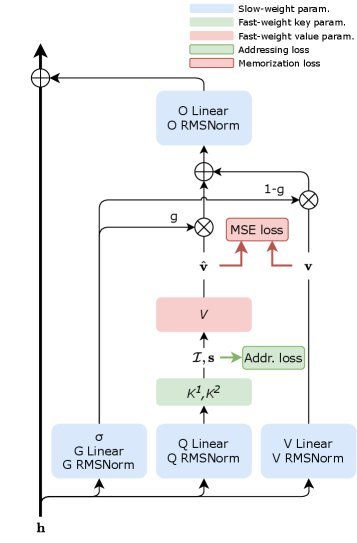
Fast-weight Product Key Memory
Sakana AI新作:赋予模型“即时记忆”,4K训练竟能泛化至128K长文

如果大模型像人类一样阅读一本书,目前的架构往往面临一个两难的选择:要么像 Transformer 那样拥有“过目不忘”的能力,但随着书本变厚,脑容量(显存和计算量)呈平方级爆炸;要么像线性注意力(Linear Attention)那样读得飞快,但“读了后页忘前页”,受限于固定的记忆容量。
ArXiv URL:http://arxiv.org/abs/2601.00671v1
有没有一种架构,既能保持线性的高效率,又能像人脑一样灵活地进行“情景记忆”?
以“进化算法”闻名的 Sakana AI 团队近日提出了一种全新的架构——\(**Fast-weight Product Key Memory**\)(FwPKM)。这项研究打破了传统思维,让模型在推理阶段也能“实时训练”,从而获得了惊人的长文本泛化能力:仅在 4K 长度的序列上训练,却能在 128K 长度的“大海捞针”测试中表现出色。
从“慢权重”到“快权重”:让记忆动起来
在现代语言模型中,我们通常认为参数(Weights)是静态的——它们在训练完成后就固定下来,被称为“慢权重”(Slow Weights),负责存储通用的语言知识和世界知识。
然而,人类在阅读时,会迅速建立临时的“情景记忆”(Episodic Memory),比如记住小说主角的名字或当前的剧情设定。这种记忆是动态的、短暂的。
Sakana AI 的核心洞察在于:为什么不让模型的一部分参数在推理时也能更新呢?
该研究基于经典的 \(**Product Key Memory**\)(PKM)架构进行了大刀阔斧的改造。传统的 PKM 只是一个静态的大容量记忆库,而 FwPKM 将其转变为动态的“快权重”(Fast Weights)系统。
简单来说,FwPKM 允许模型在处理输入序列时,通过局部的梯度下降(Local Gradient Descent)实时更新自身的键值对(Key-Value)。这意味着模型在“读”数据的同时,也在“写”入记忆。
FwPKM 的核心魔法:推理即训练
FwPKM 的工作流程可以概括为以下几个精妙的步骤:
-
动态写入(Memorization):
当一段新的文本(Chunk)进来时,模型不仅进行预测,还会计算一个局部的重构损失(MSE Loss)。模型会问自己:“如果我要把这段信息存入记忆,我的参数应该怎么变?”然后,它利用这个梯度信号实时更新 FwPKM 模块的参数 $\theta$。
\[\theta^{\prime} =\theta-\eta\nabla_{\theta}\mathcal{L}_{\text{MSE}}\]这个过程发生在推理阶段,相当于模型拥有了一个可以随时擦写的“草稿本”。
-
高效寻址(Product Key):
为了在巨大的内存空间中快速找到读写位置,FwPKM 沿用了 PKM 的笛卡尔积(Cartesian Product)寻址机制。它将查询向量分解为两个子查询,分别在两个较小的子键矩阵中检索,从而以极低的计算成本实现了对大规模记忆槽位(例如 $10^6$ 个)的访问。
-
门控机制(Gating):
并不是所有信息都需要存入情景记忆。模型引入了一个门控值 $g_t$,智能地决定是依赖静态的“慢权重”知识,还是调用动态的 FwPKM “快权重”记忆。
实验结果:以小博大的长文本能力
FwPKM 的实验结果令人印象深刻,尤其是在长文本处理上展现出了独特的优势。
1. 惊人的长度泛化能力
这是该论文最震撼的发现。研究人员仅使用 4K token 的序列长度训练模型,但在测试时,FwPKM 能够处理长达 128K token 的上下文。
在经典的“大海捞针”(Needle in a Haystack, NIAH)测试中,传统的全注意力(Full Attention)模型在超出训练长度后性能迅速崩塌,而 FwPKM 依然保持稳健。
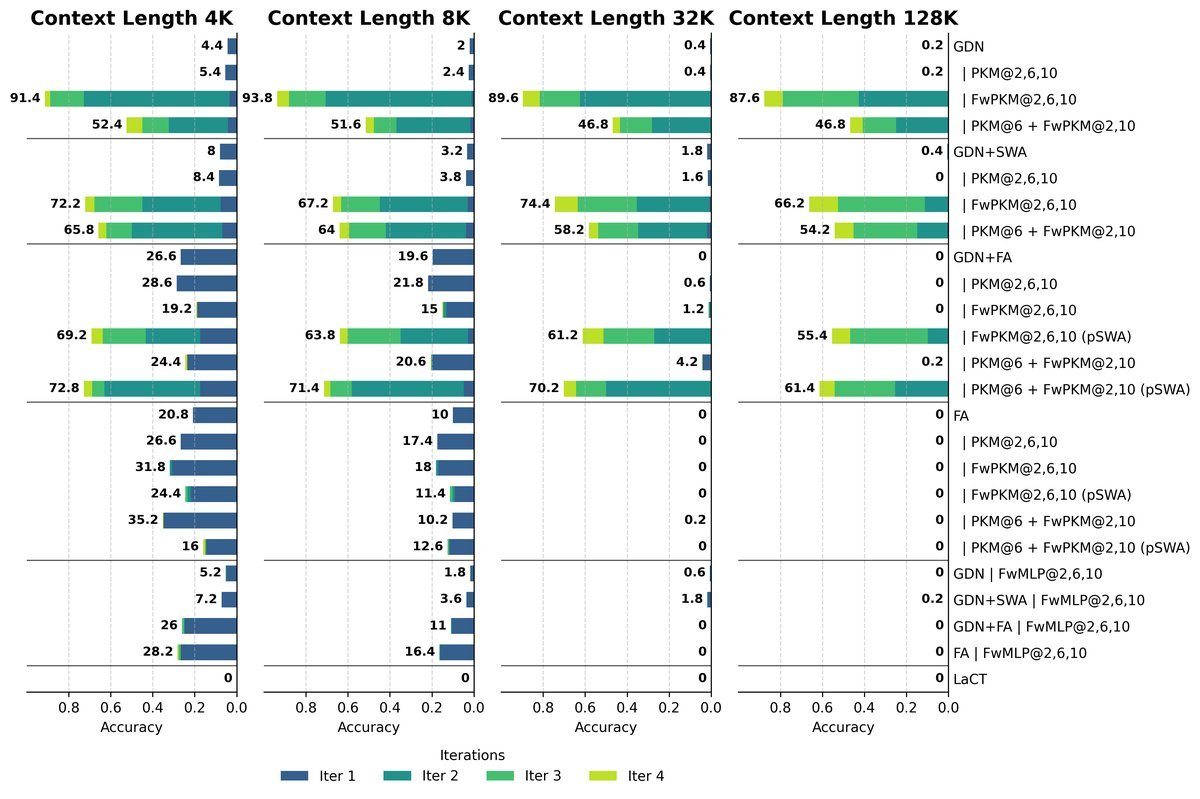
2. “反复阅读”带来的质变
研究发现,由于 FwPKM 具有动态更新的特性,让模型对同一段长文本进行“反复阅读”(Iterative Reading),可以显著提升检索准确率。如上图所示,从第 1 次阅读到第 2 次阅读,准确率出现了大幅跃升。这像极了人类的学习过程:第一遍浏览建立印象,第二遍精读巩固记忆。
3. 与全注意力机制的互补
实验表明,FwPKM 并不是要完全取代 Attention,而是与其形成互补。
-
标准 Attention:负责处理复杂的语义依赖。
-
FwPKM:作为高效的情景记忆,负责存储长距离的具体信息(如人名、特定数值)。
可解释性:看看模型记住了什么?
与黑盒子的神经网络不同,FwPKM 的记忆槽位是显式的。研究人员可以打开这些槽位,看看模型到底存了什么。
在对“Sakana AI”维基百科页面的分析中,研究人员发现了一个有趣的现象:
-
低层的 FwPKM:像一个通用的缓冲区,门控值普遍较高,存储各类信息。
-
高层的 FwPKM:表现出极强的选择性,门控值只在遇到稀有实体(如 “Sakana AI”, “David Ha”)时才会飙升。
这说明模型已经学会了自动区分“通用语言模式”(交给慢权重)和“新鲜事”(交给快权重)。
总结
Sakana AI 的这项工作为解决 LLM 的“记忆难题”提供了一条极具潜力的道路。通过复活并改良“快权重”这一经典概念,FwPKM 证明了我们不需要仅仅依赖昂贵的注意力窗口来扩展上下文。
让模型在推理时“边走边记”,或许正是通向无限上下文与终身学习(Continual Learning)的关键一步。