Meta重塑推荐系统:GESR用“混合注意力”打破双塔模型瓶颈,性能大涨延迟仅增10%

你的信息流App背后,藏着一场效率与效果的持续博弈。经典的“双塔模型”因其高效而称霸多年,但它真的懂你吗?
ArXiv URL:http://arxiv.org/abs/2511.21095v1
最近,Meta的研究者们给出了一个颠覆性的答案:生成式早期排序(Generative Early Stage Ranking, GESR)。
这项技术不仅显著提升了推荐系统的核心指标,更在严苛的工业级延迟要求下,成功部署了复杂的注意力机制。
这可能是继双塔模型之后,推荐系统架构的又一次重要进化。
双塔模型的“天花板”
在推荐系统的多阶段排序流程中,早期排序(Early Stage Ranking, ESR)扮演着关键的承上启下角色。
它需要从海量的召回物品中,快速筛选出几百个高质量的候选,送给后续更精细的排序模型。
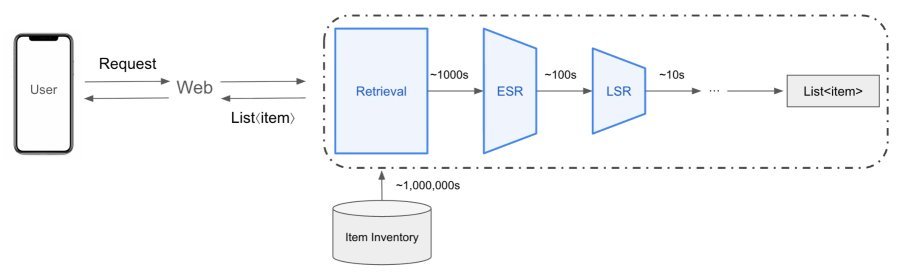
为了平衡效率和效果,工业界普遍采用“用户-物品解耦”的双塔架构。
用户塔和物品塔各自独立计算,最后仅通过一个简单的点积来预测兴趣。这种设计可以预先计算好所有物品的Embedding并缓存,线上服务时只需计算用户Embedding,速度极快。
但代价是惨痛的:模型无法捕捉用户和物品之间细粒度的交叉特征。
比如,你最近在看科幻电影,系统给你推了一部科幻小说。双塔模型很难在早期就理解这种“科幻”主题的跨领域关联。
GESR的核心:混合注意力(MoA)
为了打破这一瓶颈,GESR没有抛弃双塔,而是在其旁边并联了一个强大的新模块:混合注意力(Mixture of Attention, MoA)。
这个模块不再让用户和物品“分居”,而是让它们在编码阶段就进行充分的互动。
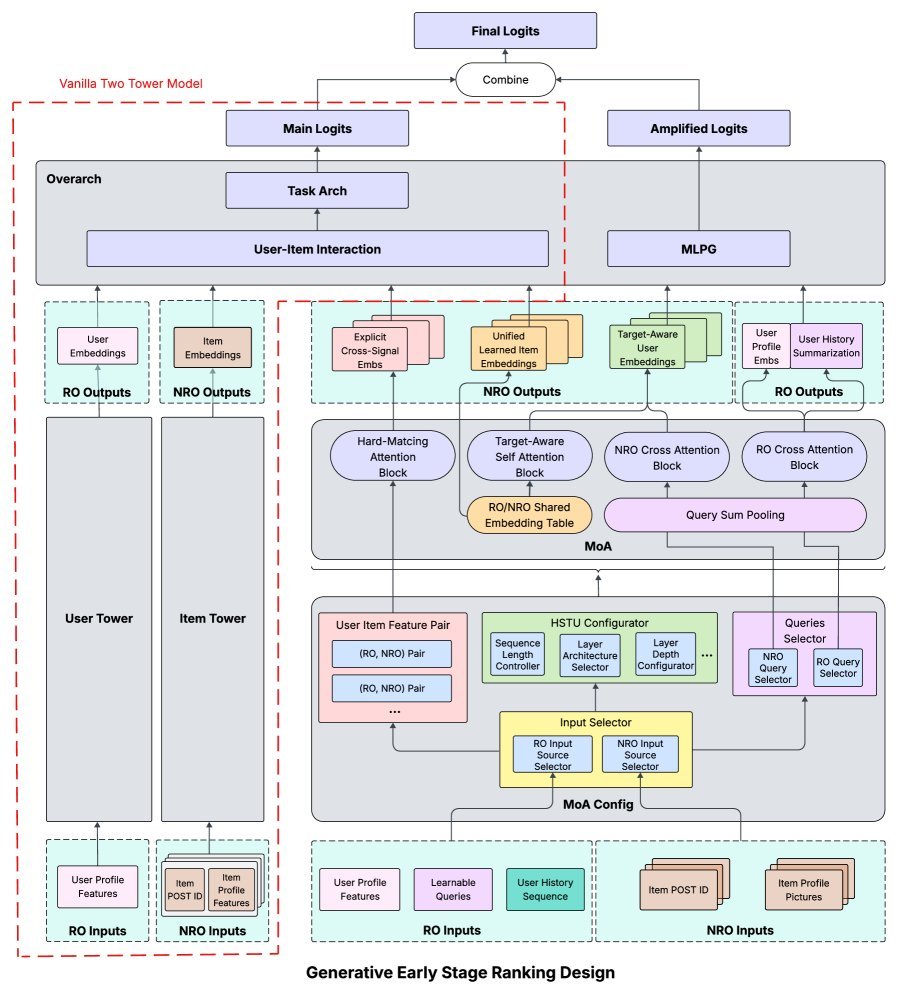
MoA模块像一个“特征融合大师”,内部包含了多种精心设计的注意力机制:
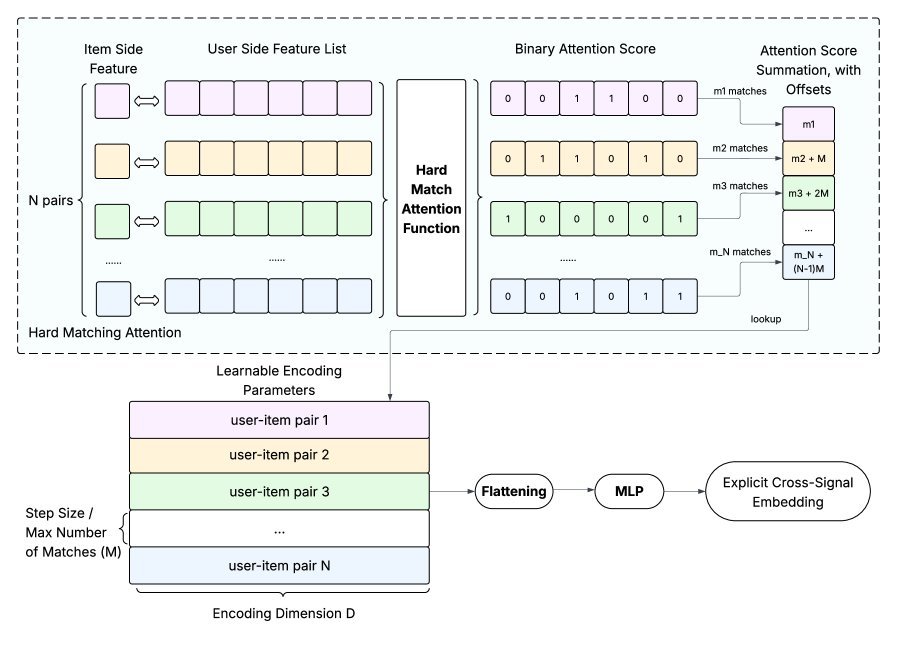
1. 硬核匹配:硬匹配注意力(HMA)
HMA模块的思路堪称简单粗暴但有效:它直接计算用户历史行为特征和候选物品特征之间的“匹配项”数量。
比如,用户看过的10个视频里有3个和候选视频属于同一作者,HMA就会捕捉到这个“3”的信号。
这种方式直接编码了显性的交叉信号,轻量且可解释性强。
2. 深度理解:目标感知自注意力
为了捕捉更深层次的语义关联,GESR引入了目标感知自注意力(Target-Aware Self Attention)。
它将候选物品的信息融入到对用户历史行为序列的理解中。
这意味着,在分析你的历史兴趣时,模型会“带着问题去看”:用户对 这个特定的候选物品 会感兴趣吗?
这使得用户表征更具个性化和上下文感知能力。
3. 效率补充:交叉注意力
自注意力虽好,但计算复杂度是序列长度的平方,对于长历史序列是个挑战。
因此,GESR还引入了交叉注意力(Cross Attention)模块。
它的计算复杂度与序列长度呈线性关系,能以更低的成本实现用户和物品信息的对称交互,为模型提供更丰富的融合信号。
点睛之笔:多Logit参数化门控(MLPG)
有了MoA模块产出的丰富交叉特征,如何最有效地利用它们呢?
GESR设计了多Logit参数化门控(Multi-Logit Parameterized Gating, MLPG)机制。
它不再是简单地将所有特征拼接后计算一个最终得分(Logit),而是并行计算多个独立的$Logit_k$。
更关键的是,它引入了门控机制,让模型动态地、有选择地放大或缩小不同特征维度的重要性,实现一种特征级别的注意力。
这确保了从MoA中辛苦学来的宝贵信号,能在最终打分时发挥最大价值。
性能保障:从FP8到编译器优化
在早期排序阶段引入如此复杂的注意力模型,最大的挑战无疑是延迟。
Meta的工程师们为此祭出了一套组合拳:
-
FP8量化:在不重新训练的情况下,将大线性层的参数量化为8位浮点数,显著降低内存和计算开销。
-
Torch Inductor优化:利用编译器技术对计算图进行深度优化,实现算子融合和内存复用,生成高效的底层内核。
-
高效服务架构:通过优化的缓存机制,在服务时高效获取物品特征,最大限度减少在线计算量。
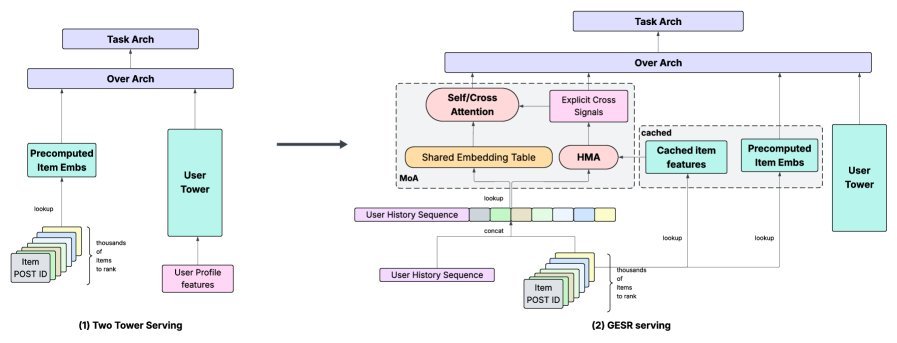
最终结果令人惊艳:在模型效果大幅提升的同时,GESR(高级版)的QPS(每秒查询率)仅下降了不到10%,完全满足了线上服务的严苛要求。
实验效果:线上线下双丰收
无论是在离线评估(更低的NE意味着更高的预测准确性)还是在线A/B测试中,GESR都取得了显著的成功。
它不仅提升了推荐系统的核心顶层指标,还在用户参与度和消费任务上带来了明显增益。
该研究也因此成为在如此大规模的早期排序阶段,首次成功部署完整目标感知注意力序列建模的案例。
结语
GESR的成功表明,在推荐系统的早期阶段引入更丰富的用户-物品交叉互动,是打破当前“效率-效果”困境的关键。
它没有完全颠覆成熟的双塔范式,而是通过一个巧妙的“并联”升级,在保持效率的同时,极大地释放了模型的表达能力。
这项工作不仅为大规模推荐系统的设计提供了新思路,也预示着,未来我们手机里的信息流,将变得更加“懂你”。