让AI像人一样“吃一堑长一智”:FLEX框架使Agent性能飙升23%
当前的大模型Agent(智能体)虽然能力强大,但它们都有一个共同的“健忘症”:一旦训练完成,就变成了静态的工具。无论在任务中成功还是失败,它们都无法吸取教训,下次遇到同样的问题还是会犯同样的错。这与人类通过经验不断成长的学习方式相去甚远。
论文标题:FLEX: Continuous Agent Evolution via Forward Learning from Experience
ArXiv URL:http://arxiv.org/abs/2511.06449v1
现在,来自字节跳动和清华大学等机构的研究者们,提出了一种全新的学习范式——FLEX(Forward Learning with EXperience)。
它彻底颠覆了传统的学习方式,让AI Agent能够在与环境的交互中,通过反思成败来积累经验,实现持续进化。
最关键的是,这个过程完全无需梯度反向传播,成本极低,却在数学、化学、生物等多个领域的难题上取得了高达23%的性能提升!
困境:为何今天的Agent“学不会”?
我们都知道,AI模型依赖于梯度下降(Gradient Descent)进行学习,通过反向传播来微调亿万个参数。
但这个过程对于Agent的持续进化来说,存在三大障碍:
-
成本高昂:对大型模型进行反向传播需要巨大的计算资源。
-
灾难性遗忘:在学习新知识时,模型很容易忘记旧有的能力。
-
模型封闭:像GPT-4这样的顶级模型都是闭源的,我们根本无法访问其参数进行微调。
虽然有研究尝试通过修改提示词或工作流来“进化”,但这些方法往往是任务特定的,无法跨领域泛化,也难以随着经验的增多而持续提升。
FLEX:一种前向学习新范式
FLEX提出了一种截然不同的思路:学习的重点不应是修改模型参数,而是构建和利用一个可演化的“经验图书馆”。
传统学习包含“前向传播”和“反向传播”两个过程。
而FLEX将学习简化为纯粹的前向过程,分为三个阶段:
-
前向探索:大胆尝试解决问题,获取大量的成功与失败经验。
-
经验演化:通过一个“更新器”Agent,对经验进行反思、提炼,并更新到经验库中。
-
前向引导:在解决新问题时,从经验库中检索相关知识,指导推理过程。
这种范式带来了三个深刻的优势:
-
可扩展性:经验库可以持续扩充,AI的性能随经验积累而增长。
-
可继承性:经验以结构化文本形式存储,可以轻松地在不同Agent间“即插即用”,无需从零开始学习。
-
跨任务性:从一个任务中学到的高阶策略,可以被用于解决其他任务。
核心机制:双层MDP与经验图书馆
为了实现这一优雅的构想,FLEX设计了一套精巧的机制,可以将其理解为一个分工明确的“战略指挥部”。该研究将其形式化为分层马尔可夫决策过程(Meta-MDP)。
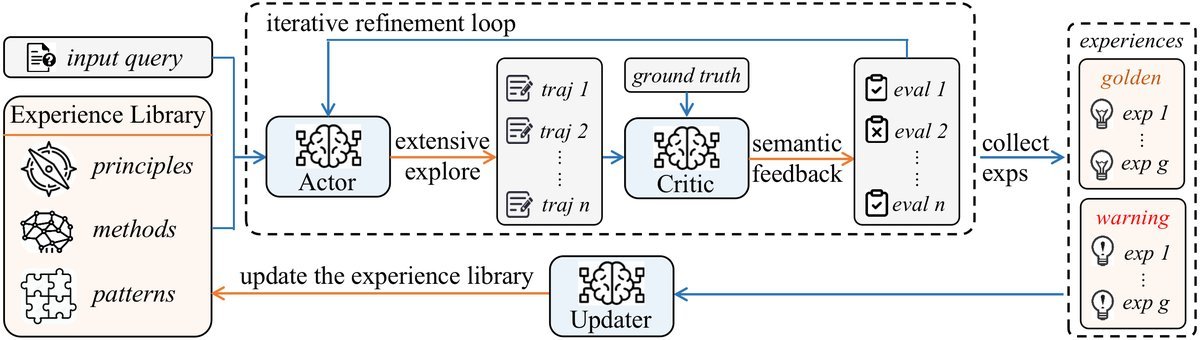
底层MDP:一线探索与经验提炼
这可以看作是“一线作战单元”。它由一个行动者(Actor)和一个评论家(Critic)组成。
-
行动者负责生成解决问题的具体步骤。
-
评论家则负责评估行动者的方案。如果失败了,它会分析失败原因,并给出“语义反馈”(即用自然语言提出的改进建议),指导行动者进行下一轮尝试。
这个“尝试-反馈-修正”的闭环,就是经验产生的过程。成功的路径和失败的教训都会被记录下来。
上层MDP:全局调度与经验演化
这相当于“总指挥部”。它负责维护一个全局的、分层的经验图书馆。
-
分层结构:这个图书馆被巧妙地组织为三个层次:高层战略原则、中层推理模式、底层具体案例。
-
双区设计:它还分为“黄金区”(存储成功经验)和“警示区”(记录失败教训),实现从正反两方面学习。
当底层探索单元提交新经验时,“更新器”Agent会决定是新增、合并还是丢弃该经验,确保图书馆的高效和无冗余。
在解决新问题时,Agent可以像查阅资料一样,在这个图书馆中进行上下文相关的检索,从而获得强大的外部知识支持。
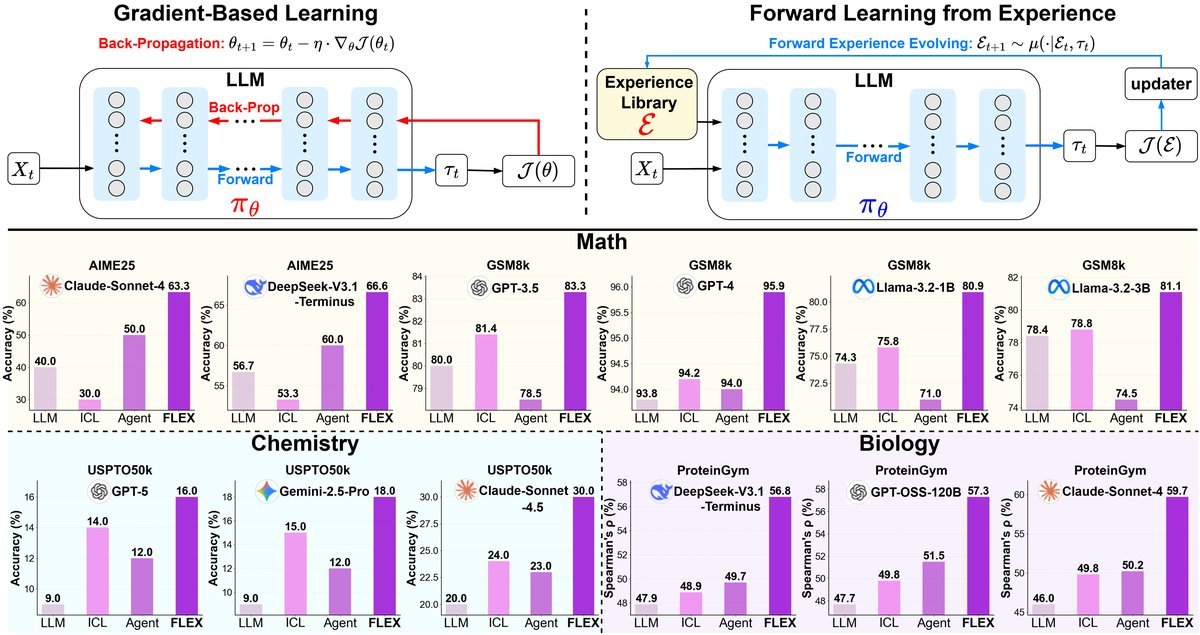
实践效果:跨领域的显著提升
理论再好,也要看疗效。FLEX在数学、化学、生物三大科学领域的挑战性任务上,都取得了惊人的成果。
| 模型 | 基准 | Vanilla | ICL | Agent | FLEX (本文) |
|---|---|---|---|---|---|
| Claude-Sonnet-4 | AIME25 | 40.0 | - | 42.0 | 63.3 (+23.3) |
| GPT-4 | GSM8k | 93.4 | 92.5 | 95.3 | 95.9 (+0.6) |
| Claude-Sonnet-4.5 | USPTO50k | 20.0 | 20.0 | 20.0 | 30.0 (+10.0) |
| GenAI-FLEX-128k | ProteinGym | 0.460 | - | 0.460 | 0.602 (+0.142) |
-
数学推理:在极具挑战的AIME25数学竞赛数据集上,FLEX仅用49个例题进行学习,就将Claude-Sonnet-4的准确率从40.0%大幅提升至63.3%,实现了惊人的23.3%绝对性能增长。
-
化学合成:在专业的USPTO50k逆合成任务上,通用大模型表现不佳。FLEX通过学习50个例子,就让Claude-Sonnet-4.5的准确率从20%提升至30%,效果翻倍。
-
生物预测:在ProteinGym蛋白质适应性预测任务中,FLEX同样表现出色,将模型的预测相关性从0.46提升至0.602,实现了14.2%的提升。
此外,研究还发现,Agent的性能与经验库的大小存在明确的经验规模法则(Scaling Law of Experience),并且经验库可以在不同模型间继承(Experience Inheritance),实现知识的快速迁移。
结语
FLEX范式为我们描绘了一幅激动人心的未来图景:AI Agent不再是出厂即固化的静态工具,而是能够像智慧生命一样,在实践中不断学习、反思和成长的动态伙伴。
通过将学习的核心从调整参数转向构建经验,FLEX开辟了一条高效、低成本且可解释的Agent进化之路,标志着我们向着可扩展、可继承的持续进化智能体迈出了坚实的一步。