FLEx: Language Modeling with Few-shot Language Explanations
仅需4-11个纠错案例!FLEx:消除大模型83%顽固错误,无需参数微调

大模型(LLM)虽然在数学解题和开放问答上表现出色,但它们有一个令人头疼的毛病:死性不改。如果模型在一个特定的逻辑陷阱上跌倒,它往往会在类似的查询中反复跌倒。
ArXiv URL:http://arxiv.org/abs/2601.04157v1
通常,我们想到的解决办法要么是昂贵的微调(Fine-tuning),要么是复杂的检索增强生成(RAG)。但有没有一种更轻量级的方法,能像人类老师一样,总结几个典型错题,就能让模型“举一反三”?
来自佐治亚理工学院和微软的研究团队提出了一种名为 FLEx (Few-shot Language Explanations) 的新方法。令人惊讶的是,它仅需 4 到 11 个 经过验证的纠错案例,就能在不更新任何模型参数的情况下,消除高达 83% 的残留错误。
什么是 FLEx?
FLEx 的核心理念非常直观:与其给模型灌输海量数据,不如教它从典型的错误中总结规律。
现有的思维链(CoT)虽然能提升推理能力,但无法系统性地防止重复错误。FLEx 则通过引入少量高质量的自然语言解释,将这些解释“蒸馏”成一个简短的提示前缀(Prompt Prefix)。在推理时,这个前缀就像一个“锦囊”,时刻提醒模型避开之前的坑。
FLEx 的“三步走”魔法
FLEx 的工作流程非常清晰,主要包含三个步骤:
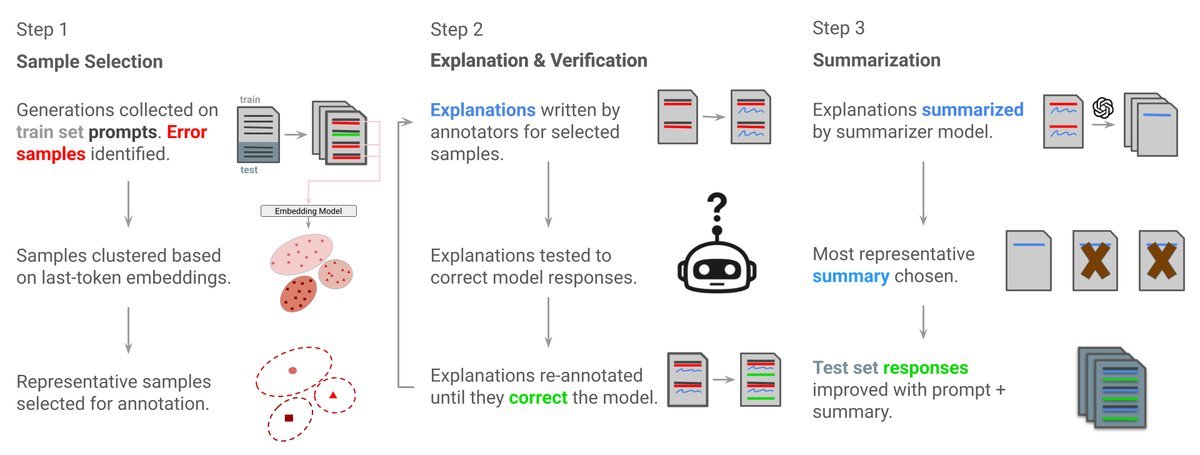
1. 挑错:基于聚类的样本选择
模型犯的错误千千万,我们不能全都修。FLEx 的策略是“抓典型”。
研究者首先收集模型在训练集上的错误输出,然后利用嵌入(Embedding)技术将这些错误进行 $k$-means 聚类。
-
为什么这么做? 这样可以将相似的错误归为一类(例如,都是因为没看清否定词,或者都是算术错误)。
-
选谁? 从每个聚类中选出最接近中心的那个错误作为代表。这样,我们只需要处理极少数(例如 10 个)样本,就能覆盖主要的错误模式。
2. 纠错:人工验证解释
找到了典型错误后,需要告诉模型“为什么错了”以及“怎么做才对”。
这里引入了“人在回路”(Human-in-the-loop):
-
标注者为选定的错误编写自然语言解释。
-
关键点:这些解释必须经过验证。也就是说,将这个解释喂给模型,如果模型能因此答对问题,这个解释才算合格;否则,标注者需要重写,直到模型“开窍”为止。
-
实验表明,这种验证机制至关重要,未经验证的解释甚至可能帮倒忙。
3. 总结:蒸馏出“通用心法”
这是 FLEx 最精髓的一步。如果我们直接把那 10 个具体的纠错案例塞进 Prompt,上下文会太长,且模型容易迷失在细节中。
FLEx 使用另一个 LLM(如 GPT-4o mini)作为总结者,将这些具体的纠错案例总结成一段通用的、抽象的提示前缀。
如何挑选最好的总结?
FLEx 生成多个候选总结,然后通过一种巧妙的 $\Delta$-embedding 机制来挑选最佳总结:
-
计算原解释对模型内部表示(Hidden States)的改变幅度 $\Delta_f$。
-
计算候选总结对模型内部表示的改变幅度 $\Delta_s$。
-
选择那个能产生与原解释最相似的“向量偏移”的总结。
简单来说,就是选出那个能起到与“手把手教”同样效果的“一句话总结”。
实验效果:以小博大
研究团队在 CounterBench(反事实鲁棒性)、GSM8K(数学推理)和 ReasonIF(指令遵循)三个数据集上进行了评估,涵盖了 Gemma 和 Qwen 等多个模型家族(从 0.5B 到 72B 参数)。
结果非常亮眼:
-
全面超越 CoT:在绝大多数设置下,FLEx 的表现都优于零样本思维链(Zero-shot CoT)。
-
消除顽固错误:这是最震撼的数据。在某些情况下,FLEx 能减少 CoT 遗留错误的 83%。这意味着它专门解决那些常规 Prompt 搞不定的硬骨头。
-
比 RAG 和 Self-Refine 更强:与检索增强(RAG)和自我修正(Self-Refine)等方法相比,FLEx 在大多数任务中表现更好,且不需要维护外部数据库或进行多轮推理。
-
模型越大,效果越好:虽然大模型本身准确率已经很高,但 FLEx 依然能显著降低其残留错误率。
为什么 FLEx 有效?
通过消融实验,论文揭示了几个关键洞察:
-
质量 > 数量:经过验证的解释(Verified Explanations)远比未经验证的解释有效。甚至只给正确答案(Solutions only)几乎没有帮助,模型需要的是“解释”。
-
抽象的力量:直接拼接所有解释(Raw concatenation)往往会导致性能下降,而经过总结(Summarization)后的 Prompt 具有更强的泛化能力。
-
跨模型迁移:更有趣的是,从一个模型(如 Gemma)上总结出来的 FLEx 前缀,直接拿给另一个模型(如 Qwen)用,依然有效!这说明 FLEx 捕捉到了某种通用的推理逻辑,而非特定模型的过拟合特征。
总结
FLEx 向我们展示了 LLM 优化的另一种可能:不需要昂贵的参数更新,也不需要复杂的检索系统,仅仅通过高质量的、经过验证的“错题集总结”,就能显著提升模型的推理的鲁棒性。
这不仅为资源受限的场景提供了一种高效的解决方案,也让我们看到,大模型其实很像人类学生——有时候,几句点拨要比海量的题海战术管用得多。