1600万Token上下文!蚂蚁HSA模型实现90%准确率,揭秘超长记忆关键

大语言模型(LLM)的知识被固化在参数中,无法从与用户的日常互动中动态学习,这引出了一个根本性问题:我们如何构建真正拥有记忆的机器?如果模型能处理无限长的上下文,它就能将世界知识、用户偏好甚至专业技能都从上下文中即时获取,而非依赖于昂贵且缓慢的模型重训。
ArXiv URL:http://arxiv.org/abs/2511.23319v1
最近,来自蚂蚁集团和西湖大学的研究者们朝着这个目标迈出了关键一步。他们推出了一款名为HSA-UltraLong的8B模型,在仅用32K上下文训练的情况下,成功将有效上下文窗口泛化到了惊人的1600万Token,并在大海捞针(Needle-in-a-Haystack)测试中取得了超过90%的准确率!
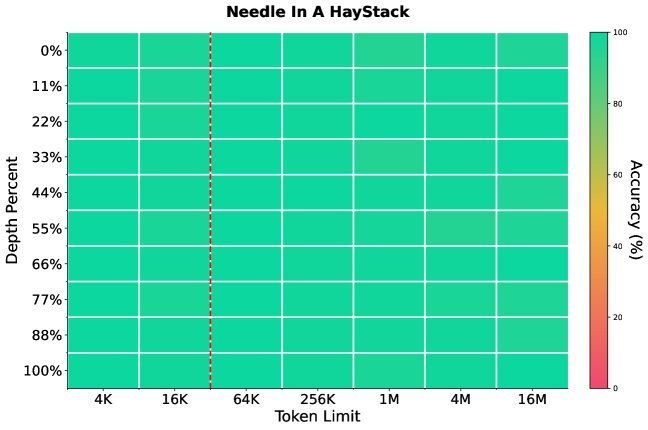
图1: HSA-UltraLong在8K预训练和32K中途训练后,在1600万Token长度的S-NIAH测试中仍能达到近乎完美的准确率。
这背后究竟隐藏着怎样的技术秘诀?
通往超长记忆的三大基石
要让模型拥有超长记忆(即处理超长上下文),传统Transformer架构面临着巨大的挑战,其注意力机制的计算复杂度会随序列长度二次方增长。研究者认为,一个理想的超长上下文模型必须具备三大特性:
-
稀疏性(Sparsity):人类的长期记忆是选择性激活的,而非“全局扫描”。同样,模型也必须稀疏地关注信息,否则计算成本将无法承受。
-
随机访问灵活性(Random-Access Flexibility):稀疏性的前提是能精准地“跳转”到过去任意相关的信息片段。模型需要一个内置的、可端到端优化的检索机制。
-
长度泛化(Length Generalization):用无限长的文本去训练模型是不现实的。模型必须具备从短上下文训练中学习,并能泛化到超长上下文的能力。
现有的方案,如循环架构(Mamba)或滑动窗口注意力,要么存在信息瓶颈,要么无法访问远距离Token,都无法同时满足这三点。
核心武器:分层稀疏注意力(HSA)
为了解决上述挑战,该研究的核心武器是一种名为分层稀疏注意力(Hierarchical Sparse Attention, HSA)的创新机制。
HSA的巧妙之处在于,它将文本切分成固定长度的“块”(chunks),然后让每个当前的Token去检索最相关的Top-k个历史文本块。这个过程与混合专家模型(Mixture-of-Experts, MoE)的运行机制惊人地相似:
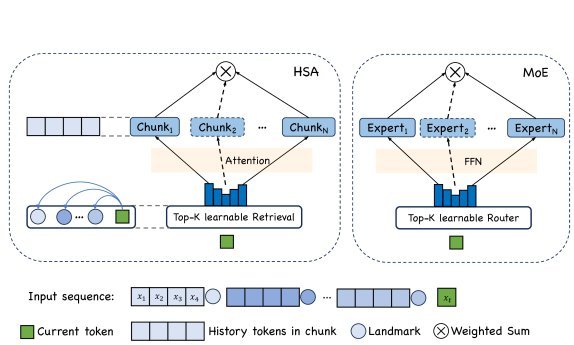
图2: HSA与MoE的类比。检索文本块如同路由到专家,对每个块做注意力计算如同调用专家,最后加权融合结果。
-
路由/检索:当前Token $x_t$ 会计算与所有过去文本块“地标表示”(landmark representations)的点积,得到检索分数,并选出分数最高的Top-k个块。这就像MoE中的路由器为Token选择最合适的k个专家。
-
处理/注意力:$x_t$ 与这k个被选中的文本块分别独立地进行注意力计算。这对应于MoE中Token被送入k个专家网络进行独立计算。
-
融合:最后,将来自k个块的注意力输出,根据它们的检索分数进行加权求和。这与MoE融合专家输出的方式如出一辙。
这种“先对每个块做注意力,再按检索分数融合”的设计,使得检索分数本身也参与了模型的前向和反向传播。这意味着模型可以在训练中自主学习:哪些文本块对于预测下一个Token更有帮助,就给它更高的检索分数。这实现了真正的端到端可学习的检索。
HSA-UltraLong 架构设计
基于HSA,研究者构建了HSA-UltraLong模型。它并非简单地用HSA替代所有注意力层,而是采用了一种更精巧的混合架构。
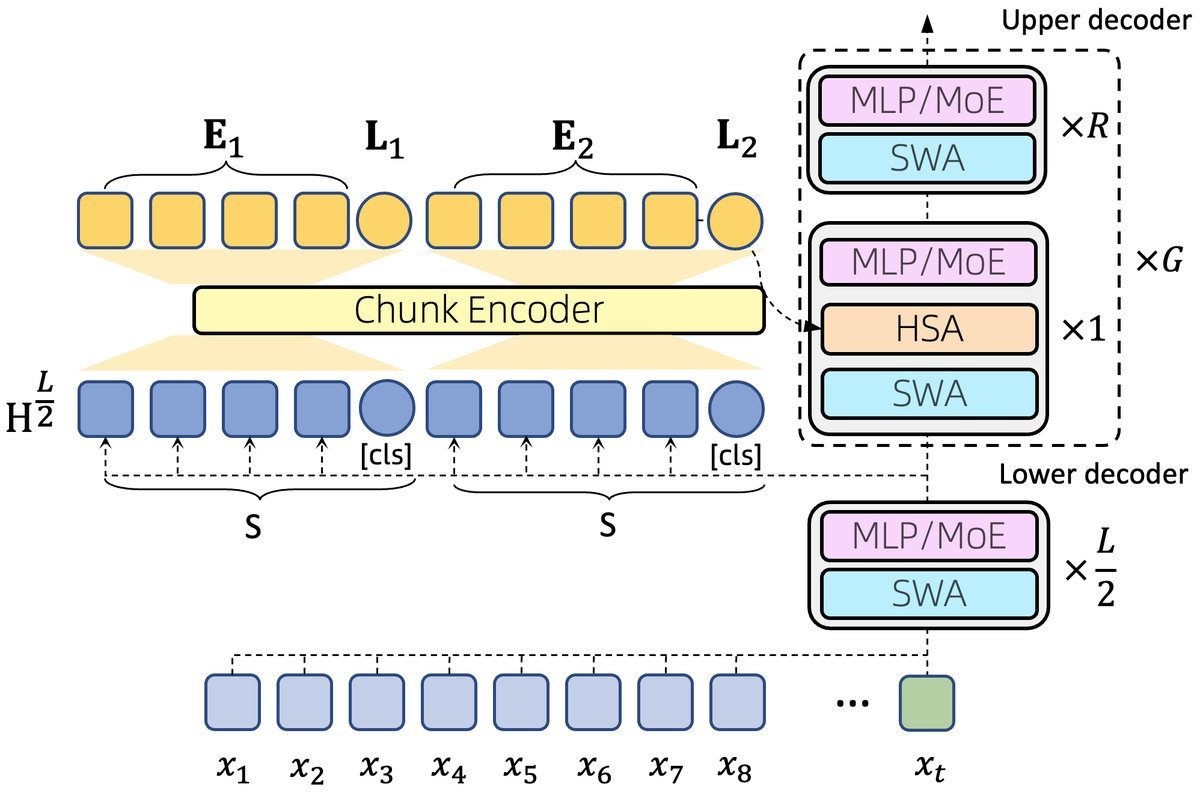
图3: HSA-UltraLong模型架构图。
如图3所示,模型分为上下两个部分:
-
下层解码器:由标准的Transformer层构成,使用滑动窗口注意力(Sliding-Window Attention, SWA)来高效处理局部上下文信息。
-
上层解码器:混合了SWA和HSA。部分层同时配备SWA和HSA,用于融合局部和全局信息;其余层仅使用SWA。
一个关键的优化是,所有HSA模块共享来自模型中间层(第$L/2$层)输出的KV缓存。这大大压缩了长序列推理时KV缓存的体积,实现了高效的“上下文记忆共享”。
训练策略:破解“跷跷板难题”
拥有了强大的架构,如何训练才能激发其长度泛化能力?研究者发现了一个棘手的“跷跷板难题”(seesaw problem):
如果SWA的窗口设置得过大(例如4K),模型在处理短距离依赖时,仅靠SWA就足够了。这导致HSA模块在短距离上“无事可做”,无法学到有效的检索模式,从而丧失了向长距离泛化的能力。
为了解决这个问题,他们设计了一套精细的多阶段训练流程,其中包含一个关键的预热(warmup)阶段。通过特定的训练策略,强制HSA模块在早期就学会处理短距离依赖,为后续的長距离泛化打下基础。整个训练过程在高达8万亿Token的数据上进行,保证了模型的综合能力。
实验效果:从32K到1600万的飞跃
经过精心设计和大规模训练,HSA-UltraLong展现了惊人的性能。
在长文本评测中,模型在32K上下文长度中途训练后,被直接用于测试高达1600万Token的任务。结果显示,在“大海捞针”测试中,无论信息“针”被藏在100万、800万还是1600万Token的“草堆”中,模型都能精准地找到它。
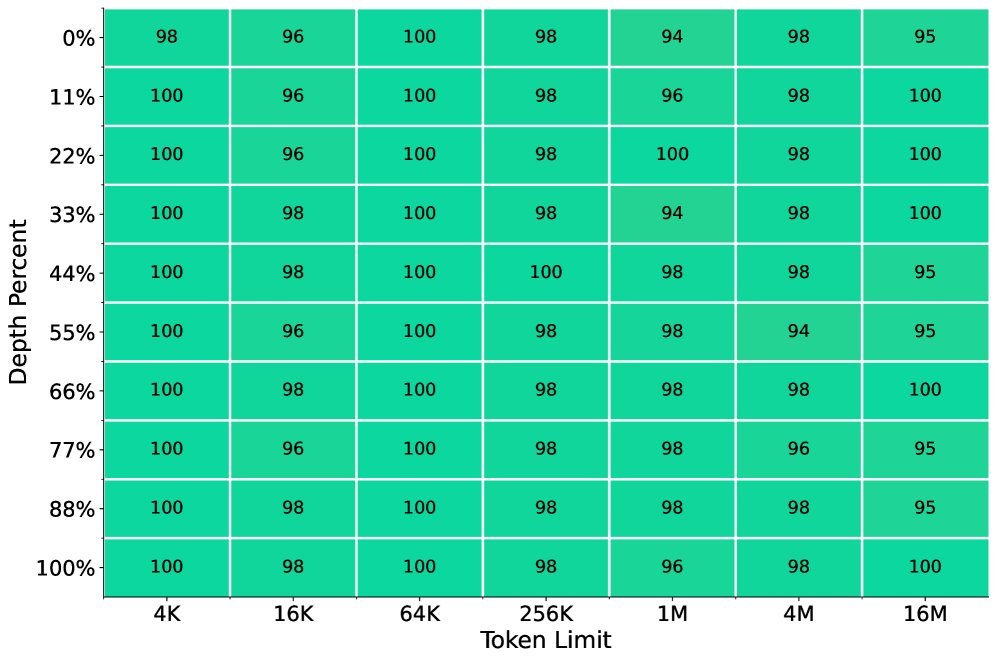
图4: 在大海捞针(MQ-NIAH)任务上,模型在16M上下文中依然保持高准确率。
此外,实验还揭示了几个重要发现:
-
三大要素缺一不可:分块注意力、基于检索分数的融合以及无位置编码(NoPE)的组合,是实现长度泛化的关键。
-
模型规模效应:在同时需要检索和推理的任务中,更大的模型(8B MoE)明显优于较小的模型(0.5B Dense),证明了模型规模对于复杂长文本任务的重要性。
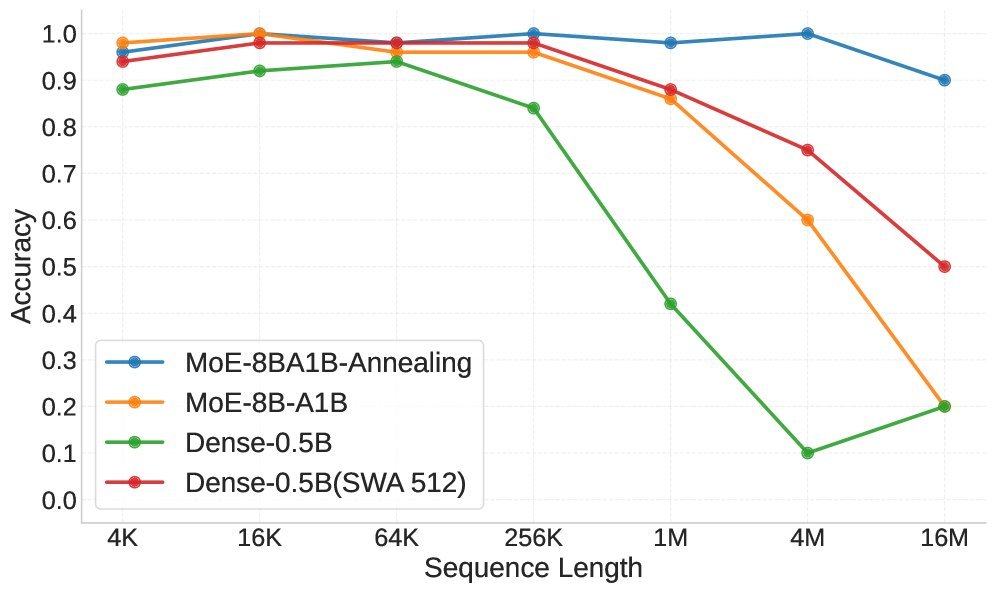
图5: 在变量追踪任务中,8B MoE模型(蓝色)的性能显著优于0.5B Dense模型(橙色)。
在效率方面,尽管HSA在处理极长序列时优势明显,但在较短序列上,其训练和推理速度仍不及高度优化的FlashAttention-3。这表明未来的工作需要在算子层面进行更深入的优化。
结论与展望
这项研究通过HSA机制,为构建拥有超长记忆的AI系统提供了一条极具前景的道路。其核心洞察——将文本块的检索过程变成一个可端到端学习的“混合专家”问题——成功破解了从短上下文泛化到超长上下文的难题。
当然,挑战依然存在,例如如何更好地平衡SWA和HSA的“跷跷板”关系、突破硬件对注意力头数的限制,以及进一步优化算子效率等。
尽管如此,HSA-UltraLong的成功实验无疑为我们描绘了一幅激动人心的未来图景:未来的AI Agent或许真的能记住从诞生到现在的每一次交互,成为真正个性化、不断进化的智能伙伴。