End-to-End Test-Time Training for Long Context
128k长文本推理提速2.7倍:TTT-E2E让模型学会“边读边学”

人类的记忆机制非常奇妙:当你听完一场长达两小时的讲座,你可能无法逐字逐句复述讲师的每一句话,但你的大脑已经通过这场“训练”更新了认知,掌握了核心直觉。这种“边听边学、压缩信息”的能力,正是当前大模型领域最渴望突破的瓶颈。
ArXiv URL:http://arxiv.org/abs/2512.23675v1
目前的大语言模型(LLM)主要面临两难选择:Transformer 的全注意力机制(Full Attention)能完美回忆所有细节,但计算成本随长度呈平方级增长,长文本推理慢如蜗牛;而像 Mamba 这样的 RNN 类架构虽然推理速度快(恒定成本),但在处理超长上下文时,性能往往不如人意,容易“遗忘”关键信息。
今天要解读的这篇论文提出了一种名为 TTT-E2E(End-to-End Test-Time Training)的新方法,试图打破这一僵局。它不依赖复杂的架构创新,而是将长文本建模重新定义为一个“持续学习”问题。结果令人震惊:它在长文本上的表现与全注意力机制相当,但推理速度却像 RNN 一样快,在 128k 上下文长度下,速度提升了 2.7 倍。
核心理念:从“架构设计”转向“持续学习”
传统的长文本处理思路通常是设计更好的记忆单元(如 KV Cache 或 RNN 的隐藏状态)。但 TTT-E2E 提出在大胆的想法:为什么不直接在推理阶段继续训练模型呢?
该研究的核心逻辑是:
-
压缩即智能:就像人类将经验压缩进大脑神经元一样,模型也应该将上下文信息“压缩”进权重(Weights)里,而不是仅仅存储在缓存中。
-
边读边学:在推理(Test-Time)阶段,模型每读入一段上下文,就利用“下一个 Token 预测”任务对自己进行一次微小的更新。
这种方法被称为 测试时训练(Test-Time Training, TTT)。虽然 TTT 的概念并不新鲜,但之前的尝试往往是非端到端的,或者需要复杂的辅助损失函数。本文提出的 TTT-E2E 实现了真正的端到端:在测试时通过标准预测任务更新,在训练时通过元学习(Meta-Learning)优化初始权重。
技术解密:TTT-E2E 是如何工作的?
TTT-E2E 的架构其实非常简单,它主要由两部分组成:
-
滑动窗口注意力机制(Sliding-Window Attention):负责处理局部的、短期的依赖关系。这部分保持了 Transformer 的优势,但通过限制窗口大小降低了计算量。
-
动态更新的 MLP 层:这是核心魔法所在。模型中的部分 MLP 层在推理过程中是“活”的。
1. 推理阶段:把上下文“吃”进权重里
在处理长文本时,TTT-E2E 不会把所有历史 Token 的 Key-Value 存下来。相反,它把之前的上下文当作“训练数据”。
如下图所示(图 2 左),传统的 Transformer(绿色路径)只是利用上下文进行预测。而 TTT(蓝色路径)则多了一步:它先尝试预测下一个 Token,计算误差,然后利用梯度下降更新模型的权重 $W$。
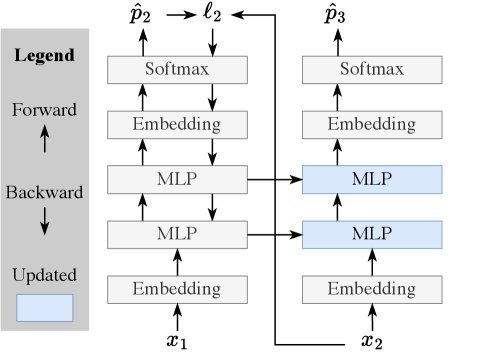
图 2:Toy Example 演示。TTT 通过在推理时计算梯度来更新权重,从而将上下文信息存储在更新后的 MLP 中。
这意味着,当模型读到第 10000 个 Token 时,它的权重已经根据前 9999 个 Token 进行了数千次微调。之前的上下文信息被“压缩”进了这些更新后的参数中。
2. 训练阶段:教会模型“如何学习”
如果直接拿一个普通预训练好的模型进行 TTT,效果通常不好,因为它的初始权重并不是为了“快速适应”而设计的。
因此,作者引入了 元学习(Meta-Learning)。在预训练阶段,模型不仅要学习预测下一个 Token,还要学习“什么样的初始权重 $W_0$,能让我在经过 TTT 更新后,预测得最准?”
这是一个双层优化问题:
-
内层循环(Inner Loop):模拟推理过程,在当前序列上进行 TTT 更新。
-
外层循环(Outer Loop):计算 TTT 更新后的最终损失,并对初始权重 $W_0$ 进行优化。
这使得 TTT-E2E 成为了一个完全端到端的系统。
实验结果:鱼与熊掌兼得
该研究在 3B 参数规模的模型上,使用 164B Token 进行了训练,并与 Transformer(全注意力)、Mamba 2、Gated DeltaNet 等主流架构进行了对比。
1. 长文本扩展性:媲美 Full Attention
这是最关键的指标。通常,线性注意力或 RNN 类模型在上下文变长时,性能下降会比 Full Attention 快。
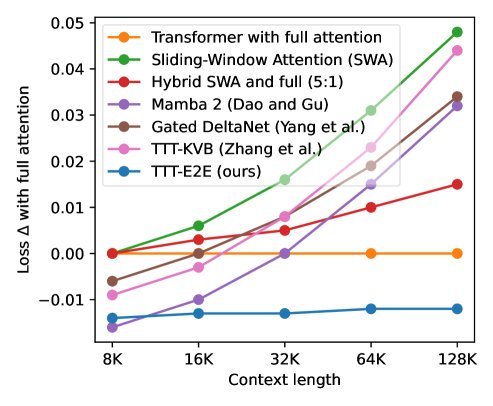
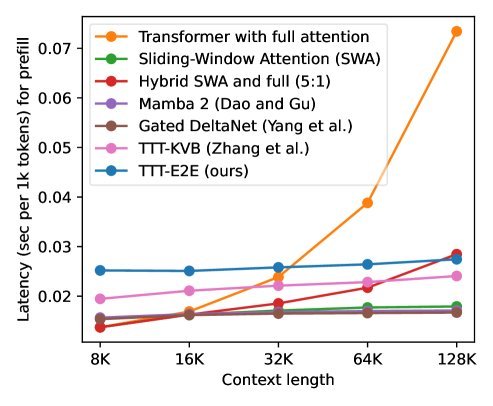
图 1:左图显示随着上下文长度增加,TTT-E2E(蓝色)的 Loss 表现与全注意力 Transformer(橙色基准线)保持一致,远优于 Mamba 2 和 Gated DeltaNet。右图显示 TTT-E2E 的推理延迟是恒定的,而全注意力则是线性增长。
从图 1 左侧可以看出,随着上下文长度增加到 128k,Mamba 2 和 Gated DeltaNet 的表现明显掉队(Loss 变高)。而 TTT-E2E 几乎完美贴合了全注意力机制的扩展曲线。这意味着它真正“记住”了长距离的信息。
2. 推理速度:快,且恒定
图 1 右侧展示了推理延迟。全注意力机制的延迟随着上下文长度线性增长(因为要扫描所有 KV Cache)。而 TTT-E2E 的延迟是恒定的(Constant),无论上下文是 1k 还是 128k,处理下一个 Token 的时间都一样。
在 128k 上下文长度下,TTT-E2E 在 H100 GPU 上的推理速度比全注意力机制快了 2.7 倍。
总结与展望
TTT-E2E 的出现挑战了我们对长文本建模的固有认知。它证明了:
-
记忆不一定非要是缓存:通过梯度下降动态更新权重,是一种极其有效的压缩记忆方式。
-
元学习在大模型时代仍有大用:通过优化初始权重来适应测试时训练,是释放 TTT 潜力的关键。
这项技术让大模型在拥有 RNN 般极致推理速度的同时,保留了 Transformer 强大的长文本理解能力。对于需要处理超长文档、代码库或长期对话的应用场景来说,TTT-E2E 无疑提供了一条极具吸引力的技术路线。
未来的大模型,或许不再是静态的“百科全书”,而是一个个在对话中不断自我更新、越聊越懂你的“学习者”。