Excess Description Length of Learning Generalizable Predictors
微调是“唤醒”还是“注入”?Anthropic提出EDL:量化模型泛化能力的标尺

当我们对大语言模型(LLM)进行微调时,一个核心但往往被忽视的问题是:模型变强了,到底是因为它学会了全新的知识(Teaching),还是仅仅被“唤醒”了沉睡在预训练参数中的潜在能力(Elicitation)?
ArXiv URL:http://arxiv.org/abs/2601.04728v1
这不仅仅是一个学术问题,它关乎模型安全与评估。如果是“唤醒”,那么哪怕只有几条数据,恶意行为者也可能解锁模型的危险能力;如果是“教学”,则门槛要高得多。然而,传统的准确率(Accuracy)或损失曲线(Loss Curve)无法区分这两者——因为在这两种情况下,指标都会上升。
为了解决这一难题,Anthropic 与加州大学伯克利分校的研究团队提出了一套基于信息论的全新框架,并定义了一个核心指标:超额描述长度(Excess Description Length, EDL)。
本文将带你深入解读这篇论文,看看 EDL 如何通过量化“被吸收的预测信息”,为理解大模型的学习机制提供一把精确的标尺。
核心概念:从压缩的角度看学习
在信息论中,学习与数据压缩有着深刻的联系。如果一个模型能很好地预测数据,它就能以更少的比特数来编码(压缩)这些数据。
论文并没有使用晦涩的深度学习术语,而是引入了前序编码(Prequential Coding)的概念。想象一下,我们在训练过程中按顺序一个个地编码训练数据的标签:
-
在第 $t$ 步,我们使用当前的非完美模型 $\theta_{t-1}$ 来预测并编码第 $t$ 个样本 $(x_t, y_t)$。
-
编码完成后,我们利用这个样本更新模型,得到 $\theta_t$。
-
重复此过程直到训练结束。
这一过程中累积的总编码长度,被称为前序最小描述长度(Prequential MDL)。它反映了我们在“边学边用”的过程中,总共花费了多少比特来描述数据。
EDL:量化“被吸收”的泛化信息
那么,什么是 EDL?
EDL 的定义非常直观:它是“训练过程中的累积编码成本”与“最终模型在测试集上的编码成本”之间的差值。
\[\text{EDL} = \text{MDL}(D; \theta_0, A) - n \cdot L_{\text{test}}(\theta^*)\]其中:
-
$\text{MDL}(D; \theta_0, A)$ 是我们在训练过程中,使用不断进化的模型对训练数据进行编码的总长度(比特数)。
-
$L_{\text{test}}(\theta^*)$ 是最终训练好的模型 $\theta^*$ 在同分布测试集上的平均损失(即每样本所需的编码长度)。
-
$n$ 是样本数量。
这个差值意味着什么?
想象一下,如果模型什么都没学到(比如标签是随机的),那么你在训练过程中每一步的预测都很烂,最终模型的预测也很烂。这两者几乎相等,相减后 EDL $\approx 0$。
反之,如果模型从数据中提取了有效的规律(泛化结构),那么最终模型 $\theta^*$ 的压缩能力将远强于训练初期的模型。这个“差值”就代表了模型从训练数据中提取并写入参数中的、有助于泛化的信息量。
为什么 EDL 能区分“唤醒”与“注入”?
论文通过一系列巧妙的玩具模型(Toy Models),展示了 EDL 在不同学习场景下的独特表现,澄清了许多关于“学习”的误区。
1. 随机标签:EDL 归零
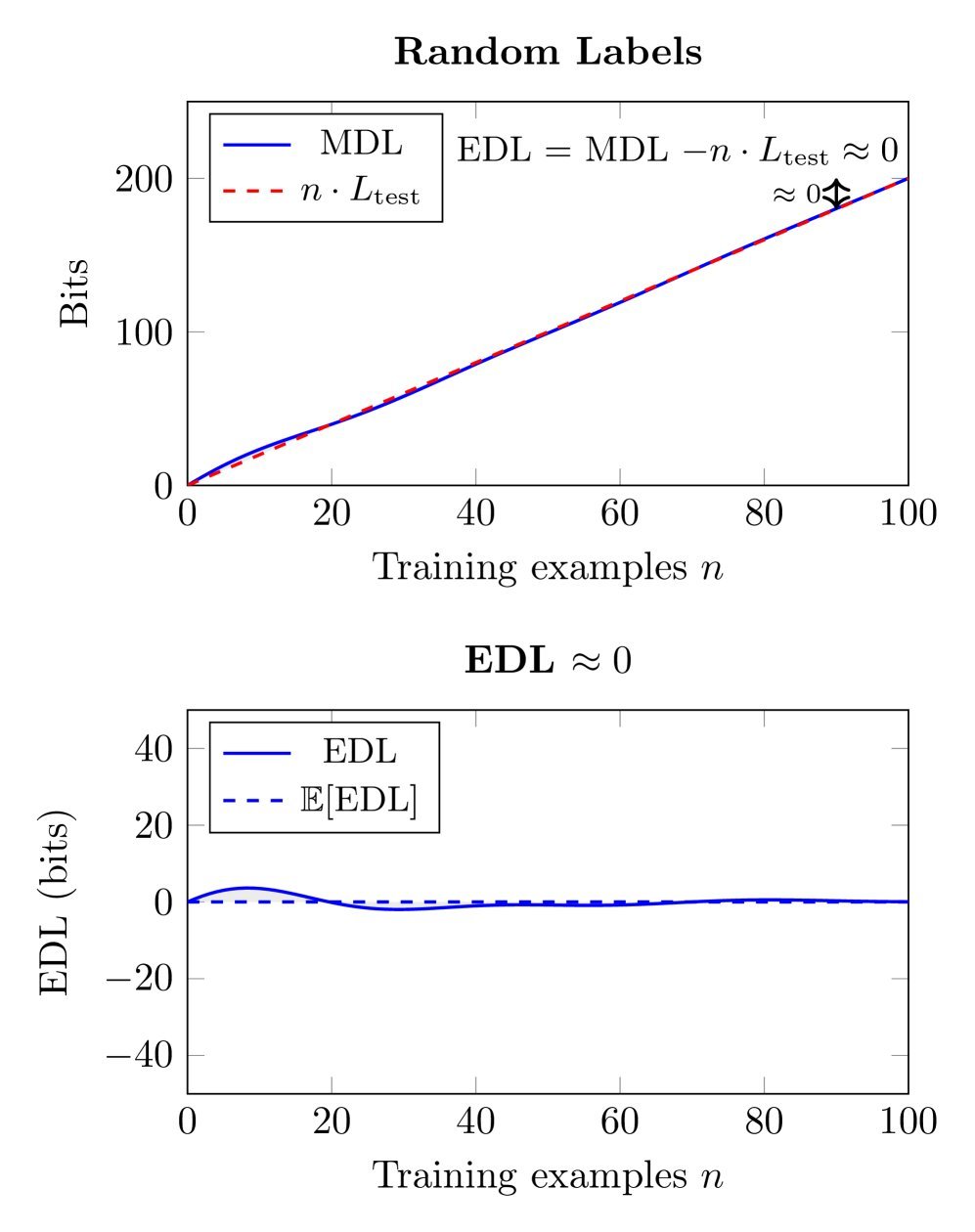
如上图所示,当标签完全随机时,无论怎么训练,测试损失($L_{test}$)都不会下降。此时,前序 MDL 的增长率与最终模型的残差编码成本一致,导致 EDL 接近于零。这验证了 EDL 的基本属性:没有泛化信息,就没有 EDL。
2. 假设坍缩(Hypothesis Collapse):单样本的高信息量
很多人直觉上认为,一个二分类标签最多只能提供 1 比特的信息。这是错误的。
如果模型预训练后已经具备了多种潜在能力(假设空间),只是不知道当前任务该用哪一种。此时,仅仅一个训练样本就可能排除掉成千上万种错误的假设,瞬间锁定正确的规则。
在这种能力唤醒(Elicitation)的场景下,极少量的样本就能带来巨大的 EDL 增益。这解释了为什么微调有时能以极低的数据成本“解锁”强大的能力——因为信息早已存在,数据只是起到了“指路”的作用。
3. 优惠券收集者效应:学习的相变
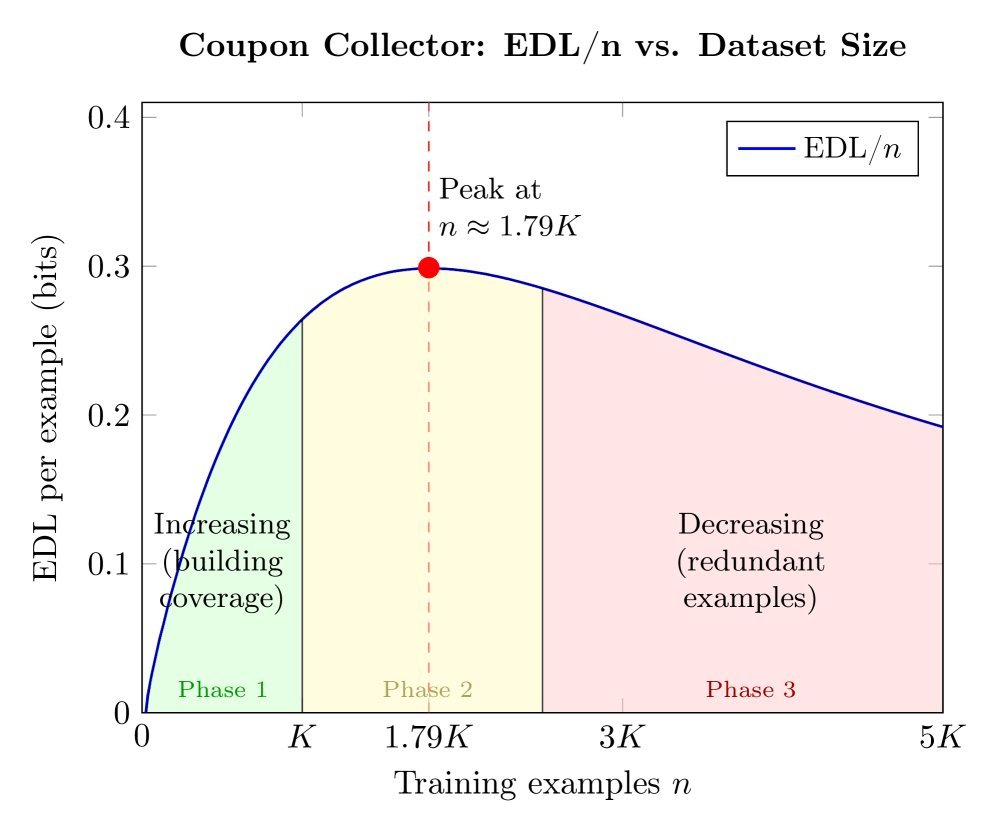
如果任务需要掌握多个独立的知识点(如上图中的“Coupon Collector”模型),学习曲线会呈现出明显的阶段性。
-
早期:模型还在摸索,EDL 增长缓慢。
-
中期:随着覆盖的知识点增多,模型开始融会贯通,EDL 迅速攀升。
-
后期:知识点已覆盖完全,新数据提供的边际信息递减,EDL 趋于饱和。
这种非线性的 EDL 增长轨迹,往往是新能力教学(Teaching)的特征,与“唤醒”场景下的快速饱和形成鲜明对比。
EDL 的理论性质与优势
除了直观的解释,论文还为 EDL 建立了严谨的数学基础:
-
非负性:在期望上,EDL $\ge 0$。只要训练算法是合理的(population-monotonic),训练就不会“破坏”模型原本的预测能力。
-
可计算性:与传统的剩余描述长度(Surplus Description Length, SDL)不同,SDL 需要知道理论上的“最优损失” $L^*$(这在现实中几乎不可能获得)。而 EDL 只需要训练过程中的 Loss 和最终的 Test Loss,这使得它在实际的大模型实验中完全可计算。
-
与泛化的联系:EDL 直接给出了期望泛化增益的上界。EDL 越高,意味着模型相对于初始状态,在泛化能力上的提升越显著。
总结
Excess Description Length (EDL) 提供了一个全新的视角来审视大模型的微调过程。它不再仅仅关注“模型现在的表现如何”,而是关注“模型从数据中吸收了多少有效信息”。
通过区分能力唤醒(高效率、低数据量的 EDL 爆发)和新能力注入(需要大量数据覆盖的 EDL 缓慢积累),EDL 为 AI 安全研究人员提供了一种强有力的工具。它提醒我们:当微调看似简单时,也许我们只是在唤醒一头沉睡的巨兽;而当微调艰难时,我们才是在真正地教导它。