Hindsight is 20/20: Building Agent Memory that Retains, Recalls, and Reflects
准确率飙升至91%!Hindsight:让20B模型记忆力超越GPT-4o

目前的AI Agent(智能体)记忆系统存在一个致命缺陷:它们大多只是简单的“搬运工”。现有的架构通常将记忆视为一个外部的向量数据库,通过检索增强生成(Retrieval-Augmented Generation, RAG)提取片段塞进Prompt里。这种做法虽然能缓解“健忘”问题,但Agent无法区分“客观事实”与“主观推论”,难以在长周期内组织信息,更无法像人类一样随着经历改变观点。
ArXiv URL:http://arxiv.org/abs/2512.12818v1
针对这一痛点,一项名为 Hindsight 的全新记忆架构横空出世。它不再把记忆仅仅当作外挂硬盘,而是将其构建为一个结构化的、支持推理的一等公民。在LongMemEval基准测试中,搭载Hindsight的开源20B模型将准确率从39%惊人地提升到了83.6%,甚至在长窗口任务上击败了全上下文的GPT-4o。
告别“扁平化”记忆:Hindsight的核心理念
Hindsight的设计哲学在于:记忆不应是一堆杂乱无章的文本片段,而应该是一个有组织的认知结构。该研究提出将Agent的记忆划分为四个逻辑网络,并由三个核心操作来驱动。
四大逻辑网络(The Four Networks)
Hindsight并没有把所有信息混在一起,而是像人类大脑一样进行了分区存储:
-
世界知识(World Facts):关于外部世界的客观事实。
-
个人经历(Agent Experiences):Agent自身的经历和行为记录。
-
实体观察(Synthesized Entity Summaries):对人、事、物的客观总结(Observation)。
-
演变信念(Evolving Beliefs):Agent的主观观点和信念(Opinion),这部分带有置信度,并且会随着新证据的出现而改变。
这种划分解决了当前系统最大的痛点:认知清晰度(Epistemic Clarity)。Agent终于能分清“我看到了什么”和“我相信什么”。
三大核心操作
为了管理这些网络,Hindsight定义了三个原语操作:
-
Retain(保留):将对话流转化为结构化的记忆。
-
Recall(回忆):根据当前需求检索相关记忆。
-
Reflect(反思):基于记忆进行推理,回答问题,并更新信念。
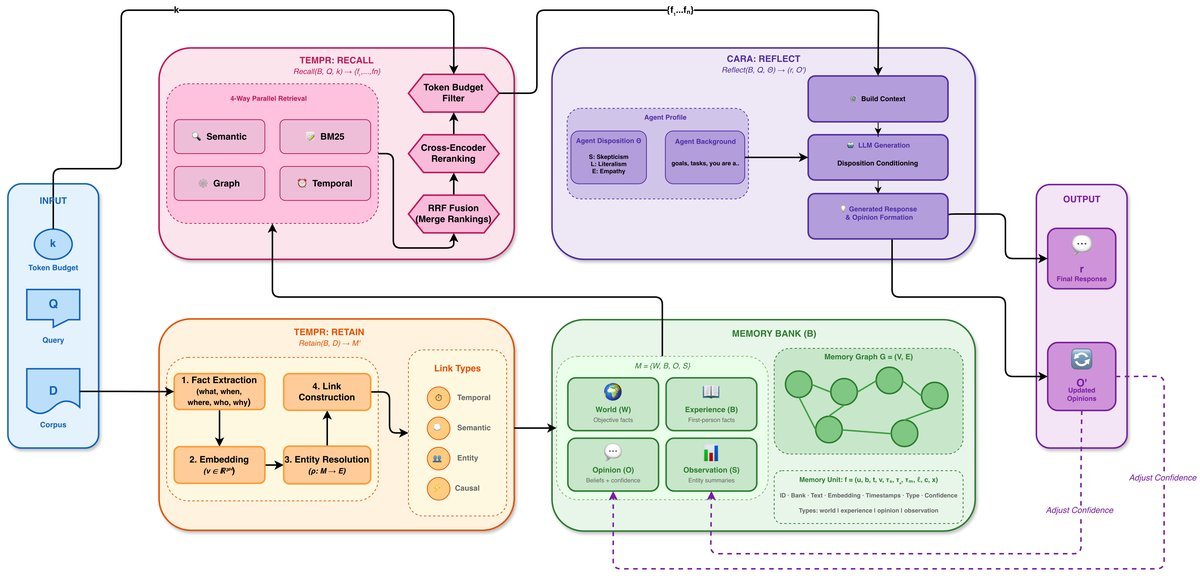
TEMPR:构建时空感知的记忆图谱
Hindsight的底层引擎被称为 TEMPR (Temporal Entity Memory Priming Retrieval),它负责“Retain”和“Recall”操作。
1. 叙事性事实提取(Narrative Fact Extraction)
传统的RAG系统通常按固定长度切分文本(Chunking),导致语义破碎。TEMPR则利用LLM将对话转化为“叙事性事实”。它不是存储零散的句子,而是提取包含时间范围、参与者、实体关系的完整事实单元 $f$:
\[f=(u,b,t,v,\tau\_{s},\tau\_{e},\tau\_{m},\ell,c,x)\]其中包含了时间戳($\tau$)、事实类型($\ell$)等元数据。
2. 实体解析与图谱构建
TEMPR会自动识别记忆中的实体(如人名、地点),并通过算法解决指代消歧问题。如果两条记忆都提到了“Alice”,它们之间就会建立一条实体链接。此外,系统还会根据时间邻近性、语义相似性和因果关系建立链接,形成一个复杂的记忆图谱 $\mathcal{G}=(V,E)$。
3. 代理优化的四路并行检索
在“Recall”阶段,TEMPR不再只依赖单一的向量搜索,而是采用了四路并行策略:
-
语义检索(Semantic):基于向量相似度,捕捉概念匹配。
-
关键词检索(BM25):基于倒排索引,精确匹配专有名词。
-
图检索(Graph):利用“激活扩散”算法,在记忆图谱上游走,发现间接相关的信息。
-
时间检索(Temporal):根据时间元数据过滤和排序。
这种组合拳确保了Agent既能通过模糊语义找到线索,也能通过精确的实体关系挖掘出深层背景。
CARA:带有个性的推理引擎
如果说TEMPR是海马体,那么 CARA (Coherent Adaptive Reasoning Agents) 就是前额叶皮层,它负责“Reflect”操作。
CARA不仅仅是回答问题,它引入了性格配置(Disposition Behavioral Parameters),包含怀疑度(Skepticism)、字面度(Literalism)和同理心(Empathy)。这意味着同一个问题,不同性格设定的Agent会给出风格迥异但逻辑自洽的回答。
更重要的是,CARA维护了一个动态意见网络。当新的证据出现时,它会通过强化机制更新观点的置信度 $c$。这让Agent拥有了“成长”的能力——它的看法不再是一成不变的,而是随着经历动态演化的。
实验结果:小模型的大逆袭
研究团队在 LongMemEval 和 LoCoMo 等长周期对话记忆基准上进行了测试,结果令人印象深刻。
-
准确率飞跃:在使用开源的20B模型作为基座时,Hindsight将LongMemEval的整体准确率从全上下文基线的39.0%提升到了83.6%。
-
超越GPT-4o:在同等条件下,Hindsight加持的20B模型表现优于拥有全上下文窗口的GPT-4o。
-
扩展性强:当进一步扩展基座模型规模时,Hindsight在LongMemEval上达到了91.4%的准确率,在LoCoMo上达到了89.61%,远超之前最强的开源系统(75.78%)。
总结
Hindsight通过将记忆结构化、区分事实与观点,并引入时空图谱和性格参数,为构建长期共存的AI伙伴提供了一套强有力的架构。它证明了,通过精巧的记忆设计,即使是参数量较小的模型,也能在长程推理和个性化一致性上展现出超越顶尖大模型的潜力。这或许预示着,未来的Agent竞争,将从“拼模型参数”转向“拼记忆架构”。