Fine-tuning Small Language Models as Efficient Enterprise Search Relevance Labelers
速度飙升17倍,成本仅1/19:微软亚马逊用小模型“蒸馏”搞定企业搜索标注

在企业级搜索领域,由于数据隐私和专业性的限制,构建高质量的标注数据集一直是一个令人头疼的难题。虽然利用 GPT-4 这样的大语言模型(Large Language Models, LLMs)进行自动标注已成为一种流行方案,但其昂贵的推理成本和缓慢的吞吐量,使其难以在生产环境中大规模应用。
ArXiv URL:http://arxiv.org/abs/2601.03211v1
这就引出了一个核心问题:我们能否用一个“小巧玲珑”的模型,通过“蒸馏”大模型的智慧,在保持高精度的同时,实现极致的效率和低成本?
来自 Amazon 和 Microsoft 的研究团队给出了肯定的答案。他们提出了一种全新的合成数据生成与微调流水线,将 Phi-3.5 Mini 这样的小模型(Small Language Models, SLMs)训练成了高效的相关性标注器。结果令人咋舌:该模型不仅在标注质量上匹敌甚至超越了作为“老师”的 GPT-4o,更实现了 17倍的吞吐量提升 和 19倍的成本缩减。
企业搜索的独特挑战
与我们熟悉的 Web 搜索不同,企业搜索面临着独特的困境。
首先是查询的歧义性。在公网搜索“Juno release date”,用户通常指电影《朱诺》;但在企业内部,这可能指代名为“Juno”的项目、服务器,甚至是某个名为 Juno 的同事发送的邮件。其次,企业数据高度敏感,无法像 MS MARCO 那样公开大规模数据集。
这导致企业搜索缺乏高质量的训练数据。传统的解决方案是依赖人工标注(太慢、太贵、涉及隐私)或直接调用 LLM 进行标注(太慢、太贵)。
核心方法:合成数据流水线
为了打破这一僵局,研究团队设计了一套无需人工查询日志的合成数据生成流水线。该方法仅需少量的种子文档,即可自动生成高质量的训练数据。
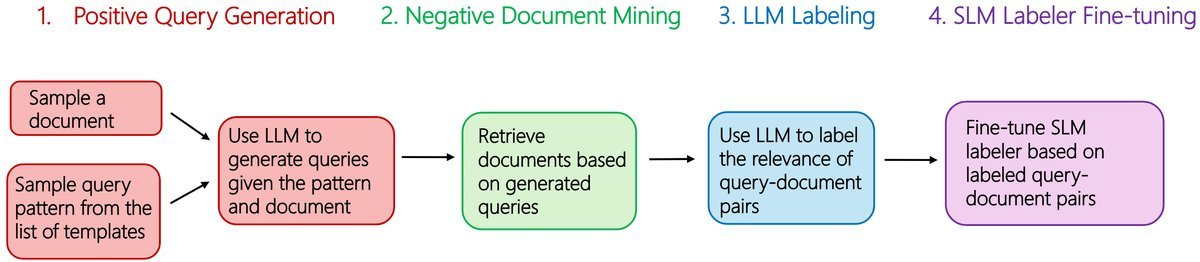
整个流程分为四个关键步骤:
-
合成查询生成(Synthetic Query Generation):
利用 GPT-4o 基于种子文档生成逼真的企业查询。为了模拟真实场景,研究者不仅生成语义查询,还特别针对企业搜索中常见的“关键词匹配”特性进行了优化。
-
负样本挖掘(Negative Mining):
这是提升模型分辨能力的关键。研究者使用经典的 BM25 算法检索出那些字面上相似但实际上不相关的文档(即“困难负样本”,Hard Negatives)。设定 $k=4$ 使得正负样本比例均衡,迫使模型学习细微的语义差异。
-
LLM 教师标注(LLM Labeling):
使用 GPT-4o 作为“教师”,对生成的 <查询,文档> 对进行打分(0-4分)。这一步将大模型的判别能力“外化”为标签。
-
SLM 蒸馏微调(SLM Distillation):
最后,利用上述生成的 <查询,文档,分数> 三元组,对 Phi-3.5 Mini Instruct 进行指令微调。
实验结果:小模型的大逆袭
研究团队在一个包含 923 个由受过训练的人类标注员标注的高质量基准数据集上进行了评估。
1. 质量:青出于蓝而胜于蓝
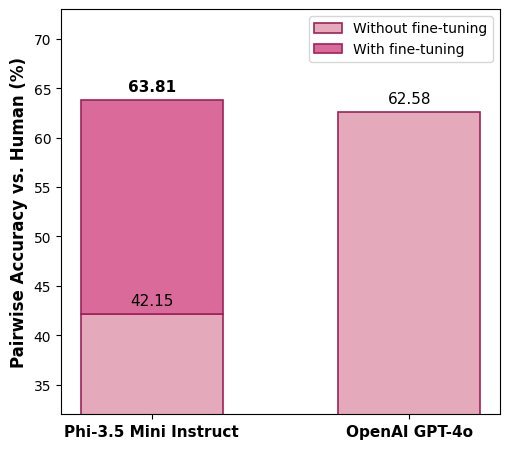
最令人惊讶的发现是,经过微调的 SLM 在与人类判断的一致性上,不仅大幅超越了原始模型,甚至略微优于它的“老师” GPT-4o。
-
NDCG 指标:微调后的 SLM 达到了 0.953,而 GPT-4o 为 0.944。
-
成对准确率(Pairwise Accuracy):SLM 达到 63.81%,同样高于 GPT-4o 的 62.58%。
这表明,通过专注于特定领域的微调,小模型完全可以捕捉到企业搜索中复杂的 relevance 模式。
2. 效率与成本:降维打击
在实际部署中,效率就是金钱。
-
吞吐量:在单张 A100 GPU 上,微调后的 SLM 达到了 873 RPM(每分钟请求数),相比之下,大模型的 API 调用通常受限于几十到几百 RPM。这意味着处理速度提升了约 17倍。
-
成本:在输入和输出 token 的计费上,使用 Phi-3.5 Mini 的成本仅为 GPT-4o 的 1/19。
深度洞察:数据质量 > 数量
研究团队还进行了一系列消融实验,得出了对业界非常有价值的结论:
-
数据质量至关重要:如果不经过查询优化(Query Refinement)步骤,直接使用原始合成数据,模型性能会显著下降(准确率从 63.81% 跌至 60.97%)。
-
数据量的边际效应:实验发现,当合成数据量从 14k 增加到 24k 时,模型性能几乎没有提升。这说明在特定领域的微调中,1.4万条高质量数据可能已经触及了性能天花板,盲目堆砌数据并无必要。
-
多任务微调的加持:在微调过程中加入通用的指令数据集(如 INTERS),有助于提高模型的泛化能力和鲁棒性。
总结
这项研究证明了在企业级应用中,“大模型生成数据 + 小模型微调蒸馏” 是一条极具潜力的技术路径。它不仅解决了数据隐私和稀缺的问题,更通过将 Phi-3.5 Mini 这样的轻量级模型打造成高性能的标注器,为企业搜索的离线评估和快速迭代提供了一个既快又省的解决方案。
对于正在构建 RAG(检索增强生成)或企业搜索系统的开发者来说,这或许意味着你不必再为昂贵的 GPT-4 账单发愁,一个小巧精悍的本地模型,可能正是你需要的答案。