Exploration v.s. Exploitation: Rethinking RLVR through Clipping, Entropy, and Spurious Reward
随机奖励竟能提升数学推理?阿里新作揭秘RLVR背后的“熵减”魔法

DeepSeek-R1、OpenAI-o1 等推理模型的崛起,让带验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards, RLVR)成为了当下的技术显学。但在大家疯狂卷算法的时候,一个极其反直觉的现象困扰着研究人员:有研究表明,给模型喂完全随机的“虚假奖励”(Spurious Rewards),竟然也能提升模型的数学推理能力!
ArXiv URL:http://arxiv.org/abs/2512.16912v1
这完全违背了传统强化学习的直觉——随机奖励理应引入噪声,破坏模型的判断,怎么反而成了“灵丹妙药”?
来自阿里巴巴、哥伦比亚大学、纽约大学等机构的研究团队发表了一篇硬核论文,深入剖析了这一悖论。他们发现,所谓的“随机奖励有效”并非因为模型真的学到了什么,而是RLVR算法中的截断机制(Clipping)与熵(Entropy)在暗中“作祟”。
RLVR 的反直觉悖论
在数学或代码生成任务中,RLVR 通常使用组相对策略优化(Group Relative Policy Optimization, GRPO)来训练模型。与传统RL不同,RLVR面临两个奇怪的现象:
-
虚假奖励(Spurious Rewards):给模型随机的奖励(与真实结果无关),在某些情况下(如 Qwen-Math 模型)竟然能提升性能。传统观点认为这是因为“截断偏差”(Clipping Bias)放大了模型潜在的正确记忆(即污染效应)。
-
熵最小化(Entropy Minimization):通常我们希望模型多探索(高熵),但在RLVR中,强制降低熵、让模型变得更“自信”和确定,反而能提升推理准确率。
这篇论文的核心任务,就是搞清楚这两个机制到底是如何相互作用的。
截断偏差:真的是“功臣”吗?
学术界流行一种解释:在 PPO 或 GRPO 中,目标函数里的 \(clip\) 操作引入了一个正向的偏差(Upper-clipping bias),这使得模型在面对随机奖励时,依然能强化那些概率较高的输出。
然而,本文的作者通过严格的数学推导,推翻了这一主流观点。
研究团队定义了“总截断修正项” $C_{\textnormal{tot}}^{+}$,并将其与未截断的原始信号 $N_{\textnormal{raw}}$ 进行了对比。根据论文中的 Theorem 3.4,在实际训练的超参数设置下(如学习率 $\eta=5\times 10^{-7}$,截断率 $\varepsilon=0.2$),原始信号的量级远远大于截断修正项:
\[\frac{{\mathbb{E}}[ \mid N_{\textnormal{raw}} \mid ]}{{\mathbb{E}}[ \mid C_{\textnormal{tot}}^{+} \mid ]} \approx 17.15\]这意味着,截断偏差提供的学习信号微乎其微,根本不足以驱动模型性能的显著提升。简单来说,指望靠“截断”本身来从随机奖励中“淘金”,在数学上是站不住脚的。
真正的幕后推手:熵与确定性
如果不是截断偏差直接提供了学习信号,那随机奖励下的性能提升从何而来?
论文揭示了一个更深层的机制:截断操作实际上充当了一个“熵减”器。
在随机奖励下,虽然梯度的期望方向可能是乱的,但截断机制(Clipping)会系统性地减少策略熵(Policy Entropy)。
-
无截断时:随机奖励下的策略更新会让模型在探索和利用之间摇摆,熵保持不变。
-
有截断时:截断限制了更新幅度,但这种限制是非对称的。它倾向于让策略分布变得更尖锐(Peaked),即模型变得更“自信”、更确定。
这种由截断引发的熵减(Entropy Minimization effect),迫使模型从发散的探索状态,收敛到某些确定性的输出路径上。如果模型本身已经具备了一定的能力(比如经过了SFT),这种“强行自信”反而能让它在推理任务上表现得更好,哪怕奖励信号本身是噪声。
实验验证:Qwen-Math 的真相
为了验证这一理论,研究人员使用 Qwen2.5-Math-7B 在 DeepScaleR 数据集上进行了实验,故意使用随机奖励(Bernoulli(0.5))进行训练。
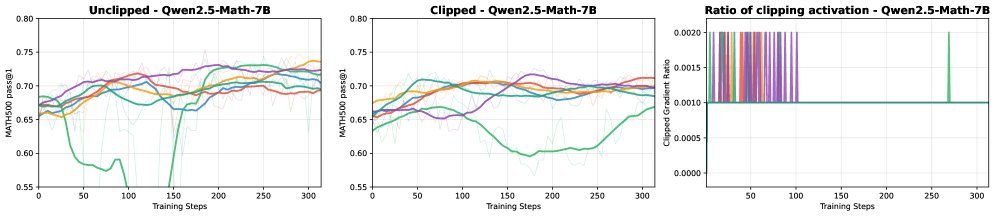
上图展示了实验结果:
-
蓝色线(No Clipping):没有截断时,模型在随机奖励下性能提升明显。
-
橙色线(With Clipping):开启截断后,性能反而出现了波动甚至下降。
这似乎与直觉相反?其实不然。这恰恰说明,在随机奖励下,截断并不是直接提升性能的“神器”。图中的结果表明,简单的截断偏差理论无法解释所有现象。
作者进一步指出,随机奖励带来的收益,更多是一种奖励错位(Reward-misalignment)现象。对于像 Qwen-Math 这样可能存在数据污染或过拟合的模型,随机奖励配合熵减机制,实际上是在强化模型“背诵”或“复现”高置信度答案的倾向,而非真正学会了逻辑推理。
总结与启示
这篇论文给火热的 RLVR 研究泼了一盆冷静的冷水,也带来了深刻的启示:
-
不要迷信随机奖励:随机奖励带来的性能提升,往往是模型内在偏好被放大的结果,而非真正的能力增长。
-
截断不仅仅是修剪:在 GRPO 等算法中,\(clip\) 操作不仅仅是为了稳定训练,它还隐式地充当了熵正则化项,强行降低模型的不确定性。
-
警惕“虚假繁荣”:如果你的模型在随机奖励下都能涨点,先别高兴,这可能意味着你的模型在“吃老本”(利用预训练知识或数据污染),而不是在“学新知”。
这项研究为我们理解大模型如何通过强化学习进化提供了更清晰的物理图像:在探索(Exploration)与利用(Exploitation)的博弈中,算法的微小细节(如 Clipping)往往起着决定性的作用。