让Agent经验“活”起来:可训练图记忆,助小模型性能飙升25.8%!
LLM Agent无疑是当前AI领域最激动人心的方向之一,它们被寄予厚望,希望能在复杂开放的环境中自主解决问题。但现实是,许多Agent在决策时仍然显得“笨拙”:它们会重复犯错,行动效率低下,甚至无法完成任务。
论文标题:From Experience to Strategy: Empowering LLM Agents with Trainable Graph Memory ArXiv URL:http://arxiv.org/abs/2511.07800v1
究其原因,核心在于Agent没能有效地从过去的成败经验中学习。
当前的解决方案主要有两种:
- 隐式记忆:通过强化学习(RL)等方式将经验编码到模型参数中。但这像是在“闭门造车”,过程不透明,容易“灾难性遗忘”。
- 显式记忆:通过提示词(Prompting)直接给出经验案例。这虽然直观,但却是一种“死记硬背”,缺乏适应性和泛化能力。
有没有一种方法,既能让记忆透明可控,又能让它像大脑一样动态学习、自我进化?
最近一篇名为《From Experience to Strategy》的论文给出了答案。该研究提出了一种创新的可训练多层图记忆框架(Trainable, Multi-layered Graph Memory),它能将Agent的原始经验提炼为高阶策略,并通过强化学习动态优化,最终显著提升Agent的战略推理能力。
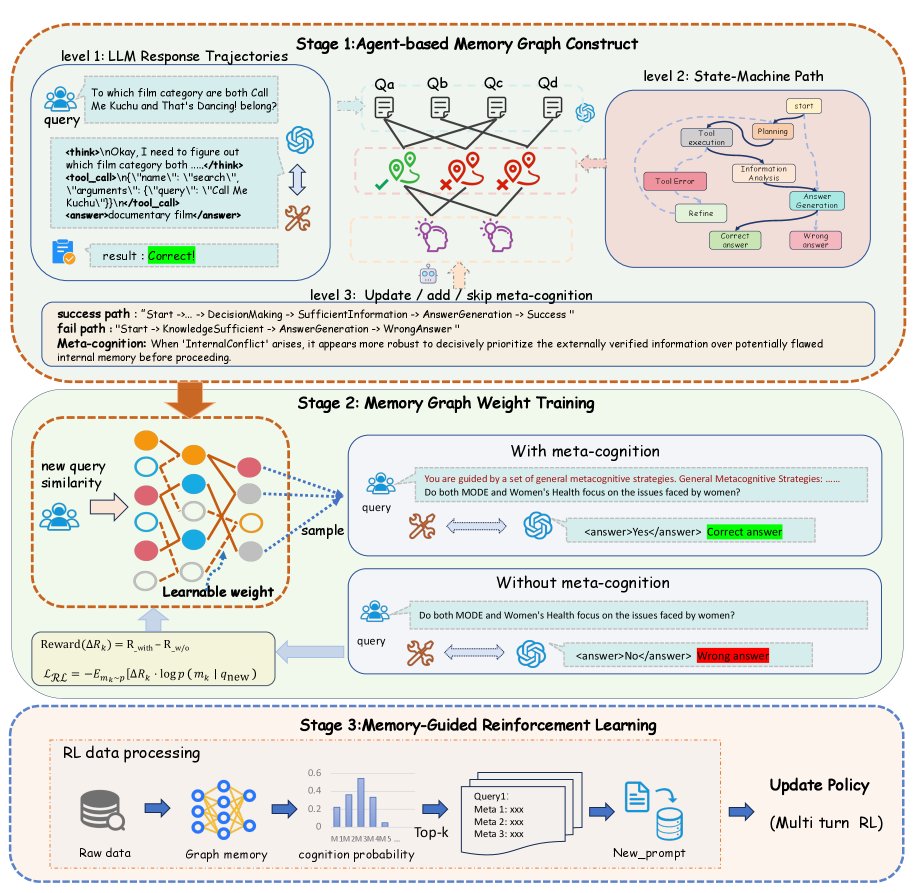 图1: 本文提出的可训练记忆框架:从轨迹中构建图(阶段1),用RL优化图权重(阶段2),再用优化后的记忆指导Agent训练(阶段3)。
图1: 本文提出的可训练记忆框架:从轨迹中构建图(阶段1),用RL优化图权重(阶段2),再用优化后的记忆指导Agent训练(阶段3)。
三步走:从原始经验到可学习的策略图
该框架的核心思想是将Agent的“经历”转化为可供学习和利用的“智慧”。整个过程分为三个阶段:
阶段一:构建分层记忆图谱
首先,需要把Agent凌乱的行动轨迹(trajectories)变得结构化。
-
轨迹抽象化:研究者设计了一个有限状态机(Finite State Machine, FSM)。这好比是把Agent杂乱无章的行动路线,标准化地映射到一张预设的“地铁图”上。无论具体路线如何,最终都会被归纳为几条标准化的“换乘路径”,例如从\(StrategyPlanning\)(策略规划)状态到\(InformationAnalysis\)(信息分析)状态。
-
策略(Meta-Cognition)归纳:通过对比成功和失败的标准化路径,LLM能自动归纳出高阶的、可解释的策略,称之为“元认知”(Meta-Cognition)。比如,通过对比发现,成功的路径总是“先用A工具再用B工具”,而失败的路径则是“直接使用B工具”,就能提炼出一条宝贵的策略。
-
构建图谱:最后,将“原始问题(Query)”、“标准化路径(Path)”和“元认知(Meta-Cognition)”作为三层节点,构建一个异构图。这形成了一个从具体问题到抽象策略的知识结构。
阶段二:用强化学习优化图权重
图谱建好了,但并非所有策略都同等重要。哪些策略是真正的“制胜法宝”?
这里引入了该框架最巧妙的设计:用强化学习来给策略“打分”。
具体来说,通过对比“使用某条策略”和“不使用该策略”两种情况下任务的奖励差异,可以计算出一个奖励差(Reward Gap)$ΔR_k$。
这个$ΔR_k$直接反映了该策略的实际效用。如果$ΔR_k$为正,说明这个策略很有用,系统就会通过策略梯度算法,增强图谱中通向这条策略的路径权重。反之,则削弱权重。
通过这种方式,记忆图谱不再是静态的,它能基于真实反馈,动态地“学会”哪些策略是真正有价值的。
阶段三:记忆引导的策略优化
一个“活”的、懂得自我优化的记忆图谱,如何反哺Agent的成长呢?
研究者将其无缝整合到了Agent的强化学习训练循环中。在训练时,对于每个新问题,系统会从记忆图谱中检索出最相关、权重最高的Top-k条“元认知”策略。
然后,将这些策略作为“专家建议”注入到原始问题的提示词中,形成一个增强版的输入:$\tilde{q}_{\text{train}}=\big[\,m_{1},m_{2},\dots,m_{k}\,;\;q_{\text{train}}\,\big]$。
Agent带着这些“锦囊妙计”去训练,其策略网络$π_θ$就能站在一个更高的起点上进行学习,从而大大提升训练效率和最终性能。
实验效果:小模型也能“逆袭”
纸上谈兵终觉浅。这套框架的实际效果如何?
研究者在7个主流的问答(QA)数据集上进行了广泛测试,结果令人印象深刻。
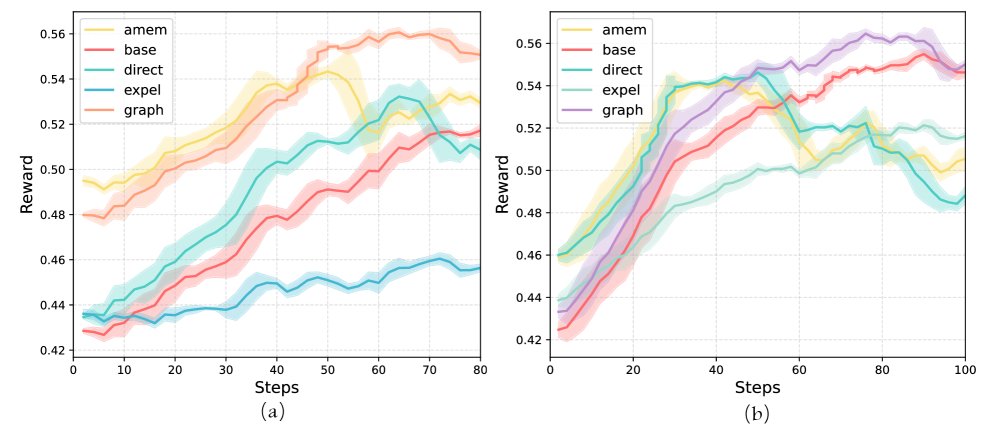 图2: 在多个QA数据集上的性能对比
图2: 在多个QA数据集上的性能对比
最亮眼的表现出现在小模型上。在4B参数规模的模型上,该方法相比基线取得了高达+25.8%的相对性能提升。这表明,这种结构化的外部记忆极大地弥补了小模型自身推理能力的不足,让小模型也能完成“逆袭”。
对于8B规模的模型,该方法同样实现了+9.3%的性能增益,在所有对比方法中排名第一,展现了强大的通用性和有效性。
模型无关的可插拔设计
为了验证该框架的通用性,研究者还进行了一项有趣的实验:用谷歌的Gemini-1.5-pro替换原本用于构建记忆图谱的GPT-4o,再进行下游任务评估。
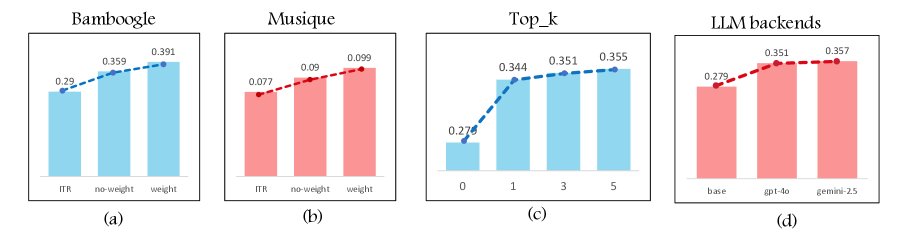 图3: 消融实验证明了可学习权重的重要性
图3: 消融实验证明了可学习权重的重要性
结果显示,即使更换了底层的LLM,这套记忆框架依然能稳定地带来性能提升。这证明了其设计的普适性,它并非某个特定模型的“专属外挂”,而是一种可以“即插即用”的通用增强模块。
结语
这项研究为我们展示了如何超越传统的隐式记忆和静态显式记忆,构建出一个既结构化、又具备动态学习能力的Agent记忆系统。它通过将经验抽象为策略、用RL评估策略价值、再用高价值策略指导Agent学习的闭环,成功地让Agent学会了“从经验到战略”的升华。
对于追求更智能、更高效的通用人工智能而言,教会Agent如何“学习去学习”,可能比单纯扩大模型规模更为关键。而这种可训练的图记忆,无疑是朝着这个方向迈出的坚实一步。