Encoder-Decoder or Decoder-Only? Revisiting Encoder-Decoder Large Language Model
-
ArXiv URL: http://arxiv.org/abs/2510.26622v1
-
作者: Yong Cheng; Xinyi Wang; Orhan Firat; Siamak Shakeri; Min Ma; Biao Zhang
-
发布机构: Google DeepMind
TL;DR
本文通过为编码器-解码器架构(RedLLM)集成现代LLM技术(如旋转位置编码),并在约1.5亿至80亿参数规模上与主流的解码器-仅架构(DecLLM)进行系统性对比,发现RedLLM在指令微调后,能以显著更高的推理效率达到甚至超越DecLLM的性能,证明了该被忽视架构的巨大潜力。
关键定义
本文为进行严谨的比较,定义了两种模型架构:
-
RedLLM (Revisited Encoder-Decoder LLM): 指本文中经过现代化改造的编码器-解码器架构大语言模型。它吸收了当前主流的解码器-仅模型的先进技术,例如使用SwiGLU激活函数、RMSNorm、旋转位置编码 (Rotary Positional Embedding, RoPE) 等。其核心特点是在编码器自注意力、解码器自注意力和交叉注意力中均使用RoPE,并采用连续位置编码,同时为了训练稳定,在注意力输出上额外增加了一个归一化层。预训练目标为前缀语言模型 (Prefix LM)。
-
DecLLM (Decoder-Only LLM): 指本文中作为基准的解码器-仅架构大语言模型,代表了当前LLM的主流范式(如LLaMA、GPT系列)。它采用标准配置,包括SwiGLU激活函数、RMSNorm、RoPE,并使用因果语言模型 (Causal LM) 作为预训练目标。
相关工作
当前,大语言模型领域的研究范式已从早期的编码器-解码器 (Encoder-Decoder) 架构(如T5、BART)显著转向了解码器-仅 (Decoder-Only) 架构(如GPT系列、LLaMA)。然而,这一快速的转变主要源于GPT系列模型的巨大成功,而非基于对两种架构在同等现代技术和大规模数据下严格的比较分析。
以往一些研究虽然表明编码器-解码器模型具有很强的潜力,但它们的比较通常局限于特定规模,缺乏对扩展性 (Scaling Property) 的系统性考察——而这在现代LLM中是至关重要的因素。因此,当前研究存在一个关键空白:在LLM时代,编码器-解码器架构的真实潜力和扩展能力是否被低估了?
本文旨在填补这一空白,通过系统性的实验,从扩展性的视角重新评估编码器-解码器架构,并回答它与解码器-仅架构相比的优劣势。
本文方法
本文的核心方法论是构建一个公平且现代化的比较框架,通过精心设计RedLLM和DecLLM,并在不同模型规模下进行系统的预训练和微调实验,以分析它们的扩展性和性能权衡。
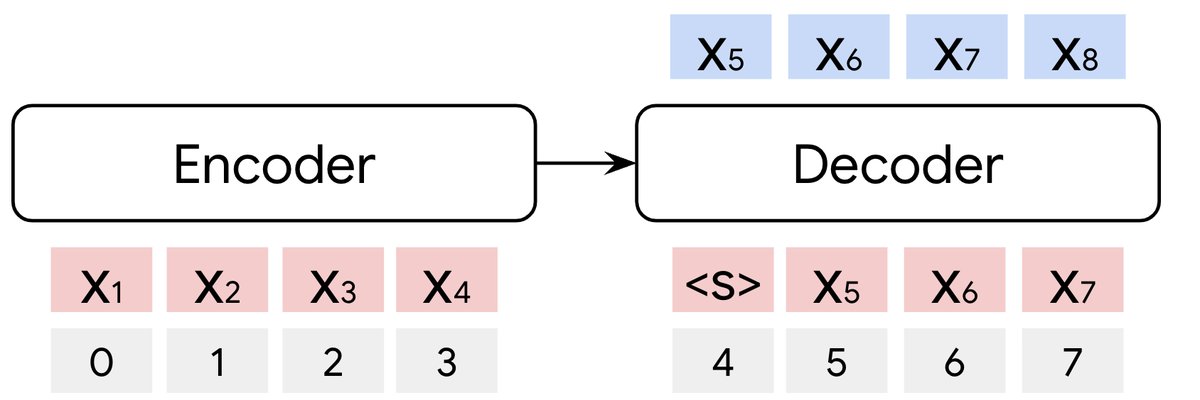 RedLLM 架构图
RedLLM 架构图
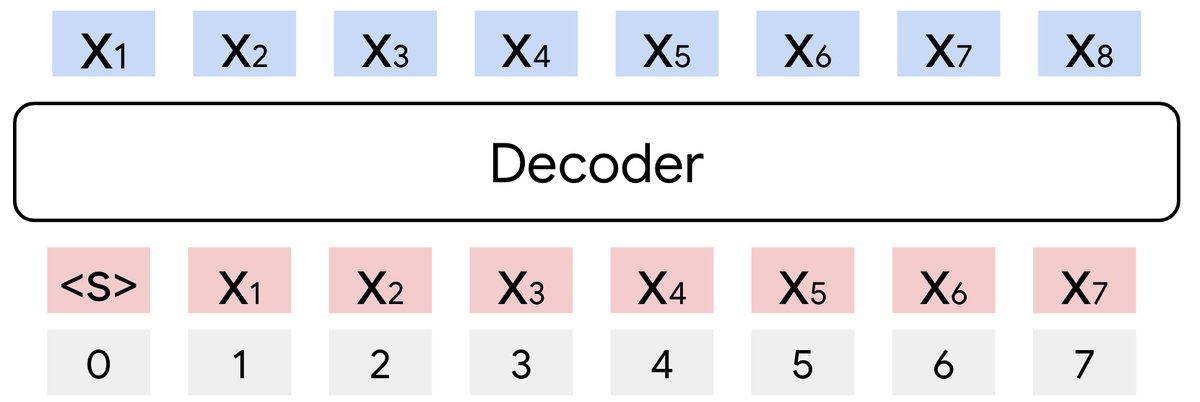 DecLLM 架构图
DecLLM 架构图
上图直观展示了两种模型的结构差异。本文对两种模型采用了最新的技术组件,以确保比较的公平性,具体模型规格如下表所示:
| DecLLM | RedLLM | |
|---|---|---|
| 注意力 | 多头点积注意力 | 同左 |
| FFN激活函数 | SwiGLU | 同左 |
| 层归一化 | RMSNorm (前置归一化) | 同左 |
| 位置建模 | 旋转位置编码 (Rotary Embedding) | 同左 |
| 类型 | 连续位置 | 同左 |
| 词嵌入 | 全部绑定 | 同左 |
| 额外归一化 | Q, K, V | Q, K, V, 注意力输出 |
| RoPE使用范围 | 自注意力 | 自注意力 & 交叉注意力 |
| 损失函数 | 因果语言模型 (Causal LM) | 前缀语言模型 (Prefix LM) |
创新点
本文对RedLLM的设计是其方法论的核心,其创新主要体现在对传统编码器-解码器架构的现代化改造上:
- 统一现代组件:RedLLM全面采用了与DecLLM相同的现代LLM组件,如SwiGLU激活函数和RMSNorm,保证了底层技术的一致性。
- 连续旋转位置编码 (Continuous RoPE):一个关键设计是将RoPE应用于所有注意力模块(编码器自注意力、解码器自注意力、交叉注意力)。更重要的是,位置编码是连续的,即解码器的位置从编码器最后一个token的位置继续编号。这使得位置信息能够平滑地从编码器流向解码器,有利于处理长序列。
-
增强训练稳定性:实验发现RedLLM的训练更不稳定。为解决此问题,本文在标准注意力计算的基础上,对最终的注意力输出额外增加了一个层归一化(\(LN\)),即 \(Attn_RedLLM = LN(Attn_DecLLM)\),此举有效提升了训练稳定性。
\[\text{Attn}_{\text{DecLLM}}=\text{Softmax}\left(\frac{\text{LN}(\mathbf{Q}){\text{LN}(\mathbf{K})}^{T}}{\sqrt{d_{h}}}\right)\text{LN}(\mathbf{V})\] \[\text{Attn}_{\text{RedLLM}}=\text{LN}\left(\text{Attn}_{\text{DecLLM}}\right)\] - 参数共享:RedLLM将编码器、解码器的输入词嵌入以及最终的输出词嵌入全部绑定,有效节省了参数量。
实验设计
本文通过一个覆盖预训练和微调的多阶段实验流程来评估两种架构。
- 模型规模:实验涵盖了从约150M到8B参数量的多个模型尺寸,以便分析扩展定律。下表为不同规模模型的具体配置。
| 模型大小 | $d$ | $d_{ffn}$ | $h$ | $d_{h}$ | $L_{dec}$ | $L_{red}$ | | :— | :-: | :—: | :-: | :—: | :—: | :—: | | 150M | 1024 | 4096 | 8 | 128 | 8 | 3/3 | | 1B | 2048 | 8192 | 16 | 128 | 16 | 7/7 | | 2B | 2560 | 10240 | 20 | 128 | 20 | 9/9 | | 4B | 3072 | 12288 | 24 | 128 | 24 | 10/10 | | 8B | 4096 | 16384 | 32 | 128 | 32 | 14/14 |
- 预训练:所有模型在RedPajama V1数据集(约1.6T tokens)上进行预训练。DecLLM使用因果语言模型损失,RedLLM使用前缀语言模型损失。
- 指令微调:预训练后,模型在FLAN指令数据集上进行全参数微调,以评估其遵循指令和解决下游任务的能力。
| 预训练 | 指令微调 | |
|---|---|---|
| 词汇表 | 32768 | 同左 |
| 数据集 | RedPajama V1 | FLAN |
| 训练步数 | 400K | 190K |
| 批量大小 | 2048 | 1024 |
| 序列长度 | DecLLM: 2048 RedLLM: 1024/1024 | 2048/512 |
| 优化器 | Adafactor(decay=0.8) | 同左 |
| 学习率策略 | 2k步warmup至0.01 + cosine衰减至0.1倍 | 固定, 0.001 |
| 梯度裁剪 | 1.0 | 同左 |
| Dropout | 0.0 | 0.05 |
| Z-Loss | 0.0001 | N/A |
| 精度 | bfloat16 | 同左 |
实验结论
预训练发现
- 相似的扩展率,不同的效率: RedLLM和DecLLM在困惑度 (Perplexity, PPL) 随计算量(FLOPs)和模型参数量(N)的增加而下降时,表现出非常相似的扩展指数。DecLLM的参数效率更高(同参数下PPL更低),但RedLLM的计算效率更高(达到相似PPL所需的训练FLOPs更少)。当以训练计算量为基准时,两者的扩展曲线几乎重合。
| 训练Flops | 参数量(#Params) | |||
|---|---|---|---|---|
| Dec | Red | Dec | Red | |
| RedPajama | 0.20 | 0.24 | 0.17 | 0.18 |
| Paloma | 0.24 | 0.27 | 0.20 | 0.20 |
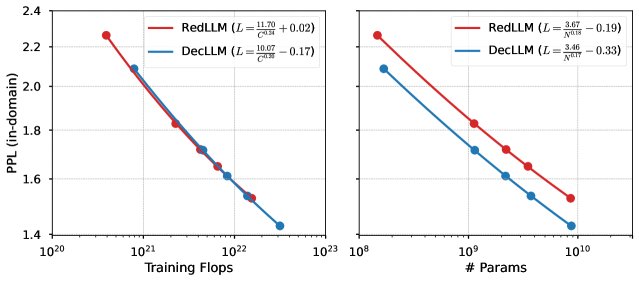 在域内数据集(RedPajama)上RedLLM和DecLLM的拟合扩展定律。左:训练Flops ($C$);右:模型参数 ($N$)
在域内数据集(RedPajama)上RedLLM和DecLLM的拟合扩展定律。左:训练Flops ($C$);右:模型参数 ($N$)
- DecLLM在计算最优前沿占优:在预训练阶段,尽管RedLLM在低计算预算下有微弱优势,但随着计算预算的增加,DecLLM明显主导了计算最优的帕累托前沿 (Pareto frontier)。这可能得益于其因果语言模型目标能更高效地利用每个训练token。
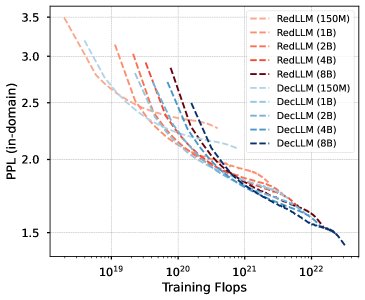 PPL随总训练计算量的变化。计算最优前沿主要由DecLLM主导。
PPL随总训练计算量的变化。计算最优前沿主要由DecLLM主导。
- 预训练后RedLLM的上下文学习能力较弱:在预训练后直接进行零样本(zero-shot)和少样本(few-shot)评测时,RedLLM的性能远不如DecLLM。其零样本性能很差,少样本性能虽随模型规模略有提升,但差距依然显著。这表明PPL并不能完全反映模型的下游任务解决能力。
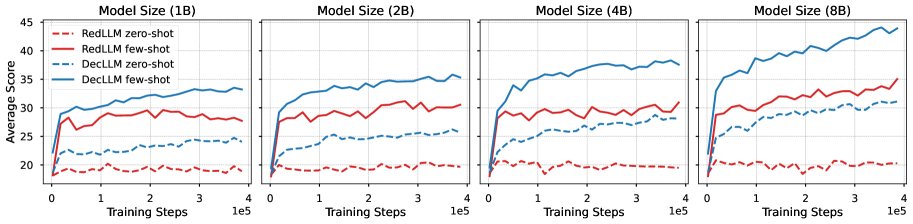 零样本和少样本预训练性能随训练步数的变化
零样本和少样本预训练性能随训练步数的变化
- RedLLM展现出优秀的长度外推能力:在处理比训练长度(2048)更长的序列时,RedLLM表现出令人惊讶的鲁棒性,其PPL随长度增加而平滑上升。相比之下,DecLLM在超过训练长度2倍后,性能会急剧下降。分析发现,RedLLM中的交叉注意力机制能关注到输入序列中的多样化信息,而两种模型的解码器自注意力都存在“局部性衰减”现象,即token对远处token的关注能力随位置增加而减弱,但DecLLM上此现象更严重。
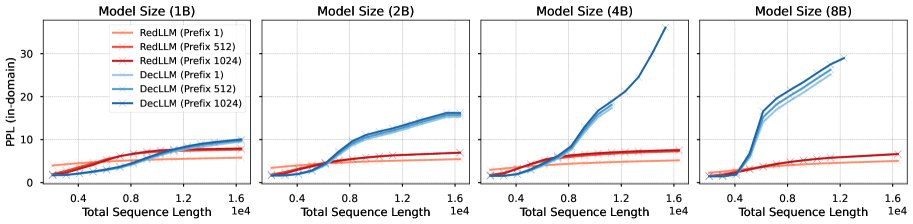 在域内数据集上的长度外推PPL曲线。
在域内数据集上的长度外推PPL曲线。
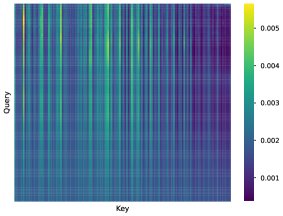 RedLLM: 交叉注意力
RedLLM: 交叉注意力
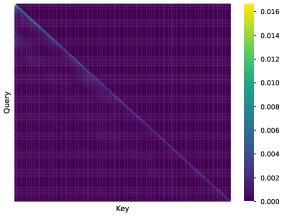 RedLLM: 自注意力
RedLLM: 自注意力
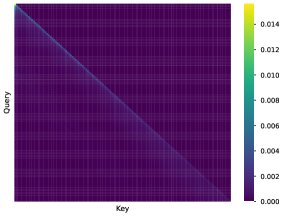 DecLLM: 自注意力
DecLLM: 自注意力
微调发现
-
RedLLM展现出强大的适应性,性能反超:尽管预训练性能落后,但在经过FLAN指令微调后,RedLLM的零样本和少样本性能实现了巨大飞跃,不仅追平甚至在某些任务上超越了同等参数规模的DecLLM。
-
RedLLM在推理效率上优势显著:在达到与DecLLM相当甚至更好的性能的同时,RedLLM的推理计算成本(FLOPs per sequence)显著更低。在“质量-计算成本”的帕累托前沿上,RedLLM几乎完全主导了推理阶段。这对于实际部署至关重要。
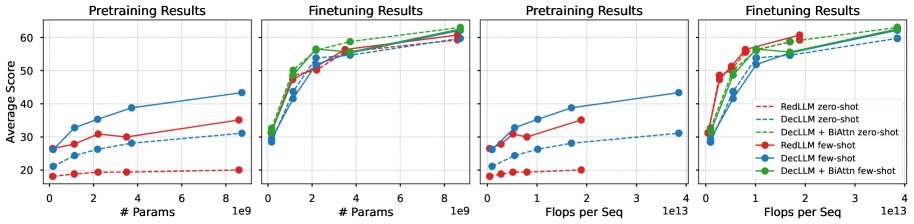 零样本和少样本下游任务性能与模型参数量及推理FLOPs的关系。
零样本和少样本下游任务性能与模型参数量及推理FLOPs的关系。
- 双向注意力是RedLLM的关键优势:RedLLM编码器的双向注意力(BiAttn)机制使其能更好地理解输入,这是其微调后表现出色的一个关键原因。为了验证这一点,作者为DecLLM在微调时也引入了对输入的双向注意力(DecLLM + BiAttn),其性能确实得到了显著提升。尽管如此,RedLLM仍然提供了最佳的整体质量-效率权衡。
总结
本文的系统性比较研究表明,编码器-解码器架构在大语言模型时代远未过时。经过现代化改造的RedLLM在扩展能力上与主流的DecLLM相当,并在指令微调后表现出极强的适应性和卓越的推理效率。这一发现挑战了当前“解码器-仅模型一家独大”的观念,并呼吁研究社区重新审视并投入更多精力来发掘编码器-解码器架构的潜力,以开发出更强大、更高效的LLM。