How and Why LLMs Generalize: A Fine-Grained Analysis of LLM Reasoning from Cognitive Behaviors to Low-Level Patterns
SFT正在“毁掉”泛化能力?5大原子技能揭示RL为何是推理的未来

DeepSeek-R1 和 OpenAI-o1 的横空出世,让整个 AI 社区达成了一个新共识:强化学习(Reinforcement Learning, RL) 才是通往高阶推理的必经之路。
ArXiv URL:http://arxiv.org/abs/2512.24063v1
但你是否思考过这样一个反直觉的现象:为什么经过海量数据“喂养”的 监督微调(Supervised Fine-Tuning, SFT) 模型,往往在特定任务上表现出色,但一换个场景(比如从数学题换到物理题)就“智商掉线”?而 RL 调优后的模型,却似乎拥有更强的“举一反三”能力?
过去,我们只能用“过拟合”这种笼统的词来解释。但今天,来自加州理工、伯克利等顶尖机构的研究团队,通过一项精细的“解剖手术”,将大模型的推理能力拆解为 5 个原子技能,终于揭开了 SFT 与 RL 在泛化能力上天壤之别的真相。
推理不是一块“铁板”,而是技能的“乐高”
我们常说的“推理能力”,其实是一个模糊的黑盒概念。为了搞清楚模型到底在想什么,研究团队提出了一个核心观点:推理不是单一的能力,而是多种“原子核心技能”的组合。
为了验证这一点,论文构建了一个全新的基准测试,将推理拆解为以下五大核心技能:
-
计算(Calculation):执行算术运算的能力。
-
事实检索(Fact Retrieval):调用特定领域知识(如物理公式)的能力。
-
模拟(Simulation):在脑海中推演过程(如滑块运动轨迹)的能力。
-
枚举(Enumeration):系统性地列举可能情况的能力。
-
诊断(Diagnostic):自我检查、发现矛盾并修正的能力。
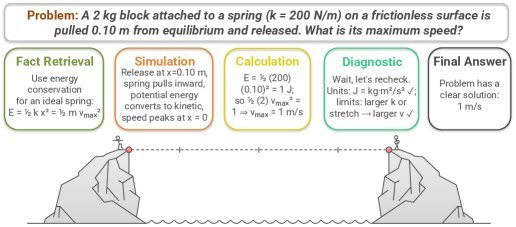
如上图所示,解决一个简单的“弹簧滑块”物理题,模型需要像搭乐高一样,按顺序调用检索、模拟、计算和诊断技能。任何一个环节掉链子,整个推理链条就会断裂。
SFT 的“偏科”与 RL 的“平衡”
基于这个框架,研究者们对比了 Qwen3-14B 模型在 SFT 和 RL 训练下的表现,结果令人震惊。
SFT 正在制造“偏科生”
SFT 模型(尤其是未使用思维链 CoT 的版本)表现出了极端的“偏科”。它们往往在 计算(Calculation) 技能上突飞猛进,但在 模拟(Simulation) 和 诊断(Diagnostic) 等需要深层理解的技能上却停滞不前,甚至出现退化。
这解释了为什么 SFT 模型容易“死记硬背”:它们过拟合了表面模式(比如看到数字就计算),却丢失了对问题本质的建模能力。
RL 才是“全能王”
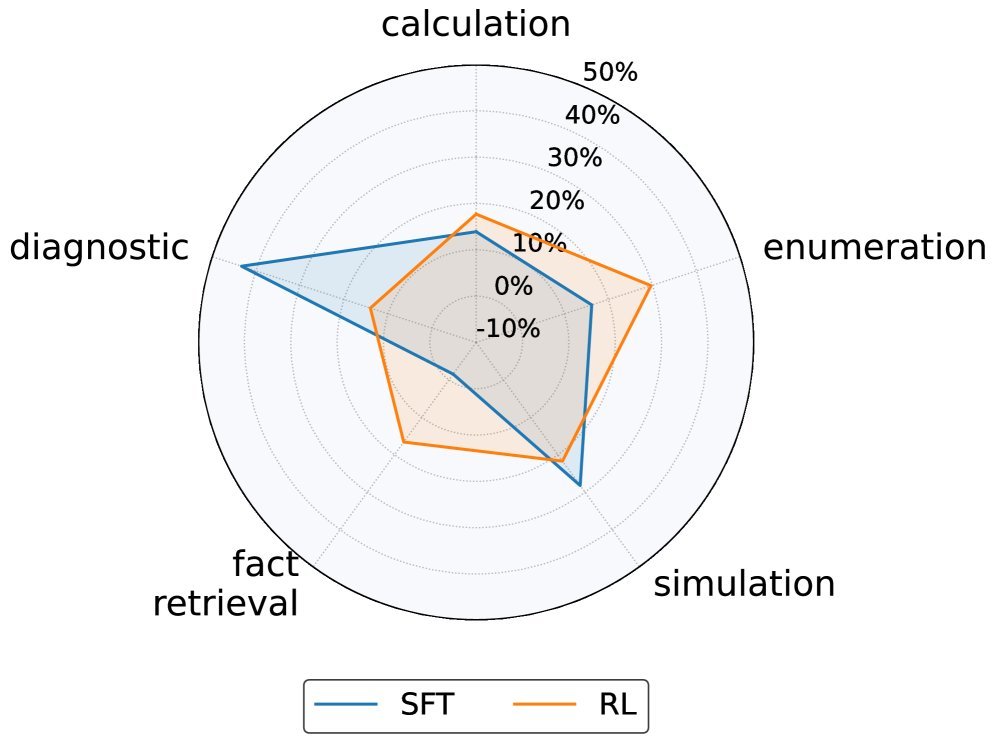
相比之下,RL 调优后的模型展现出了极佳的稳定性。请看下图的雷达图对比:
-
蓝色线条(SFT):形状尖锐、扭曲,说明技能发展极不平衡。
-
橙色线条(RL):形状饱满、圆润,几乎覆盖了所有技能维度。
研究发现,RL 通过奖励机制,迫使模型去探索更优的解题路径,从而保留了更均衡的技能组合。特别是在跨领域迁移(例如从数学训练迁移到非推理任务)时,RL 模型表现出了惊人的抗崩塌能力,而 SFT 模型则出现了严重的性能滑坡。
深入底层:大脑皮层的“重塑”
为了探究这种行为差异的物理本质,研究团队还深入到了模型的“神经元”层面,分析了参数分布和稀疏自编码器(SAE)的特征。
有趣的是,从参数更新的规模来看,SFT 和 RL 并没有显著差异(都更新了约 98% 的参数)。真正的区别在于“意图”而非“数量”。
-
SFT 倾向于让模型拟合特定的输出分布,导致模型内部的特征表示变得“尖锐”,过分关注某些表面特征。
-
RL 则通过奖励信号,优化了模型的决策边界,使其在保持底层特征多样性的同时,学会了如何更合理地调度这些特征。
总结与启示
这项研究给当下的 LLM 训练带来了两个关键启示:
-
不要迷信 SFT 的准确率:高准确率可能掩盖了模型在核心技能上的缺失。一个只会做计算题的模型,注定无法解决复杂的现实问题。
-
RL 是通往通用推理的钥匙:如果我们希望模型具备类似人类的“通用智能”,能够在不同领域间灵活迁移,那么基于强化学习的后训练(Post-training)不仅是提升分数的手段,更是维持认知技能平衡的必要保障。
未来的大模型之战,或许不再是比拼谁背的书多,而是比拼谁的“技能树”点得更平衡。