GUI-360: A Comprehensive Dataset and Benchmark for Computer-Using Agents
-
ArXiv URL: http://arxiv.org/abs/2511.04307v1
-
作者: Qianhui Wu; Bo Qiao; Kartik Mathur; Chaoyun Zhang; Liqun Li; Yuhang Xie; Qingwei Lin; Jian Mu; Si Qin; Xiaojun Ma; 等17人
-
发布机构: Microsoft; Nanjing University; Peking University; University of Illinois at Urbana-Champaign; Zhejiang University
TL;DR
本文提出 GUI-360,一个用于推进桌面级计算机使用智能体(CUA)的大规模、综合性数据集与基准测试套件,它通过一个由 LLM 增强的高度自动化流程构建,旨在解决真实世界任务稀缺、数据收集标注困难、以及缺乏统一基准的三大挑战。
关键定义
- 计算机使用智能体 (Computer-Using Agents, CUAs):在桌面计算机环境中操作的智能体。与网页或移动智能体不同,它们需要处理高分辨率屏幕、异构控件、任意窗口布局,并执行更长、更复杂的组合任务。
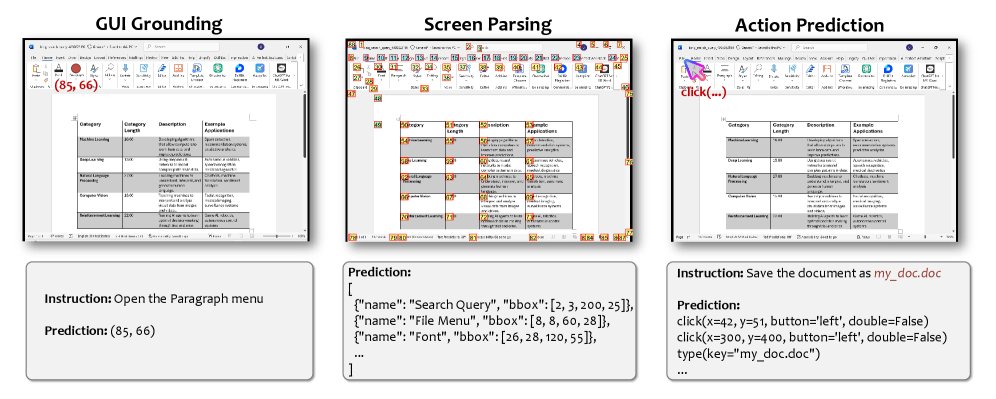
- GUI 接地 (GUI Grounding):一项核心任务,指在给定一个步骤级计划的情况下,预测屏幕上要交互的 UI 元素的坐标或标识。
- 屏幕解析 (Screen Parsing):一项核心任务,指在给定屏幕截图的情况下,枚举出所有可交互 UI 元素的集合及其属性(如名称、类型、位置)。
- 动作预测 (Action Prediction):一项核心任务,指在给定当前状态(如屏幕截图)和用户意图的情况下,预测智能体下一步应执行的动作(如点击、输入、选择或调用 API)。
- TrajAgent:本文设计的一种专用计算机使用智能体,用于自动化、一致性地执行任务并收集详细的轨迹数据。它采用多智能体协同架构,能够高效、保真地生成支持多任务监督的数据。
相关工作
当前,在大型语言模型(LLM)的推动下,能够跨网页、移动和桌面平台自动执行任务的智能体发展迅速。其中,桌面环境因其高分辨率显示、复杂布局和异构控件,对 CUA 构成了独特的挑战。现有智能体通常依赖可访问性元数据或视觉屏幕理解来与 GUI 交互。
尽管该领域兴趣日增,但进展却受限于三大瓶颈:
- 真实世界任务稀缺:现有数据集多为人工制作或由 LLM 合成,难以捕捉真实用户意图的频率和多样性。
- 自动化数据收集流程缺失:手动执行和标注桌面交互成本高昂、易出错且难以规模化,阻碍了大规模多模态轨迹数据的生成。
- 缺乏统一基准:此前的基准测试通常只关注单一任务(如元素检测)或特定应用,无法对 GUI 接地、屏幕解析和动作预测等核心能力进行综合评估。
本文提出的 GUI-360 旨在解决上述问题,通过提供一个大规模、可扩展、覆盖多种核心任务的数据集和基准,推动桌面 CUA 的研究。
下表比较了 GUI-360 与现有 GUI 数据集在关键维度上的差异。GUI-360 是首个同时包含可访问性信息、推理监督以及 GUI 和 API 级别动作的数据集,使其成为 CUA 研究领域一个独特且全面的基准。
各 GUI 数据集维度对比
| 数据集 | 任务多样性 | 模态 | 规模 | 自动化收集 | 可访问性元数据 | 推理监督 | GUI+API动作 |
|---|---|---|---|---|---|---|---|
| Mind2Web | 网页 | 文本, HTML, 截图 | 大 | ✅ | ✅ | ❌ | ❌ |
| AITW | 网页 | 文本, DOM, 截图 | 大 | ❌ | ✅ | ❌ | ❌ |
| WebArena | 网页 | 文本, HTML | 中 | ✅ | ✅ | ❌ | ✅ |
| Screen2Words | 安卓 | 截图 | 中 | ✅ | ✅ | ❌ | ❌ |
| MoTIE | 安卓 | 截图 | 中 | ✅ | ✅ | ❌ | ❌ |
| UI-Vision | 桌面 | 截图 | 小 | ❌ | ❌ | ❌ | ❌ |
| DeskVision | 桌面 | 截图 | 小 | ❌ | ❌ | ❌ | ❌ |
| OfficeBench | 桌面 | 截图 | 中 | ❌ | ❌ | ❌ | ✅ |
| GUI-360 (本文) | 桌面 | 截图 | 大 | ✅ | ✅ | ✅ | ✅ |
本文方法
本文提出一个名为 GUI-360 的综合数据集与基准套件,其构建过程遵循一个旨在最大化可扩展性并最小化人工投入的三阶段自动化流程。
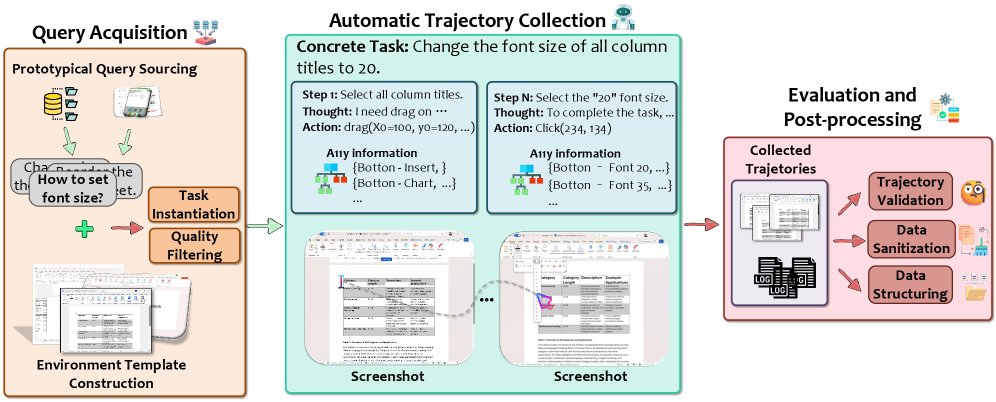
- 查询获取:从真实世界来源(如应用内帮助、在线论坛、搜索引擎)收集用户查询,并进行增强,以确保任务意图的真实性和多样性。
- 自动轨迹收集:设计专用智能体 \(TrajAgent\) 自动执行任务,并记录详细的执行轨迹,包括高分辨率截图、可访问性元数据、动作序列等,单次执行即可为所有下游任务生成数据。
- 评估与后处理:应用自动化评估器和系统性后处理来验证轨迹的正确性,过滤噪声,并增强整体数据质量。
查询获取
高质量的用户查询是构建可靠数据集的基础,它决定了任务的真实感和执行保真度。本文设计了一个四阶段的查询获取流程:
- 原型查询来源:从应用内帮助文档、在线社区问答和搜索引擎日志中挖掘高频、真实的用户任务描述,以平衡任务的规范性和真实性。
各应用和来源的原始查询统计
| 来源 | Word | Excel | PowerPoint |
|---|---|---|---|
| 应用内 | 274 | 159 | 316 |
| 在线 | 1,914 | 3,393 | 1,701 |
| 搜索 | 25,715 | 25,000 | 19,681 |
| 总计 | 27,903 | 28,552 | 21,698 |
-
环境模板构建:为避免给每个查询单独创建环境,本文引入了环境模板。利用 GPT 分析查询的上下文需求(如需要文本、表格或图像),将需求相似的查询聚类,并抽象成环境模板描述。通过手动实例化一小部分高频模板(Word 30个,Excel 30个,PowerPoint 6个),覆盖了约80%的原型查询,极大地降低了工作量。
-
任务实例化:将从真实世界收集的模糊查询(如“加粗文本”)转化为在特定环境中可执行的具体指令(如“将文档第一行文本设为粗体”)。此过程利用 LLM 自动完成:首先将查询与最匹配的环境模板配对,然后 LLM 将模糊查询改写为与该环境绑定的、无歧义的可执行任务。
-
质量过滤:利用一个基于 LLM 的判断器,根据一系列明确的约束条件自动过滤不合格的任务。过滤规则包括:
- 非可操作性指令:移除模糊或主观的陈述。
- 外部应用依赖:排除需要与目标应用之外的其他软件(如Edge、文件浏览器)交互的任务。
- 版本管理任务:排除检查、更新或修改应用版本的任务。
- 缺失文档模板:排除依赖当前环境中不存在的特定文档或工作区模板的任务。
- 其他无效情况:排除不相关、信息不足或因其他原因无法执行的任务。
过滤后各应用任务类别分布(百分比)
| 类别 | Word | Excel | PowerPoint |
|---|---|---|---|
| 非可操作性指令 | 15.61% | 13.27% | 12.13% |
| 外部应用依赖 | 2.93% | 4.18% | 7.51% |
| 版本管理任务 | 1.56% | 1.68% | 3.65% |
| 缺失文档模板 | 0.17% | 0.13% | 0.27% |
| 其他无效情况 | 2.70% | 6.98% | 1.46% |
| 有效任务 | 77.02% | 73.76% | 74.97% |
经过此流程,最终保留了 75.3% 的高质量、可执行任务,为后续轨迹收集奠定了坚实基础。
自动轨迹收集
为实现大规模、高保真的轨迹数据收集,本文设计并实现了一个名为 \(TrajAgent\) 的自动化执行框架。
TrajAgent 设计
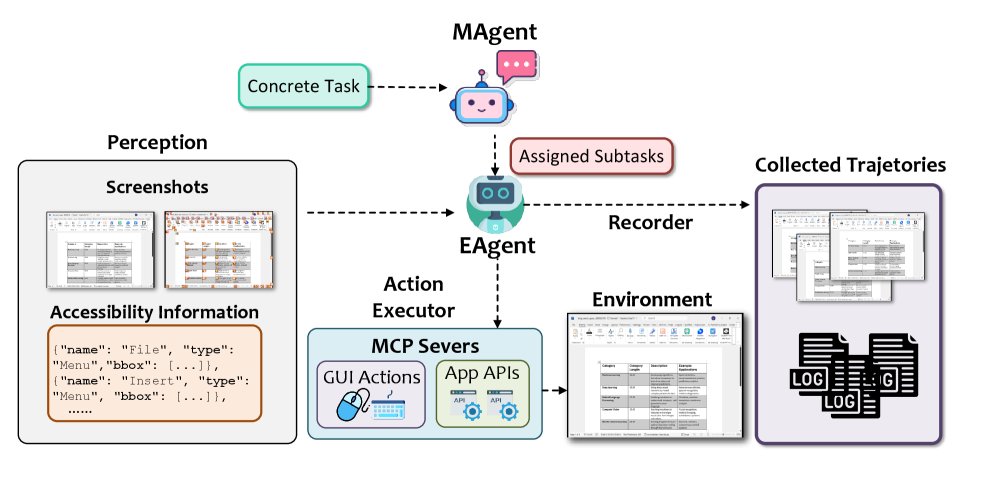
\(TrajAgent\) 采用多智能体协同架构,确保高成功率和高保真度的数据记录。
- 架构概览:由一个主智能体 (MAgent)、一个执行智能体 (EAgent) 池以及多个辅助服务(感知、动作执行器和记录器)组成。\(MAgent\) 负责接收任务并将其分解为子任务,分派给 \(EAgent\) 执行。\(EAgent\) 则在 \(ReAct\) 范式下循环执行感知-推理-行动,直至任务完成。
- 感知 (Perception):\(EAgent\) 在每个决策步骤捕获全分辨率屏幕截图,并调用 Windows 可访问性 API 提取可操作控件的元数据(名称、类型、边界框)。这些元数据会以标记集 (Set-of-Mark, SoM) 的形式呈现在截图上,为智能体决策提供视觉与语义双重信息。
- 动作执行器 (Action Executor):提供一套可扩展的工具集,不仅支持传统的 GUI 动作(鼠标点击、键盘输入),还集成了应用级 API 动作。这种混合动作空间提高了任务效率,并为 GUI 交互失败时提供了可靠的备用方案。
- 记录器 (Recorder):负责在每个执行步骤收集所有多模态信息,包括截图、可访问性元数据和智能体输出,确保单次执行即可生成支持所有下游任务的数据。
下游任务的数据输入输出规格
| 任务 | 输入 | 输出 |
|---|---|---|
| GUI 接地 | 指令, 截图, UI元素列表 | 目标UI元素的包围盒 |
| 屏幕解析 | 截图 | 所有可交互UI元素的包围盒、类型与名称 |
| 动作预测 | 指令, 截图, (可选的UI元素列表) | 下一步动作(类型及参数) |
两阶段执行策略
为了提高任务成功率并减少对单一模型的依赖,本文采用两阶段执行策略。首先使用 GPT-4o 模型执行所有任务,对于失败的任务,再使用能力更强的 GPT-4.1 模型进行第二轮尝试。
两阶段执行策略在各应用上的成功率
| 阶段 | Word | Excel | PowerPoint | 总计 |
|---|---|---|---|---|
| 第1轮 (GPT-4o) | 16.65% | 9.27% | 8.00% | 11.63% |
| 第2轮 (GPT-4.1) | 16.03% | 18.20% | 14.91% | 16.38% |
| 整体 | 30.50% | 25.78% | 21.71% | 26.09% |
如表所示,该策略将整体成功率提升至 26.09%,证明了级联不同能力的模型可以有效提高数据收集的覆盖面和效率。
评估与后处理
为确保最终数据集的质量,收集到的轨迹会经过一个三阶段的后处理程序:
- 轨迹验证:设计了一个名为 \(EvaAgent\) 的评估智能体(基于 GPT-4.1),以“LLM-as-a-judge”的模式自动验证每条轨迹。\(EvaAgent\) 通过思维链推理,将原始查询分解为细粒度的评估标准,并逐一检查轨迹。只有满足所有标准的轨迹才被标记为成功。在100个样本的人工评估中,\(EvaAgent\) 的判断与人类标注员的一致性达到 86%,证明了其评估的可靠性和可扩展性。
- 数据清洗:移除所有缺少执行动作、截图或基本元数据的步骤,以确保数据完整性和一致性。
- 数据结构化:将清洗后的数据转换为标准的 JSON 格式,以适配模型训练和评测的需求。特别地,对于动作预测任务,提供了两种输入模态:\(only-screenshot\)(仅截图)和 \(screenshot+A11Y\)(截图+可访问性信息),后者通过提供元素ID和名称来降低视觉接地的难度。
最终,数据被划分为 80% 的训练集和 20% 的基准测试集(GUI-360-Bench),所有三项任务共享相同的数据划分,以保证评估的一致性。
实验结论
本文利用 GUI-360 数据集对当前最先进的视觉语言模型 (VLM) 进行了基准测试,旨在回答两个核心问题:(1) 现有模型在未经适配的情况下处理真实桌面 CUA 任务的能力如何?(2) 在 GUI-360 上进行微调能在多大程度上弥补性能差距?
实验结果揭示了一致的模式:
- 现有模型泛化能力不足:未经微调的(off-the-shelf)SOTA 模型在处理桌面环境时表现不佳。它们在异构布局中的 GUI 接地 任务上普遍存在困难,并且在 动作预测 任务中频繁失败,导致错误累积,难以完成长序列任务。
- 微调效果显著:在 GUI-360 数据集上进行监督式微调或强化学习后,模型的性能得到了显著提升。这证明了 GUI-360 数据集的有效性,它能够帮助模型学习桌面环境的复杂交互模式。
- 与人类水平仍有差距:尽管微调带来了巨大进步,但模型的可靠性仍未达到人类水平,尤其是在处理需要复杂推理和长期规划的任务时。
最终结论是,当前的 VLM 在成为可靠的桌面 CUA 方面仍存在显著差距,而 GUI-360 作为一个具有挑战性、可扩展且内容全面的基准,为衡量和推动该领域的未来进展提供了宝贵的资源。