AI记忆革命GAM:用“即时研究”取代静态压缩,长文本任务准确率超90%!

AI Agent的记忆力,正在成为其智能的瓶颈。
ArXiv URL:http://arxiv.org/abs/2511.18423v1
传统的记忆方法就像考前死记硬背,试图把所有知识都压缩进一个“小抄”里。这种方式不可避免地会丢失大量细节,导致AI在处理复杂任务时“失忆”。
如果AI能换一种方式记忆呢?它不再死记硬背,而是像一个顶级研究员,平时只记录关键索引,在需要时才去深度挖掘全部资料。
来自北智院、港理大和北大的研究者们提出了一个名为通用智能体记忆(General Agentic Memory, GAM)的全新框架,它正是基于这种“即时研究”的理念,彻底改变了AI的记忆模式。
抛弃“预编译”,拥抱“即时编译”
当前大多数AI记忆系统,遵循的是预编译(Ahead-of-Time, AOT)原则。
它们在离线阶段花费大量算力,将原始信息压缩成轻量级记忆。这种方法最大的问题是信息丢失,就像制作一份书的摘要,无论多详尽,都无法替代原书。
而GAM框架则借鉴了编程中的即时编译(Just-in-Time, JIT)思想。
它在离线时只做最轻量的工作,而在运行时(即需要回答问题时)才投入密集计算,为当前任务“深度研究”并生成一个定制化的、最高效的上下文。
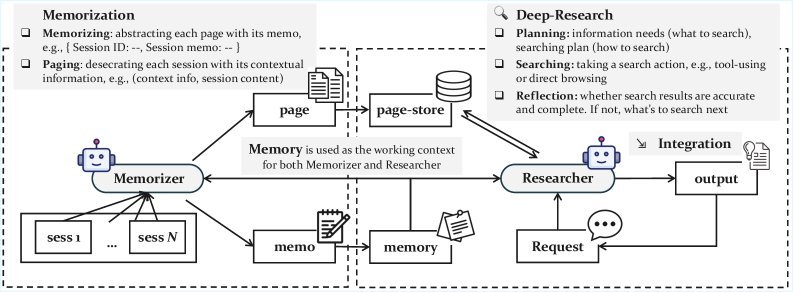
为了实现这一目标,GAM设计了一个优雅的“二人组”架构:记忆者(Memorizer)和研究者(Researcher)。
GAM的双智能体协同机制
GAM的核心是两个基于LLM的智能体,它们各司其职,高效协作。
1. 记忆者(Memorizer):离线档案管理员
当AI Agent的历史信息(如对话、操作记录)像数据流一样涌入时,“记忆者”开始工作。
它只做两件事:
-
提炼摘要:为新信息生成一个简洁的快照($memo$),并将其增量式地更新到一份轻量级的“记忆索引”($memory$)中。
-
无损归档:将原始信息和摘要一起打包成一个“页面”($page$),存入一个名为“页面库”($page-store$)的数据库中。
这个过程确保了所有历史信息都被无损保存,同时又有了一份能快速检索的索引。
2. 研究者(Researcher):在线深度侦探
当用户提出请求时,“研究者”登场。它不像传统方法那样只看摘要,而是基于“记忆索引”在“页面库”中展开一场“深度研究”。
这个研究过程是迭代进行的:
-
规划(Planning):首先分析用户请求,思考需要哪些信息,并制定一个详细的搜索计划。
-
检索与整合(Retrieve & Integrate):执行搜索计划,从页面库中检索相关页面,并整合信息。
-
反思(Reflection):审视已收集的信息是否足够回答问题。如果不够,它会生成新的研究方向($r’$),再次启动新一轮的规划、检索和整合,直到问题被完美解决。
这种“规划-检索-反思”的闭环,让GAM能够处理极其复杂、需要多步推理才能解决的问题。
实验效果:全面超越现有方法
那么,GAM的实际表现如何?研究者在多个主流的长文本和记忆基准测试(如HotpotQA, RULER, LoCoMo)上进行了验证。
结果令人印象深刻:
-
性能全面领先:GAM在所有测试中都显著优于包括传统RAG和长上下文LLM在内的所有基线方法。
-
攻克复杂推理:在需要多步追踪信息的RULER(MT)任务上,GAM的准确率超过了惊人的90%,而多数基线方法在此类任务上表现不佳。
-
对抗“上下文噪声”:实验发现,简单粗暴地扩大LLM的上下文窗口(如128K)并不能保证性能,过多的无关信息反而会造成“上下文腐烂”(context rot)现象,干扰模型判断。而GAM通过其精准的“研究”过程,有效避免了这个问题。
这些结果证明,GAM的“即时研究”范式远比静态压缩或无限扩展上下文窗口更为有效。
深入探究:GAM成功的关键
更强的“研究者”是关键
研究者发现,GAM的性能与“研究者”智能体的能力密切相关。当为“研究者”配备更强大的LLM(如从7B模型升级到32B)时,系统整体性能有显著提升。
有趣的是,“记忆者”对模型大小不那么敏感,即使使用小模型也能维持不错的性能。这说明,复杂的“研究”过程才是真正需要强大模型能力的地方。
更多的“思考时间”带来更好的结果
GAM的一个独特优势是其测试时可扩展性(test-time scalability)。这意味着在处理难题时,我们可以通过增加其“思考时间”来提升性能。
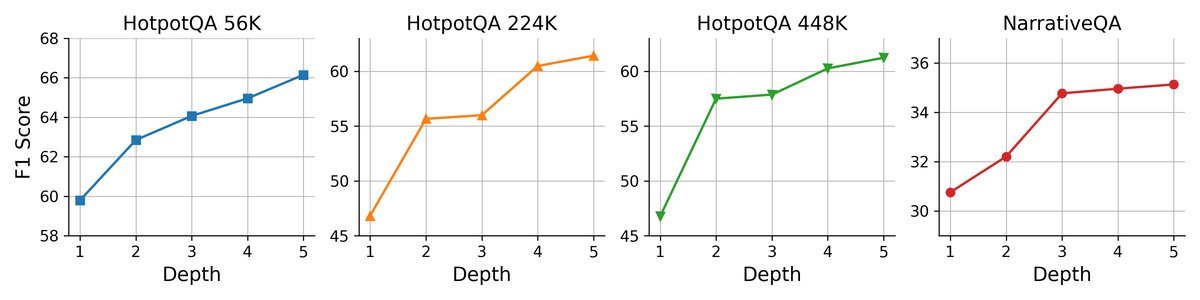
左图:增加反思深度(允许更多轮研究)
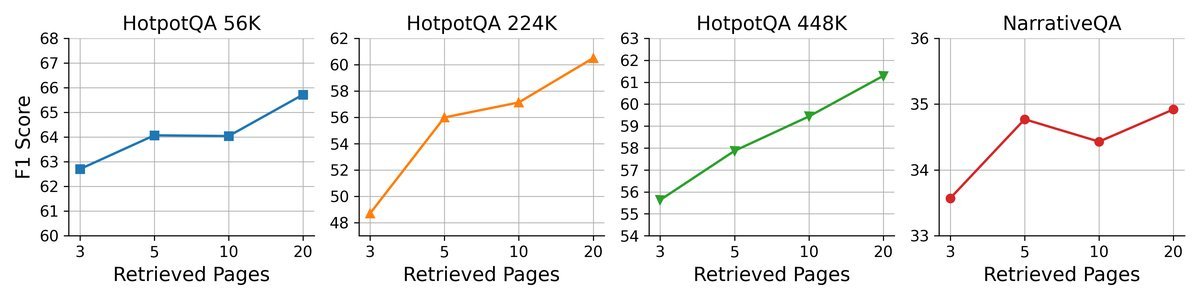
右图:增加单轮研究检索的页面数
实验表明,无论是增加“研究者”的反思深度(迭代次数),还是扩大每轮检索的页面数量,都能稳定地带来性能增益。这是传统固定流程方法所不具备的灵活性。
兼顾效率与效果
尽管引入了复杂的“深度研究”过程,GAM的整体效率依然非常具有竞争力。其在线服务响应时间与现有主流记忆系统相当,实现了性能与成本的最佳平衡。
结语
GAM框架为AI Agent的记忆问题提供了一个全新的、极具潜力的解决方案。
它摒弃了传统记忆系统“信息压缩”带来的固有缺陷,通过引入“记忆者”和“研究者”的双智能体协同机制,将记忆过程从静态的、有损的“预编译”转变为动态的、无损的“即时研究”。
这不仅让AI Agent能够更精准、更深入地利用其全部历史知识,也为未来构建更强大、更通用的AI智能体铺平了道路。或许,真正智能的AI,其秘诀不在于能记住多少,而在于“知道去哪里寻找”。