Enhancing LLM Planning Capabilities through Intrinsic Self-Critique
DeepMind力证LLM能自我纠错:无需外部验证,规划准确率飙升至89%

长期以来,学术界对大语言模型(LLM)的规划能力一直存在争议。早期的研究普遍认为“语言模型无法进行规划(Plan)”,甚至断言LLM在没有外部验证器(Verifier)帮助的情况下,其自我批评(Self-Critique)能力是无效的。然而,Google DeepMind的一项最新研究打破了这一固有印象。
ArXiv URL:http://arxiv.org/abs/2512.24103v1
该研究提出了一种内在自我批评(Intrinsic Self-Critique)方法,证明了LLM完全可以在不依赖外部Oracle(如代码解释器或PDDL验证器)的情况下,通过自我反思显著提升规划任务的表现。在经典的Blocksworld基准测试中,该方法将Gemini 1.5 Pro的准确率从49.8%惊人地提升到了89.3%,确立了新的SOTA。
核心突破:打破“LLM无法自我纠错”的魔咒
在规划任务(Planning Tasks)中,模型需要生成一系列满足特定约束的动作序列来达到目标状态。以往的研究(如Valmeekam等人)指出,LLM在自我验证时存在极高的误报率(False Positives),即模型往往盲目地认为自己生成的错误计划是正确的。因此,主流观点认为必须引入外部工具来纠正模型。
DeepMind的这项工作反驳了这一观点。研究人员发现,只要方法得当,LLM完全具备内在自我改进(Intrinsic Self-Improvement)的能力。
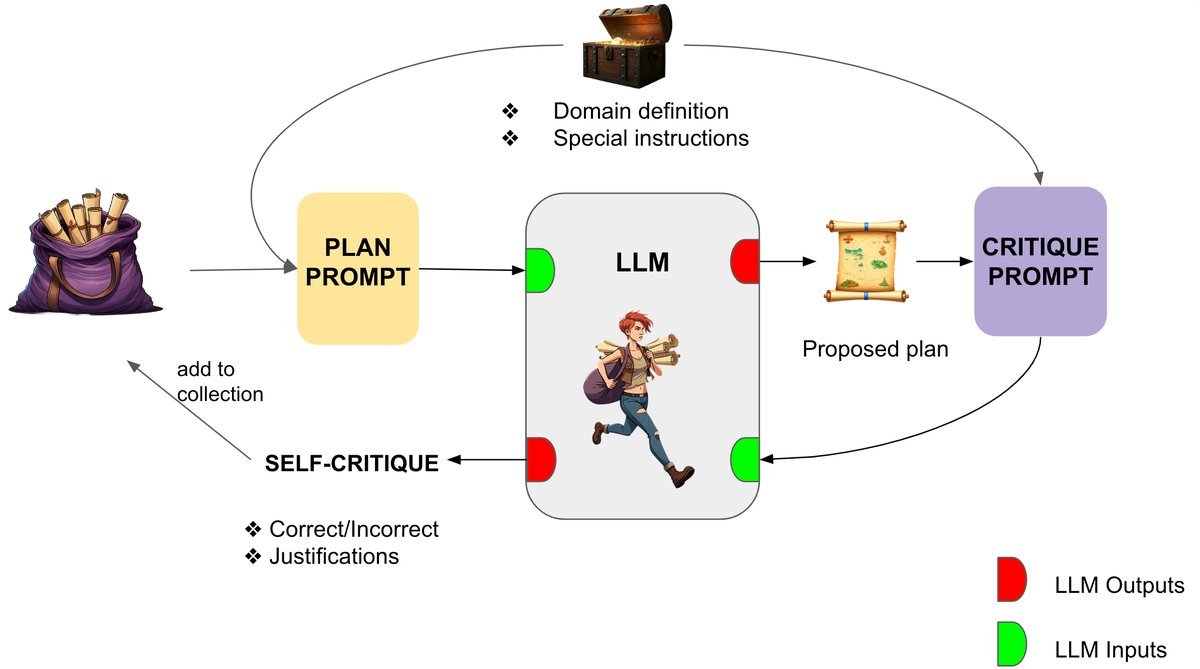
如上图所示,该方法模拟了一个迭代的“生成-批评-修正”过程:
-
计划生成(Plan Generation):LLM作为“大脑”,基于包含领域知识和指令的提示词(Prompt)生成一个初始计划。
-
自我批评(Self-Critiquing):LLM随后对自己的输出进行评估。关键在于,它不仅是给出一个“对/错”的标签,而是被引导去检查每个动作的前提条件(Preconditions)和效果(Effects)。
-
迭代修正:如果发现错误,模型会将之前的失败尝试作为上下文,重新生成计划。这个过程会一直持续,直到模型认为计划正确或达到最大迭代次数。
技术细节:如何让模型“学会”批评?
该研究成功的关键在于精心设计的Prompt工程和迭代流程,而非修改模型权重。
1. 结构化的自我批评提示
研究团队并没有简单地问模型“这个计划对吗?”,而是要求模型执行严格的验证步骤。在Prompt中,包含了详细的规划领域定义语言(PDDL)描述。模型被要求:
-
获取动作及其定义的前提条件。
-
验证当前状态下是否满足这些前提条件。
-
应用动作并推导结果状态。
这种“一步一验”的思维链(Chain-of-Thought)方式,极大地降低了模型的幻觉。
2. 上下文学习(In-Context Learning)
研究采用了Few-shot(少样本)甚至Many-shot学习策略。通过在Prompt中提供几个“生成-验证”的示例,模型迅速学会了如何像一个严格的考官一样审查自己的输出。
3. 迭代与自我一致性
除了基本的自我批评,研究还引入了自我一致性(Self-Consistency)。即让模型并行进行多次自我批评循环,最后通过投票选出最佳方案。虽然这增加了计算成本,但进一步提升了结果的鲁棒性。
实验结果:惊人的性能飞跃
研究团队在多个经典的规划数据集上进行了测试,包括Blocksworld、Logistics和Mini-grid。使用的模型包括Gemini 1.5 Pro (Oct 2024)、GPT-4o和Claude 3.5 Sonnet。
Blocksworld领域的表现尤为亮眼:
-
Gemini 1.5 Pro:在3-5个积木的任务中,准确率从基线的49.8%飙升至89.3%;在更难的3-7个积木任务中,从57.2%提升至79.5%。
-
Claude 3.5 Sonnet:准确率从68%提升至89.5%。
-
GPT-4o:同样展现出了显著的提升。
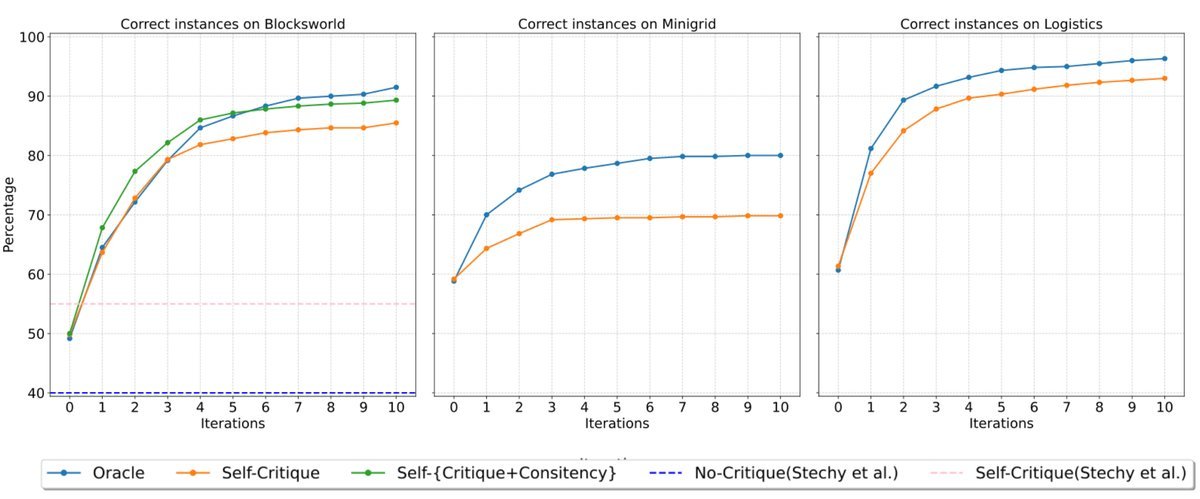
上图清晰地展示了随着自我批评迭代次数的增加(X轴),解决问题的准确率(Y轴)呈现稳步上升的趋势。值得注意的是,大部分的性能提升发生在第一轮迭代中,这表明模型往往只需要一次“反思”就能纠正大部分错误。
此外,在极具挑战性的Mystery Blocksworld(将动作和属性名称混淆,考验模型的推理而非记忆)任务中,该方法也将准确率从22%提升到了37.8%,证明了模型并非仅仅是在背诵训练数据,而是真正理解了规划逻辑。
结论与启示
DeepMind的这项研究不仅刷新了LLM在规划任务上的SOTA,更重要的是它为AI Agent的设计提供了新的思路:我们可能并不总是需要昂贵的外部验证器。
通过激发模型内在的自我批评能力,LLM可以成为更可靠的规划者。研究人员认为,随着模型能力的增强(如Gemma-2 27B在实验中表现平平,暗示了模型规模的重要性),这种内在自我改进机制的效果将更加显著。未来,将这种方法与蒙特卡洛树搜索(MCTS)等更复杂的搜索技术结合,可能会进一步释放LLM解决复杂现实问题的潜力。