GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization
GRPO多奖励训练“失效”?GDPO解耦归一化:AIME准确率提升6.3%
随着 DeepSeek-R1 等模型的爆火,组相对策略优化(Group Relative Policy Optimization, GRPO)几乎成了强化学习(RL)微调的标配。大家都在用它来提升模型的推理能力。
ArXiv URL:http://arxiv.org/abs/2601.05242v1
但是,当你的需求不再单一,而是希望模型“既要准确,又要简练,还要格式规范”时,直接套用 GRPO 真的没问题吗?
来自香港科技大学和 NVIDIA 的研究团队给出了否定的答案。他们发现,在多奖励(Multi-reward)场景下,GRPO 存在一个严重的“奖励崩塌”(Reward Collapse)问题,可能导致训练失败。为此,他们提出了一种新的优化方法——GDPO,通过简单的“解耦归一化”策略,不仅解决了崩塌问题,还在数学推理任务(AIME)上带来了高达 6.3% 的准确率提升。
为什么 GRPO 在多奖励场景下会“崩塌”?
在实际应用中,我们往往希望模型同时满足多个目标。例如在“工具调用”任务中,我们既希望模型选对工具(准确性奖励),又希望它输出的 JSON 格式严丝合缝(格式奖励)。
通常的做法是将这些奖励加权求和,然后扔给 GRPO 去优化。然而,研究人员发现,这种“先求和、再归一化”的粗暴做法,会丢失大量信息。
让我们看一个直观的例子:
假设有两个奖励 $r_1$ 和 $r_2$。
-
情况 A:模型做得很好,两个奖励都很高。
-
情况 B:模型做得很差,两个奖励都很低。
-
情况 C:模型偏科,一个奖励极高,另一个极低。
在 GRPO 的机制下,它会先计算总奖励 $r_{\text{sum}}$,然后在组内计算优势(Advantage)。问题在于,不同的奖励组合(比如“高+低”和“中+中”)可能加起来的总分是一样的。
一旦总分一样,GRPO 归一化后的“优势值”就变得一模一样。这就导致模型无法区分“偏科”和“平庸”,训练信号的分辨率大幅下降。论文将这种现象称为奖励崩塌。这不仅导致收敛次优,严重时甚至会让训练直接失败。
GDPO:简单即是美,解耦归一化
为了解决这个问题,论文提出了 GDPO(Group reward-Decoupled Normalization Policy Optimization)。
GDPO 的核心思想非常直观:先各算各的账,最后再汇总。
与 GRPO 直接对“总分”进行归一化不同,GDPO 将归一化过程解耦了:
-
独立归一化:对于每一个单独的奖励信号(如准确性、格式、长度),先分别在组内进行归一化,计算出各自的优势 $A_1, A_2, \dots, A_n$。
-
求和:将这些归一化后的优势值相加,得到总优势 $A_{\text{sum}}$。
-
二次归一化:为了保证数值稳定性,最后再进行一次 Batch 级别的归一化。
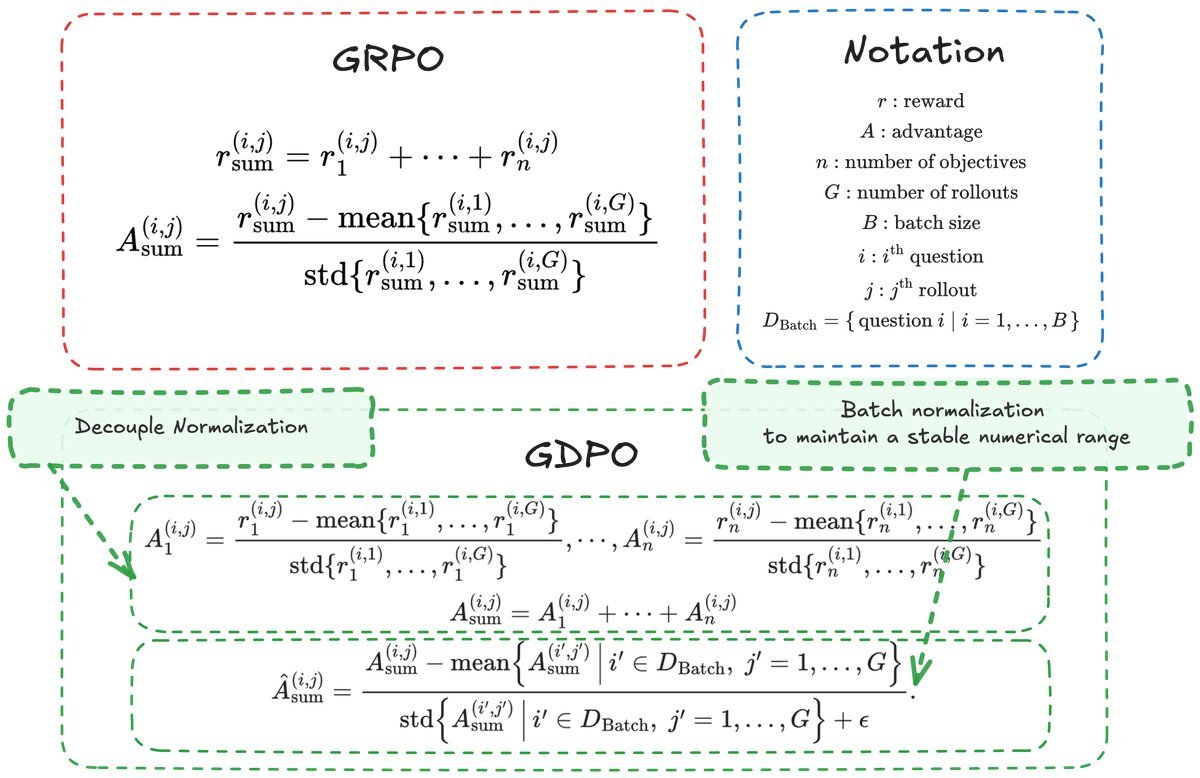
(a) GDPO 概览:对每个奖励单独进行组内归一化,保留了不同奖励分量的相对差异。
通过这种方式,GDPO 能够敏锐地捕捉到不同奖励分量的相对变化。即使两个样本的总分相同,如果它们的得分构成不同,GDPO 也能给出不同的梯度信号,从而引导模型走向更精细的优化方向。
实验验证:全面超越 GRPO
研究团队在工具调用、数学推理和代码推理三个截然不同的任务上对比了 GDPO 和 GRPO。
1. 工具调用(Tool Calling):格式与准确率双丰收
在工具调用任务中,模型需要同时优化“准确率”和“格式正确性”。
实验结果显示,使用 Qwen2.5-1.5B 模型时,GDPO 在 BFCL-v3 基准测试上的平均准确率比 GRPO 提升了约 2.7%,格式正确率提升了超过 4%。
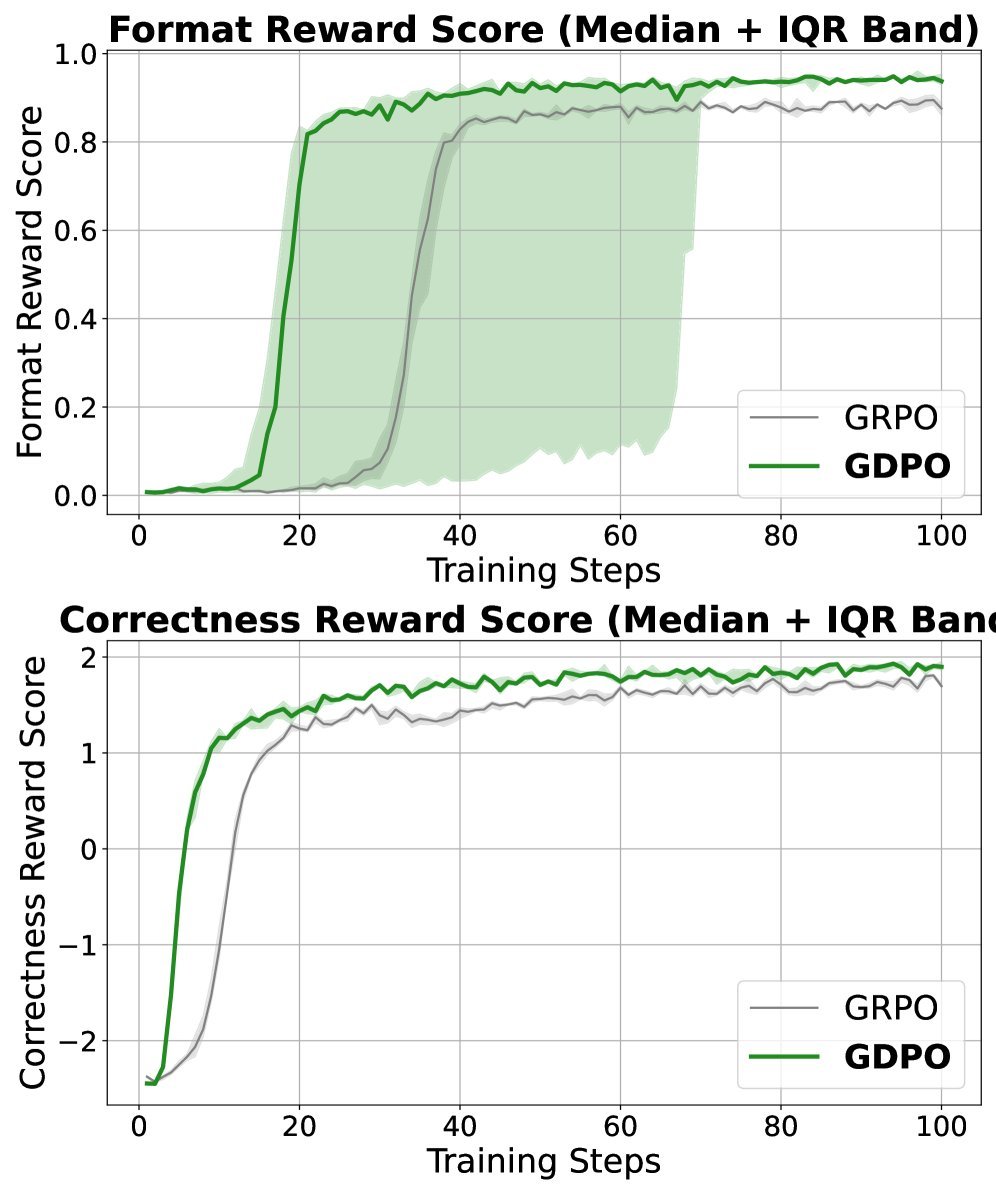
(b) 奖励趋势对比:GDPO(蓝色)在正确性和格式奖励上都比 GRPO(橙色)收敛得更好、更高。
2. 数学推理(Math Reasoning):既聪明又高效
这是目前最受关注的领域。研究者在 DeepScaleR-Preview 数据集上训练了 DeepSeek-R1-1.5B/7B 和 Qwen3-4B。目标是:提高解题准确率,同时限制回复长度(越简练越好)。
这是一个典型的“既要又要”的冲突场景。结果令人印象深刻:
-
DeepSeek-R1-1.5B:在 AIME 竞赛题上,GDPO 带来的准确率提升高达 6.7%。
-
DeepSeek-R1-7B:在 AIME 上提升了 2.9%,同时将“超长回复”的比例从 2.1% 压低到了 0.2%。
这说明 GDPO 不仅能让模型更聪明,还能更听话地遵守长度约束,实现了准确率与效率的完美平衡。
3. 代码推理(Coding):三目标优化
在更复杂的代码生成任务中,研究者引入了三个奖励:通过率(Pass)、长度约束(Length)和 Bug 率(Bug Ratio)。
即使面对三个目标的复杂权衡,GDPO 依然稳稳胜出,在保持高 Pass 率的同时,显著降低了 Bug 率和代码长度。
总结与启示
这篇论文给当前火热的 RL 微调泼了一盆清醒的冷水,也送来了一剂良药。它提醒我们:当我们在 RL 中引入多个奖励信号时,不要盲目照搬 GRPO。
GDPO 的成功证明了,在多目标优化中,保留每个目标的独立统计特性是至关重要的。如果你正在尝试复现 DeepSeek-R1 的效果,或者在做涉及多维度偏好对齐(如安全性+有用性)的 RLHF,GDPO 绝对是一个值得尝试的、更稳健的替代方案。
核心技术点回顾:
-
痛点:GRPO 在多奖励求和后归一化,导致不同行为产生相同的优势值(信号丢失)。
-
方案:GDPO 采用“先独立归一化,再求和”的策略。
-
效果:在工具调用、数学、代码任务上全面优于 GRPO,训练更稳定,指标更高。