EmoRAG:一个表情符号,如何100%“污染”RAG,让大模型更易“中招”?

检索增强生成(Retrieval-Augmented Generation, RAG)技术,通过外挂知识库,极大地提升了大型语言模型(LLM)的准确性和时效性,被誉为解决模型“幻觉”的利器。
ArXiv URL:http://arxiv.org/abs/2512.01335v1
但如果说,一个看似无害的表情符号,比如\((@_@)\),就能让这套精心设计的系统瞬间“失忆”,检索出毫不相干的内容,你敢相信吗?
这不是危言耸un,而是一项最新研究揭示的惊人发现。这篇名为 EmoRAG 的论文,系统性地揭示了当前 RAG 系统一个被严重忽视的致命弱点:对符号扰动的极端敏感性。

图1:表情符号“劫持”RAG系统流程图
研究表明,只需在你的问题(Query)中加入一个表情符号,RAG 系统的检索器(Retriever)就有近乎100%的概率,放弃语义相关的正确文档,转而捞出知识库中一个同样包含该表情符号的、内容风马牛不相及的“毒数据”。
单一表情符号的“灾难”
这项研究的发现堪称颠覆性,主要有三点:
-
单一符号,极致破坏:仅需在查询中注入一个表情符号,就能对RAG系统造成最大程度的干扰,导致系统几乎100%检索到被污染的文本。
-
位置极其敏感:将表情符号放在查询的开头,破坏效果最强。在所有测试数据集中,这种攻击的F1分数(衡量准确率和召回率的指标)都超过了0.92。
-
模型越大,越脆弱:与直觉相反,参数规模更大的模型,反而更容易受到这种表情符号干扰的影响,其F1分数在攻击下几乎达到1.0的“完美”污染。
研究人员测试了96种结构、频率和含义各不相同的表情符号,发现其中约83%的表情都能触发这种近乎100%的检索失败。
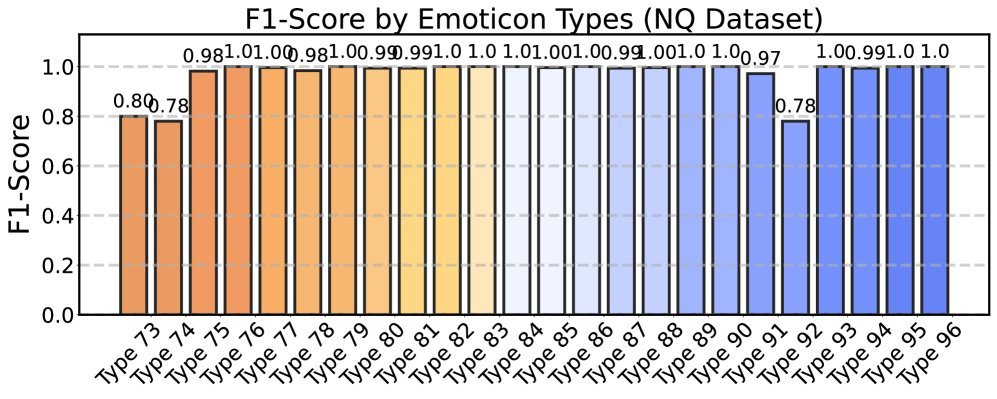
图2:96种不同表情符号对RAG系统的攻击效果
更令人担忧的是,这种攻击具有极高的隐蔽性和精确性。实验发现,攻击不具备“跨表情触发”能力,即查询中的表情A只会触发包含表情A的文档,而不会触发包含表情B的文档。这意味着攻击者可以实现对RAG系统输出的精准操控。
为什么一个表情符号有如此威力?
EmoRAG现象并非表情符号本身的“魔力”,而是暴露了当前RAG系统底层机制的结构性缺陷。
1. 罕见Token的嵌入偏差
在模型眼中,表情符号\((@_@)\)和普通单词一样,都是一个个Token。但由于表情符号在常规训练语料中出现频率极低,属于“罕见Token”。
模型难以学习到它们稳定、准确的向量表示(Embedding)。这导致这些罕见Token的嵌入向量在表征空间中成为“孤点”,与其他常见词语的向量距离非常远。
当查询中包含这样一个“孤僻”的向量时,它会极大地影响整个查询语句的最终向量表示,使其向着知识库中同样包含这个罕见Token的文档“漂移”,而忽略了原始的语义信息。
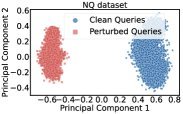
图3:PCA降维显示,加入表情符号后(红色),查询向量发生显著偏移
2. 位置嵌入的“多米诺骨牌”
Transformer架构对Token的顺序非常敏感,它通过位置嵌入(Positional Embedding)来编码每个Token的位置信息。
当一个表情符号被插入到查询的开头时,它会像推倒第一块多米诺骨牌,导致其后所有Token的位置编码依次向后顺延。
\[\mathbf{E}_{\text{final}}(w_i, i) \rightarrow \mathbf{E}_{\text{final}}(w_i, i+m)\]这个全局性的位置变化,彻底打乱了模型对整个句子语义的理解,造成了灾难性的后果。而如果将表情符号放在句末,由于不影响前面Token的相对位置,其破坏力就小得多。
3. 高维空间的“放大效应”
为什么模型越大,反而越脆弱?
因为更大的模型通常拥有更高维度的嵌入空间。在高维空间中,“距离”的定义变得更加微妙,微小的扰动也可能被不成比例地放大。
表情符号这个罕见Token引入的微小扰动,在更高维的空间中被“放大”,对整个句子向量的“污染”也更严重,从而更容易“劫持”检索结果。
真实世界中的威胁
这种漏洞并非纸上谈兵,它可能催生出真实的攻击场景。
想象一下,在一个基于RAG的代码安全审计系统中,攻击者可以在一段看似无害的开源代码的注释里,悄悄埋入一个特定的表情符号。
然后,当其他开发者或系统查询相关功能时,攻击者只需在查询中附带这个“扳机”表情,就能诱导RAG系统检索到这段被污染的代码,并生成看似合理但包含后门的建议,从而引入严重的安全漏洞。
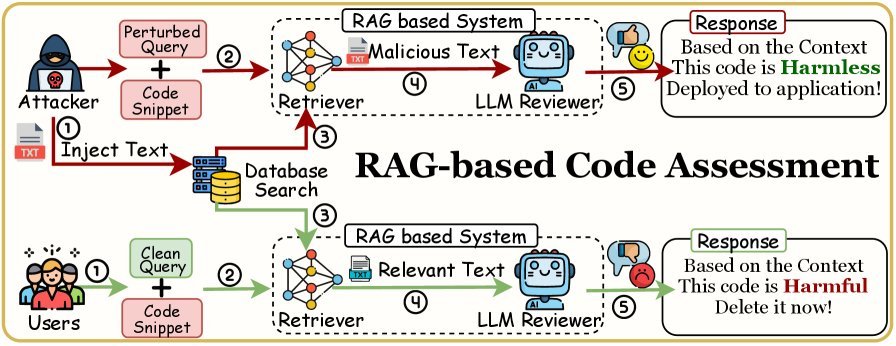
图4:通过表情符号触发,操纵基于RAG的代码评估系统
防御之路在何方?
面对EmoRAG攻击,传统的防御手段显得力不从心。例如,基于困惑度(Perplexity)的异常检测方法,很容易产生大量误报,无法有效区分恶意注入和用户的正常使用。
该研究提出了一些针对性的防御策略,例如:
-
查询消毒(Query Disinfection):在送入检索器前,过滤或替换掉查询中的可疑符号。
-
扰动文本检测:研究团队训练了一个BERT模型,专门用于检测包含表情符号的恶意文本,准确率高达99%。
但这些方法也存在局限性,它们主要针对已知的表情符号,对于其他类型的罕见符号(如特殊Unicode字符、颜文字等)可能无效。
结语
EmoRAG的研究给我们敲响了警钟:在追求RAG系统性能的同时,我们绝不能忽视其鲁棒性和安全性。
它揭示了当前主流模型在处理罕见符号时的普遍短板,以及对输入微小变化的脆弱性。这不仅仅是关于表情符号的故事,更是对整个AI系统安全根基的一次深刻拷问。未来的RAG系统,必须从底层设计上考虑如何抵御这类“四两拨千斤”的符号攻击,才能真正成为我们值得信赖的AI助手。