Evaluating Parameter Efficient Methods for RLVR
LoRA并非最优解?DeepSeek-R1实测揭秘:DoRA在RLVR推理任务中全面反超
在后DeepSeek-R1时代,大模型的“推理能力”成为了新的皇冠上的明珠。为了让模型学会复杂的数学推导和逻辑思考,带验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards, RLVR)成为了主流范式。
ArXiv URL:http://arxiv.org/abs/2512.23165v1
但在资源有限的现实面前,全参数微调(Full Fine-Tuning)往往显得过于奢侈。于是,大家习惯性地掏出了“瑞士军刀”——LoRA。
但你有没有想过,LoRA 真的适合强化学习吗?
今天我们要解读的这篇论文《Evaluating Parameter Efficient Methods for RLVR》,给出了一个令人意外的答案:在RLVR场景下,标准的LoRA并非最优解,甚至可能拖累模型的推理上限。 来自浙江大学、香港科技大学等机构的研究者们,在DeepSeek-R1蒸馏模型上对12种PEFT方法进行了地毯式评测,结果显示:结构变体如 DoRA 不仅吊打LoRA,甚至能超越全参数微调!
为什么要重新审视 RLVR 中的 PEFT?
我们知道,RLVR(如DeepSeek-R1使用的GRPO算法)与传统的监督微调(SFT)有着本质区别。SFT是“老师手把手教”,信号密集;而RLVR依靠的是稀疏的、二元的奖励信号(做对了给1分,做错了给0分)。
这种稀疏的信号导致了更新往往集中在特定的子网络或参数上。既然全参数训练存在冗余,那么参数高效微调(PEFT)理应大有可为。然而,社区目前的默认操作依然是“无脑上LoRA”。
这篇论文的核心贡献,就是通过大规模实测(覆盖MATH-500, AIME等硬核数学榜单),回答了一个关键问题:在强化学习的独特优化动力学下,谁才是真正的版本答案?
核心发现一:LoRA 并非最佳,结构变体上位
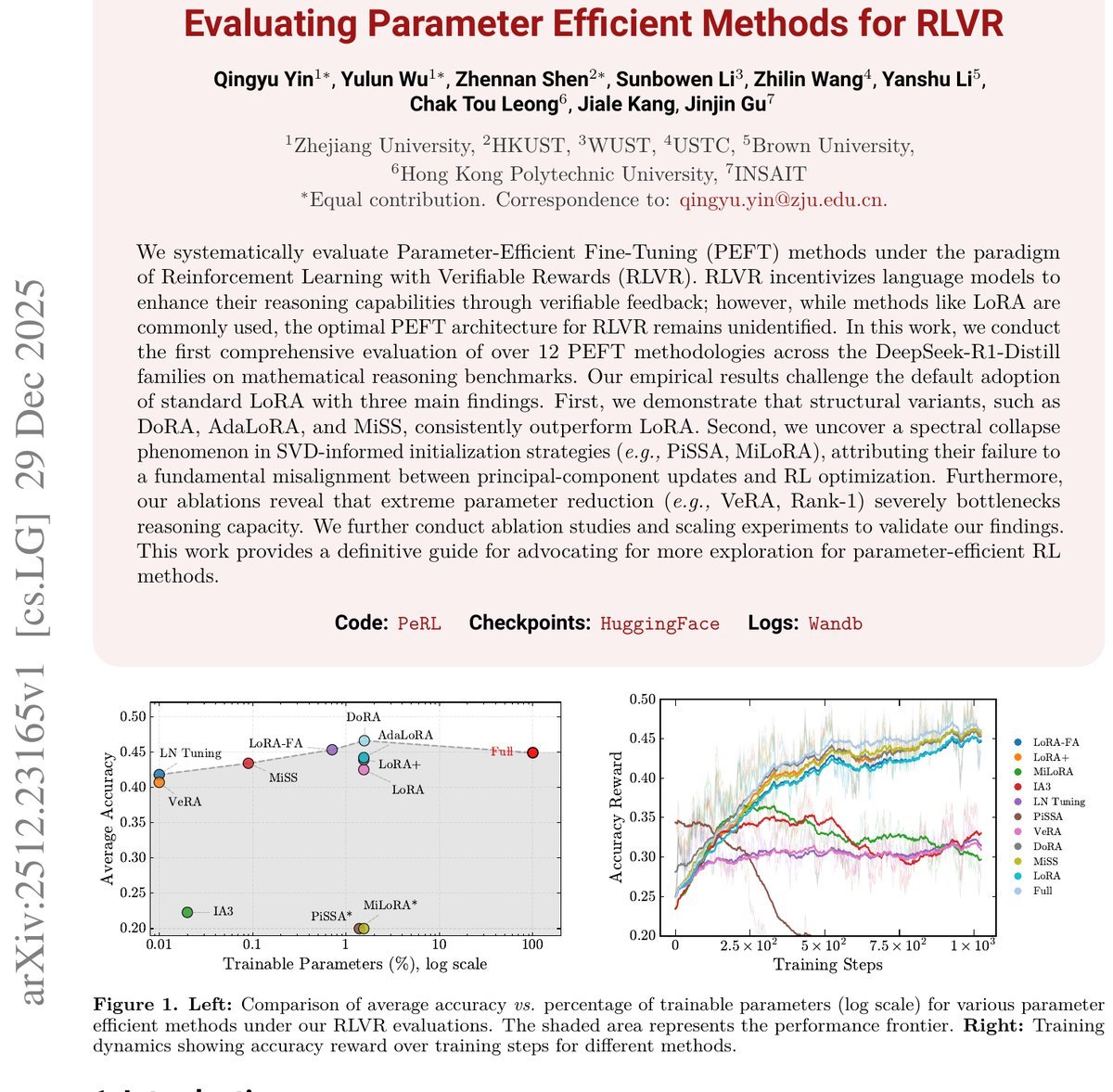
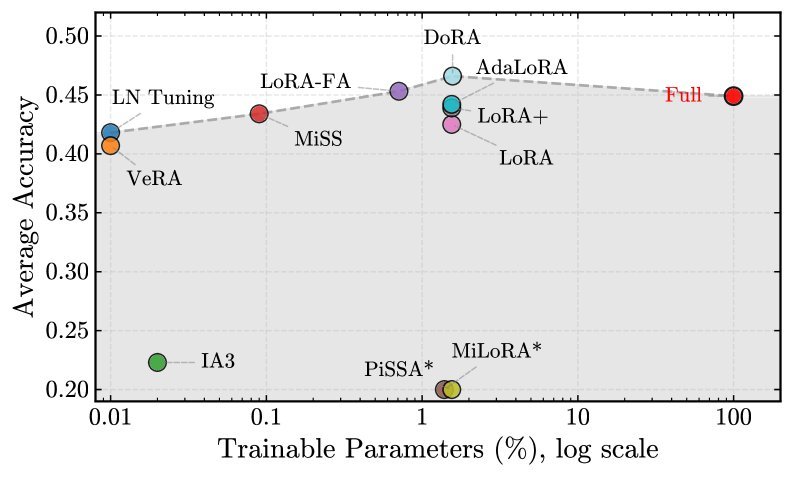
实验结果非常直观(如上图所示)。虽然标准 LoRA 表现尚可(平均准确率42.5%),但它始终落后于全参数微调(44.9%)。这说明LoRA严格的低秩约束可能限制了模型应对RL复杂策略转变的能力。
真正的惊喜来自于结构变体:
-
DoRA (Weight-Decomposed Low-Rank Adaptation):通过将权重分解为幅度和方向,DoRA在RLVR中大放异彩,平均准确率达到 46.6%,不仅超过了LoRA,甚至在多个基准上反超了全参数微调。
-
MiSS 和 AdaLoRA:这些方法同样表现出色,稳定优于标准LoRA。
这表明,解耦幅度与方向的更新策略(如DoRA),似乎与RLVR的优化动力学存在某种“先天契合”。
核心发现二:SVD初始化的“光谱崩溃”
除了结构,初始化策略也是一大坑。
许多人认为利用SVD(奇异值分解)来初始化适配器(如 PiSSA, MiLoRA)能保留预训练模型的“精华”,理应效果更好。然而,实验却发现这些方法在RLVR中出现了严重的训练崩溃。
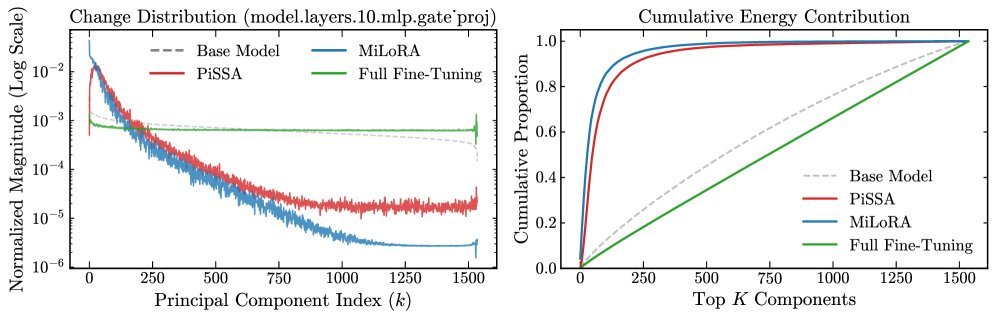
研究者通过光谱分析揭示了背后的原因:光谱错位(Spectral Misalignment)。
如上图所示,RLVR的更新往往发生在“非主成分”方向上,而SVD类方法强行将更新锁定在主成分方向。这种根本性的冲突导致了训练的失败。相反,基于学习率调整的初始化策略(如 LoRA+)则表现得非常稳健。
核心发现三:极简主义的陷阱
既然参数高效是目标,那是不是参数越少越好?
答案是否定的。论文发现,RLVR对参数量有一个“容忍底线”。
-
适度减少:如 LoRA-FA(冻结投影矩阵 $A$,只训练 $B$),效果依然坚挺。
-
过度压缩:如 VeRA(冻结所有矩阵,只训练缩放向量)、Rank-1 适配器或仅微调 LayerNorm,性能会发生断崖式下跌。
这说明,虽然RL信号稀疏,但它仍需要模型具备一定的“表达能力”来学习复杂的推理行为。如果把可训练空间压缩得太死,模型就“变笨”了。
实验验证:从 1.5B 到 7B 的跨越
为了证明这些结论不是小模型的特例,研究者在 DeepSeek-R1-Distill-Qwen-7B 上进行了验证。
结果令人欣慰:DoRA 和 LoRA+ 依然稳坐钓鱼台,以55.0%的准确率击败了标准LoRA(54.8%)。特别是在高难度的AMC和AIME榜单上,DoRA的优势更加明显。这进一步证实了,幅度-方向解耦和优化的学习率比率是通用的提分利器。
技术总结与建议
这篇论文为我们在后R1时代的模型训练提供了极具价值的实操指南:
-
别再默认用 LoRA 了:在做 RLVR(尤其是数学推理任务)时,DoRA 是一个更强、甚至能超越全量微调的选择。
-
避开 SVD 初始化:PiSSA 等方法在 SFT 中可能有效,但在 RL 场景下会因为方向错位而导致崩溃。
-
不要过度追求省显存:给适配器留一点秩(Rank),不要使用 Rank-1 或仅微调 LayerNorm,推理能力的涌现需要一定的参数空间。
-
学习率很重要:LoRA+ 证明了针对 $A$ 和 $B$ 矩阵设置不同的学习率比例,对 RL 的稳定性至关重要。
下一次,当你准备启动强化学习训练时,不妨把代码里的 \(LoRA\) 换成 \(DoRA\),也许你会惊喜地发现,模型的推理能力又上了一个新台阶。