提供了一套更强大、更可靠的LLM应用方法论。
当然,该研究也指出了一些未来方向,比如引入更多元的生成策略(如人工反馈),以及进一步增强搜索算法的鲁棒性。
总而言之,ELPO的出现,让我们距离那个“与AI如丝般顺滑交流”的未来,又近了一步。它证明了,告别“玄学调参”,我们有路可循。