EvoClaw: Evaluating AI Agents on Continuous Software Evolution
AI Agent的“金鱼记忆”:EvoClaw揭示其长期编码性能从80%暴跌至38%

近来,从Devin到Claude,AI编程智能体(Agent)的能力似乎正在以惊人的速度进化,它们能独立完成复杂的编码任务,甚至解决GitHub上的真实问题。然而,这些光鲜的成功案例,是否掩盖了一个更深层次的挑战?
ArXiv URL:http://arxiv.org/abs/2603.13428v1
如果让AI Agent不是完成一次性的“冲刺”,而是参与一场持续数月的软件开发“马拉松”,它还能保持高效和稳定吗?
来自普林斯顿、斯坦福等顶尖机构的最新研究 EvoClaw 给出了一个 sobering(令人警醒)的答案:当任务从孤立的编码挑战变为连续的软件演进时,即便是最前沿的AI模型,其性能也从超过 80% 的高点,断崖式下跌至最高仅有 38%。
这项研究揭示了AI Agent在长期软件维护中一个致命的弱点:它们似乎患上了“金鱼记忆”,难以应对不断累积的技术债和错误。
现有评测的“盲区”:孤立任务 vs. 连续演进
目前的AI编码评测基准,如广为人知的SWE-bench,大多遵循一种“一次性”的模式。它们为AI Agent提供一个干净的代码库和一项独立的任务(比如修复一个Bug或添加一个新功能),任务完成后,评测即告结束。
这种模式忽略了真实世界软件开发的一个核心维度:时间。
在现实中,软件开发是一个持续不断的过程。今天的决策会成为明天的约束,早期引入的一个小缺陷,可能会在未来演变成一个巨大的技术债。这种任务间的“时间依赖性”和“错误累积效应”,在现有评测中被完全忽视了。

为了填补这一空白,研究者们首先需要一种方法,能从真实开源项目的嘈杂历史中,重建出一条条逼真的、可执行的“开发路径”。
DeepCommit:用AI重建软件的“进化史”
直接使用Git的提交(commit)历史作为评测序列并不可行。commit粒度太细,充满了大量琐碎的修改(如修复拼写错误),并且线性的提交顺序也无法反映功能开发的真实依赖关系。
为此,该研究设计了一个名为 DeepCommit 的自动化智能体流水线(Agentic Pipeline)。
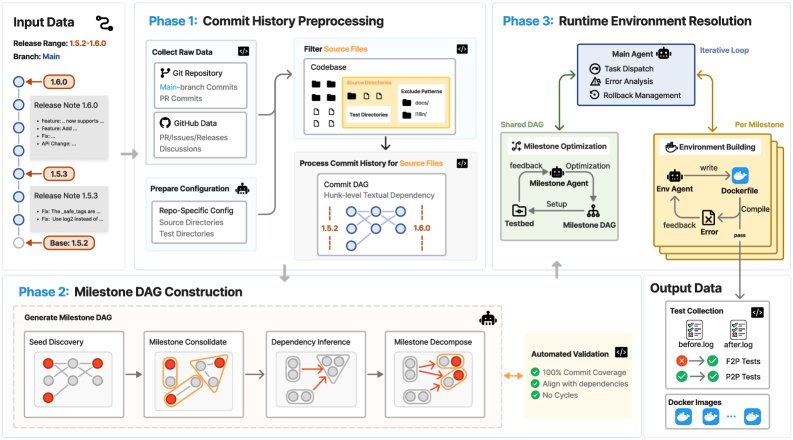
DeepCommit的核心思想是,将软件演进过程建模为一个个“里程碑”(Milestone)。每个里程碑代表一个具有内在联系的功能开发目标,它可能由数个甚至数十个commits组成。这些里程碑之间的依赖关系,自然地构成了一个有向无环图(Directed Acyclic Graph, DAG)。
这个过程分为三个阶段:
-
静态分析:从Git历史中提取commits、代码变更、PR/Issue讨论等元数据。
-
LLM Agent驱动的构建:利用大模型(如Claude Opus)的理解能力,将离散的commits聚合成有意义的里程碑,并推断它们之间的依赖关系,形成Milestone DAG。
-
运行时验证:为每个里程碑自动创建可执行、可测试的Docker环境,确保评测的可靠性。
通过DeepCommit,研究团队成功地将混乱的开源项目历史,转化为了结构化、可验证的软件演进路线图。
EvoClaw:一场对AI Agent的“马拉松”式压力测试
基于DeepCommit构建的演进路线图,EvoClaw benchmark诞生了。它包含来自7个不同开源项目的98个经过人工验证的里程碑,涵盖Go、Rust、Java、Python等五种主流编程语言。
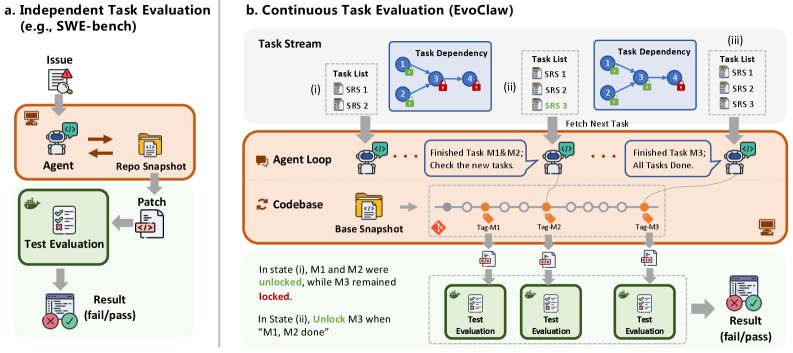
与传统评测不同,EvoClaw设计了两种截然不同的评测模式:
-
独立任务评测(Independent Task Evaluation):这是传统模式,每个里程碑任务都在一个干净、正确的代码快照上开始。这相当于“开卷考”,用来测试Agent解决单个问题的能力上限。
-
连续任务评测(Continuous Task Evaluation):这是EvoClaw的核心。Agent从一个初始代码库开始,必须按照DAG的依赖顺序,连续完成一系列里程碑任务。上一个任务的输出(无论好坏)都会成为下一个任务的输入。
这种连续模式,第一次将错误累积和技术债管理这两个真实世界的难题,引入了对AI Agent的评测中。
惊人发现:AI Agent在连续开发中集体“翻车”
研究团队在EvoClaw上对12个前沿模型(包括Claude、GPT、Gemini系列)和4种Agent框架进行了全面评估。结果令人震惊。
1. 巨大的性能鸿沟
在“独立任务”模式下,顶尖模型的表现非常出色,平均得分可以超过80%,证明了它们处理单个复杂任务的强大能力。
然而,切换到“连续任务”模式后,所有模型的性能都出现了断崖式下跌。表现最好的Claude Opus 4.6,其综合得分也仅为38.03%,而完全解决任务的比例(Resolve Rate)更是低至13.37%。
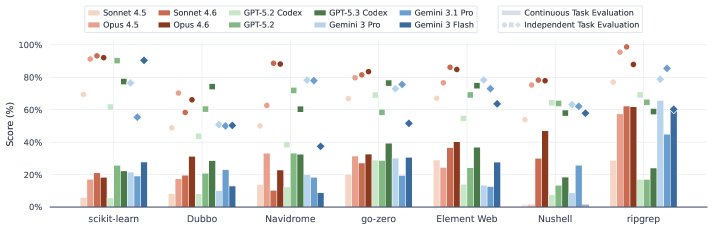
这表明,当前的AI Agent虽然擅长“单点爆破”,却极不擅长需要长期维护和保持代码库健康的“阵地战”。
2. “只见新人笑,不见旧人哭”:召回率增长,精确率饱和
为了探究性能下降的原因,研究者引入了两个关键指标:
-
召回率(Recall):衡量新功能实现得有多完整。
-
精确率(Precision):衡量在实现新功能的同时,破坏了多少已有功能(即引入了多少回归错误)。
分析发现了一个关键的不对称性:
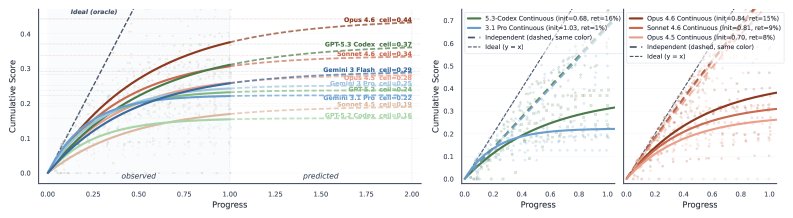
随着开发任务的推进,AI Agent的召回率基本呈线性增长,这意味着它们始终有能力去实现新的需求。然而,它们的精确率在早期迅速下降后就陷入了饱和状态,再也无法提升。
这生动地描绘了一幅画面:AI Agent就像一个只顾着开发新功能、却从不(或无力)维护旧代码的程序员。它不断给系统“添砖加瓦”,但地基却在持续被腐蚀,最终导致整个系统的崩溃。
3. 错误的“滚雪球效应”
在连续开发中,早期的一个小错误会像滚雪球一样越滚越大。研究者通过“错误链”(error chains)分析发现,一个在初期被引入的Bug,会沿着依赖关系链传播,污染下游任务,导致后续的测试大量失败,最终让整个开发过程完全停滞。
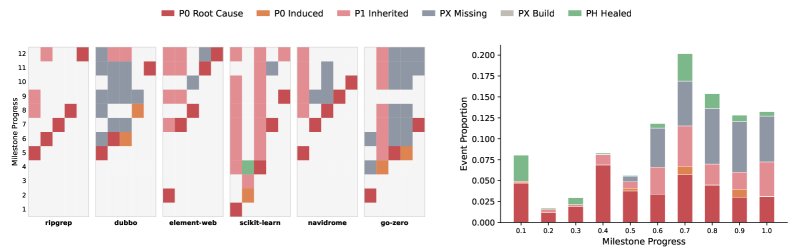
分析显示,在开发的后期阶段,绝大多数的失败都源于“继承来的失败”,而非当前任务本身引入的新错误。
4. 成功与失败的行为模式
通过分析Agent的行为日志,研究还发现:
-
成功的策略:表现更好的Agent倾向于进行更多的主动探索(比如阅读相关代码文件来理解上下文)和严格的验证(频繁运行测试来检查自己的修改)。
-
失败的陷阱:表现差的Agent则容易陷入“盲目试错”(blind thrashing)的陷阱——在不运行测试的情况下,反复修改同一段代码,这极大地加速了错误的累积。
结论
EvoClaw不仅是一个新的评测基准,更是对当前AI Agent发展方向的一次重要“校准”。它清晰地揭示了,从一个“编码助手”到一个真正的“AI软件工程师”,中间还隔着一条名为“长期软件演进”的巨大鸿沟。
这项研究告诉我们,未来的AI Agent研究,必须将重心从单纯提升单任务编码能力,转向如何让Agent具备系统级思维、管理技术债和维护代码库健康的能力。
只有当AI Agent学会了如何打好“持久战”,而不是仅仅满足于“闪电战”的胜利时,我们才能真正迎来由AI驱动的软件开发新范式。